




 本文介绍了如何使用Python进行网页爬虫,以58同城网站为例,目标是获取二手市场中摩托卖场的链接。讲解了BeautifulSoup库的使用,以及urllib库的相关知识,包括Request和urlopen方法,同时也讨论了浏览器报文头信息的获取和伪造User-Agent的重要性。并提供了获取页面链接的代码示例。
本文介绍了如何使用Python进行网页爬虫,以58同城网站为例,目标是获取二手市场中摩托卖场的链接。讲解了BeautifulSoup库的使用,以及urllib库的相关知识,包括Request和urlopen方法,同时也讨论了浏览器报文头信息的获取和伪造User-Agent的重要性。并提供了获取页面链接的代码示例。
参考Python文档:http://python.usyiyi.cn/translate/python_352/library/index.html
1、以58同城网站为例:http://gz.58.com,先上波图:
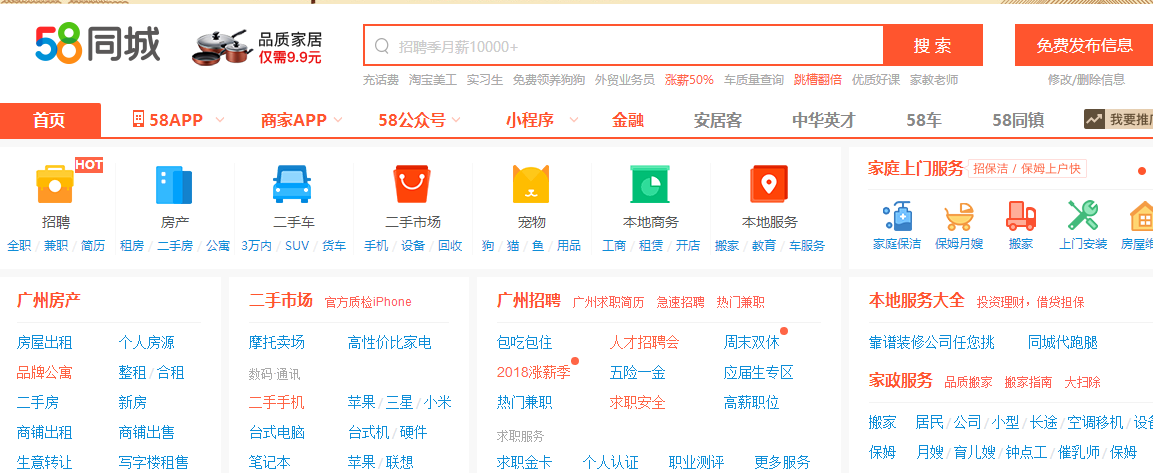
2.目标:搜索出二手市场中的页签【摩托卖场】的链接,查看源码结构:

3.确定出搜索目标为标签“a”
4.需要使用到的库为urllib、和BeautifulSoup
*****BeautifulSoup主要的功能是从网页抓取数据
*****推荐在现在的项目中使用Beautiful Soup 4,不过它已经被移植到BS4了,也就是说导入时我们需要 import bs4
*****安装方法:进入C:\Users\admin\AppData\Local\Programs\Python\Python36\Scripts,执行pip install beautifulsoup4
5.如何获取浏览器报文头信息
*****进入任意浏览器,点击F12,弹出控制台界面
*****点击Network,点击F5,此时下面会刷新出很多信息
*****点击任意一个信
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6555
6555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









