




概述
- HBase是基于hadoop的分布式的,可扩展的,能够存储大量的数据的菲关系型数据库
- 列存储思想–优势读取速度快 ; 容易扩展(RegionServer,HDFS)
- HBASE不支持SQL,没有主键;
- 存储的数据是稀疏的,适合存储结构化或者 半结构化的数据
- HDFS上的数据时不能修改的,HBase实现修改数据其实也是追加操作(更新完毕后 有一个时间戳作为版本信息)
- HBASE中的元数据包括:namespace,table .column-family,table-HRegion

部署结构
Hbase中有两种部署结构:Master RegionServer服务器
Mater服务器一般只有一个,RegionServer有多个服务器;Master 服务器负责维护表的结构信息 **实际的数据存储在RegionServer中(HDFS);即使Master挂掉集群也能查询数据,知识不能新建表了
基本概念
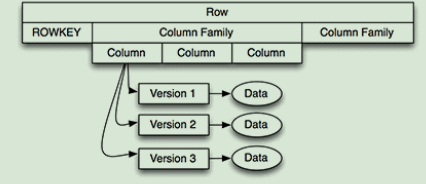
- 行键:Rowkey
- 类似于RDBMS中的主键
- 行键是在添加数据时指定的,而非创建时指定‘’
- 行键默认是按照字典排序
- ColumnFamily:列族(簇)
- 一个表中至少有一个列族(不限制数量,但列族不建议超过三个会影响效率)
- 列族也是在添加数据的时候动态增删的;而非创建表时指定
- Column :列
- 列是可以动态增删的 q
- 列从属于列族
- cell :单元
- 通过行键+列族+列+版本是锁定一条数据的唯一条件
- 默认只获取最后一个版本的cell
- namespace:名称空间
- 类似于数据库database
- 在实际的不同项目中对应不同的namespace
- 不指定默认为default
基本命令
- 建表:
- create ‘person’,{NAME =>‘basic’},{NAME => ‘info’} 或者简写 create ‘person’, ‘basic’,‘info’;
- 添加数据 name列 值为 ‘欧阳娜娜’
- put ‘person’ ,‘p1’,‘basic:name’,‘欧阳娜娜’;
- 获取数据
- get ‘person’ ,‘p1’; 获取行键为p1对应的值
- get ‘person’ ,‘p1’,{COLUMN => ‘basic’} 或者 get ‘person’,‘p1’ ,‘basic’; 获取行键p1,列族 basic对应的值
- get ‘person’ , ‘p1’ , ‘basic:age’
- 扫描person表
- scan ‘person’
- scan ‘person’, {COLUMNS => [‘basic’,‘info’]}
- 删除操作
- deleteall ‘person’ , ‘p1’;
- drop ‘person’
- 查看所有表 list
- 启用表:enable ‘student’;
- 指定每一个列族所能对外提供的历史版
本数量
create ‘person’, {NAME => ‘basic’,
VERSIONS => 3}, {NAME => ‘info’,
VERSIONS => 5} - 指定扫描的历史版本数量
- scan ‘person’, {COLUMNS => ‘basic’,
VERSIONS => 3}
- scan ‘person’, {COLUMNS => ‘basic’,
- create_namespace ‘hbasedemo’ 创建名称空间
create ‘hbasedemo:person’, ‘basic’,
‘info’; - list_namespace_tables ‘hbasedemo’ 查看指定名称空间下的表
- drop_namespace ‘hbasedemo’ 删除指定名称空间。要求这个名称空间
为空
基本理论
存储结构
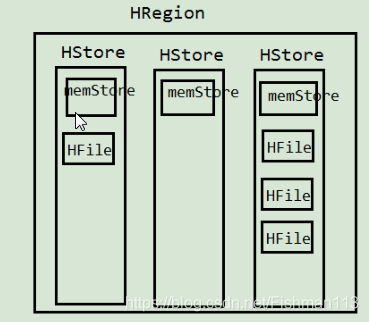
-
在行键方向上切分一个或多个HRegion,每一个都由HRgionServer来管理(标的增删改查)
-
由于行键是按照字典排序的,所以HRgion的范围是不交叉的
-
HMaster来监控HRegionServer,HRegionServer中可以包含多个Region 每个Region中包含不同的Store(是根据列族来划分的)
-
Store中有一个MemStore(内存存储,用来保存当前数据的才操作)和多个Hfile(实际的存储单位,最后存放到
-
HDFS中)
-
Zookeeper的作用
- zookeeper是HBASE整个架构中一个重要的角色,Hbase在第一次启动的时候回在ZK上注册一个持久节点/hbase
- ActiveMaster启动会在ZK注册一个临时节点/hbase/master;Backup Hmaster会注册一个临时子节点/hbase/backup-master
- ZK会监控/hbase/master, 当master宕机,会从Backup Hmater中挑选一个作为master;由于master是一个临时节点
所以宕机后会消失; - activeMaster会监控BackupMasters,确定给那个节点进行数据同步
- HRegionServer会在启动的时候注册临时子节点 /hbase/rs
-
HMaster
- 可以再任意一个节点中启动Hmaster
- 当出现多个HMaster的时候,HMaster的启动顺序决定了HMaster的状态:先
启动的HMaster是Active状态,后启动的HMaster就是Backup状态 - 虽然可以启动任意多个HMaster,实际过程中HMaster的个数不超过3个,因为
HMaster之间要进行数据的同步,当HMaster节点个数过多的时候,会影响执
行效率; - HMaster的职责
- 管理HRegionMaster
- 管理表结构(DDL)但是对于表的操作不经过HMaster
- Master通过心跳机制来维系在Zookeeper上的节点,心跳间隔默认是180s,
实际过程中会将这个事件缩短为10-30s;
-
HRegionServer和DataNode部署在相同的节点上
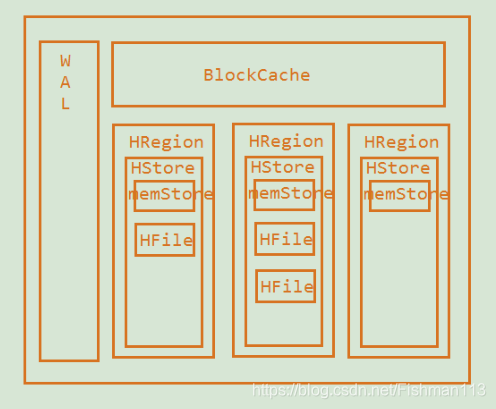
BlockCache:
BlockCache本质上是一个读缓存,这个读缓存是维系在内存中
- i.BlockCahe默认是128M大小
- ii.时间局部性:当一条数据被读取之后,那么HBase会认为这条数据被
再次读取的概率要大于其他未被读取数据的概率,那么这个时候
HBase会将这条数据缓存 - 读过的数据就会被缓存 - 1)空间局部性:当一条数据被读取之后,那么HBase会认为这条数据相
邻的数据被读取的概率比其他数据高,那么HBase会将这条数据相邻
的数据也进行缓存 - 2)读缓存在缓存的时候采用了"局部性"原理:
- iii.当读缓存用满之后,在清理数据的时候,采取了LRU策略
读写流程
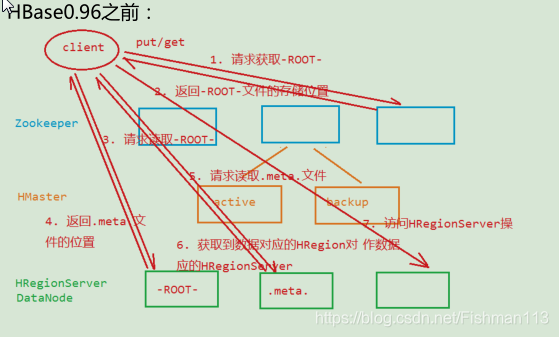
在HBase0.96开始:
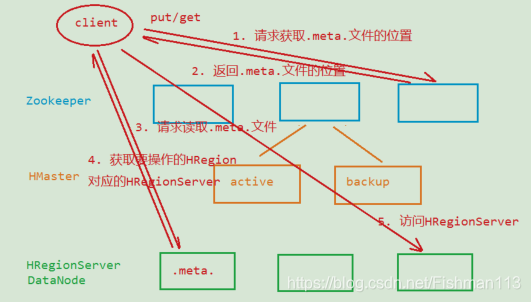
少了-ROOT-文件,减少了请求次数 ,当客户端读取.meta.文件之后会缓存.meta.文件中的内容缓存越多效率越高

















 1406
1406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









