




 本文深入探讨Hive作为基于Hadoop的数据仓库工具,如何通过类SQL语句简化大数据的存储、查询及分析,适用于离线处理场景。涵盖Hive的起源、特性、体系结构及其与传统RDBMS的对比。
本文深入探讨Hive作为基于Hadoop的数据仓库工具,如何通过类SQL语句简化大数据的存储、查询及分析,适用于离线处理场景。涵盖Hive的起源、特性、体系结构及其与传统RDBMS的对比。
Hive学习笔记
概述
由来
- 只能用java语言开发,如果是c语言或其他语言的程序员用Hadoop,存在语言门槛,需要对Hadoop底层原理,api比较了解才能做开发,开发调试比较麻烦;可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析Hive就是去解决该问题。
简介
- Hive是基于Hadoop的一个数据仓库工具。具有读写以及管理大量数据的能力。
- Hive使用的是类Sql语句,但是底层是基于SQL转化成MapReduce来执行的,所以效率很低,所以适合做离线处理;
- 可以用来对数据进行数据提取、转化、加载(ETL),是一种处理Hadoop中大规模数据的存储、查询以及数据分析机制;
- 类似于用来开发Sql类型脚本去执行MapReduce的作业。其本质是大数据离线分析工具;
与RDBMS相比
Hive存储的数据多样化:结构化、半结构化非结构化
数据来源多样;
传统数据库支持增删改查,Hive只提供曾和查的能力;
事务:Hive弱事务甚至没有事务
场景:RDBMS面向OLTP
HIve面向OLTP
体系结构
 用户接口
用户接口
- CLI:最常用的模式。实际上在>hive 命令行下操作时,就是利用CLI用户接口。
- JDBC:通过Java代码操作,需要先启动HiveServer然后连接操作。
Metastore
Hive将元数据存储在数据库中,如Mysql,Derby(单用户使用)。
元数据包括:表的列,分区及其属性(是否为外部表),表的数据所在目录等。
解释器(complier)、优化器(optimizer)、执行器(executor)组件
这三个组件用于:HQL语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成
的查询计划存储在HDFS中,并在随后有MapReduce调用执行
Hadoop
Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成
流程
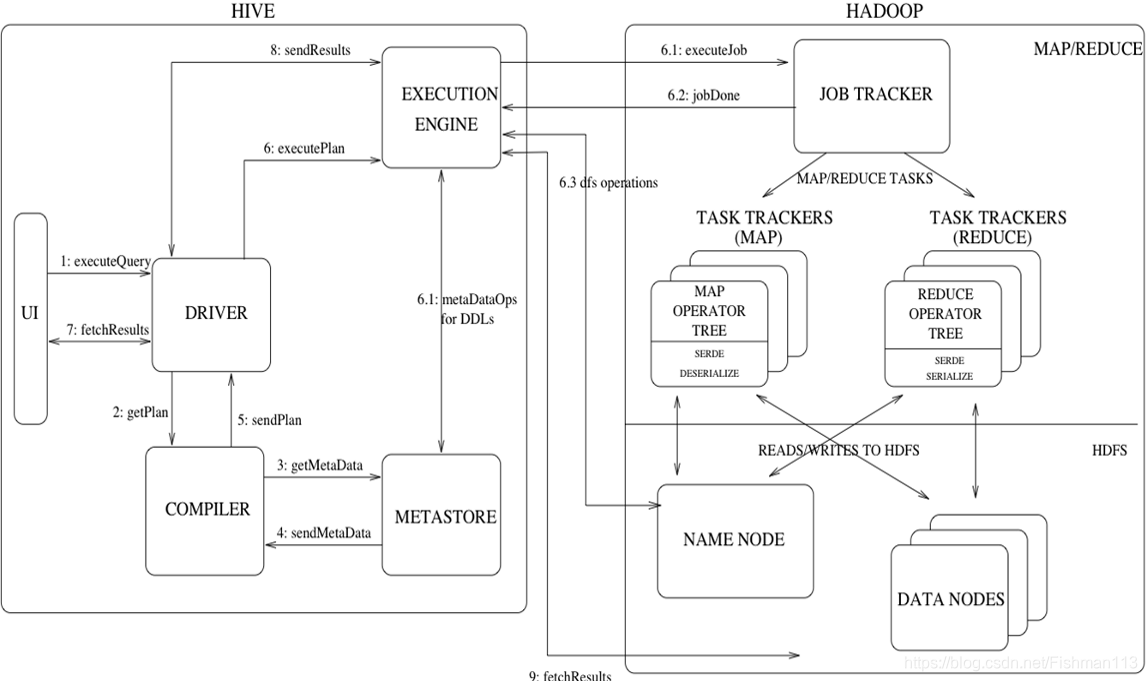
从图中可以看出:
- Hive在处理客户端命令的时候首先经过自身几个组件最后放入Hadoop中执行,完毕之后返回给客户端结果;
详细流程 - 客户端发送一条HQL语句
- 通过Driver去调度
- 将消息发送到Compiler:分析出hql要操作哪一张表;做出hql的解析;
- 去metastore中获取出元数据,返回给compiler;
- 在将解析后的hql(MapReduce),交给DRIVER
- ExecutionEngine接受Driver 的MapReduce;将MapReduce发送给hadoop中监控执行;剩下就是MapShuffle ReduceShuffle过程;
- 最后将处理的结果返回给ExecutionEngine;返回给driver–>返回给客户端;

















 2231
2231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









