



背景
希望离线看小说,但是又没有找到下载按钮,写个代码自己下载。
技术
使用jsoup+htmlunit的方式,因为jsoup是爬取静态网页,现在网页基本全是动态的,所以需要加入htmlunit。
PS:
动态加载网页的原理:传统的静态网页内容在服务器响应时已经完整生成,而动态加载的网页则通过 JavaScript 在客户端动态生成内容。这些内容可能通过以下几种方式实现:
- Ajax 请求:页面初始加载时,只加载基础框架,后续内容通过 JavaScript 发起 Ajax 请求,从服务器获取数据并动态渲染到页面上。
- 单页应用(SPA):如使用 Vue.js、React.js 等框架开发的网站,页面内容完全由 JavaScript 动态生成,每次用户操作都会触发 JavaScript 代码,从服务器获取数据并更新页面。
- WebSockets:通过实时通信技术动态更新页面内容,常见于实时数据展示场景。
代码原理
1.模拟浏览器获取页面数据。
2.解析页面数据,把小说内容获取到,读取到文本文件中。
思路一:
1)打开小说目录页面,按F12
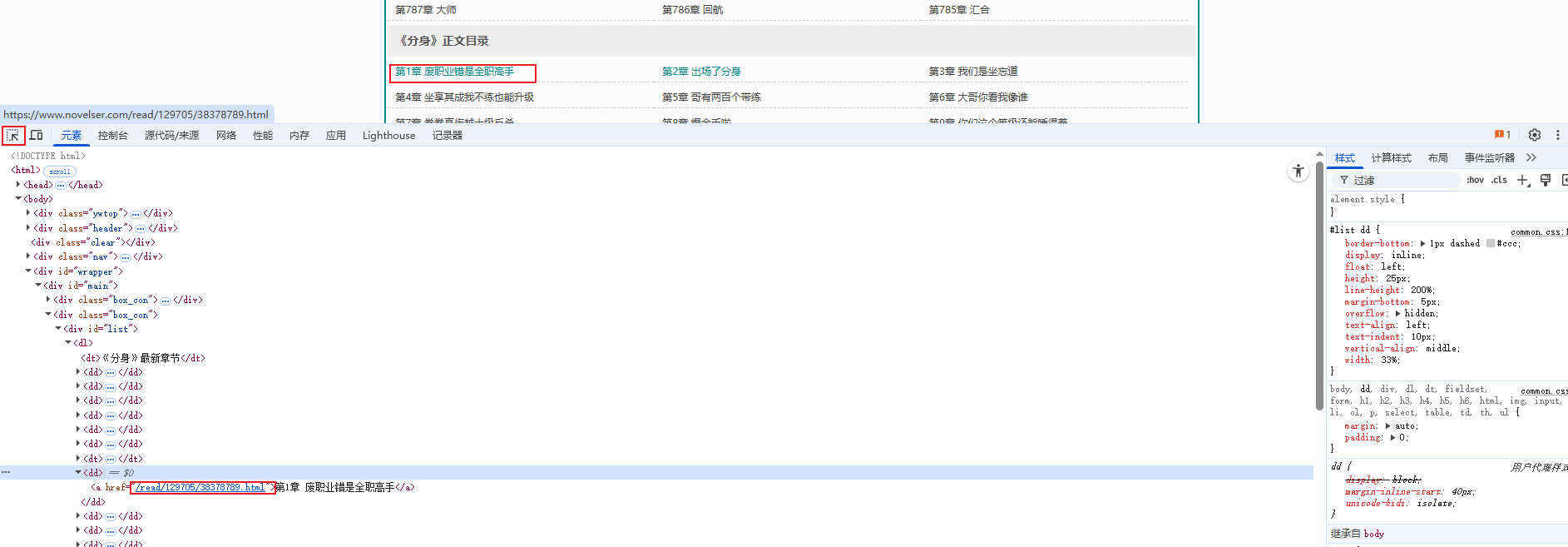
2)根据页面元素,获取每个章节对应的链接。
3)根据链接跳转到详情页面,获取详情页面的内容。
思路二:
直接找到第一章详情页面,根据下一页按钮,直到下载完整本书。下图红框标注的是“下一页”的元素位置。
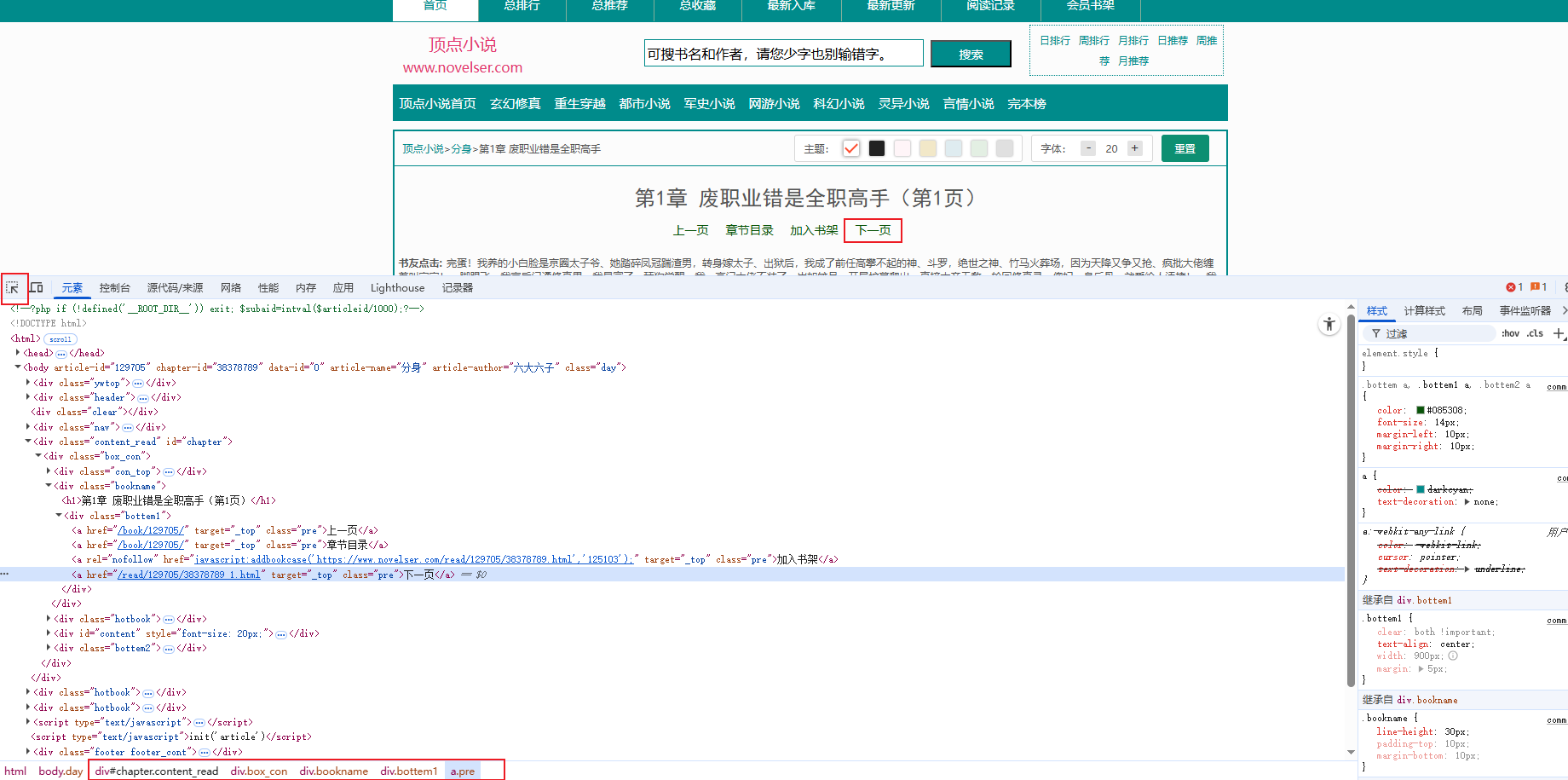
具体操作
第一步:导入marven库
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.4</version>
</dependency>
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.33</version>
</dependency>
第二步:代码
package test;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
import java.util.List;
import org.apache.commons.lang3.StringUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class App {
public static void main(String[] args) {
downloadNovel();
}
/**
* 获取下载小说
*/
public static void downloadNovel() {
//设置下载文件存放磁盘的位置
File file = new File("d:\\1");
//判断文件夹是否存在,不存在就创建
if (!file.exists()) {
file.mkdirs();
}
//在file目录下创建每一个章命名的txt文件
File f = new File(file, "1.txt");
//根据目录页面下载小说
/*String url = "https://www.novelser.com/book/129705/";
try {
Document document = getDocument(url);
Elements as = document.select("div#list dl dd a");
for (Element a : as) {
String href = a.attr("href");
String title = a.text();
save(out, url);
}
} catch (IOException e) {
e.printStackTrace();
}*/
try {
Writer out = new FileWriter(f);
//第一页url
String url = "/read/129705/38378789.html";
//根据第一章下载小说,由于可以从第一章一直点击下一页直到最后,所以用这个办法
save(out, url);
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public static Document getDocument(String url) {
Document document = null;
WebClient browser = new WebClient();
browser.getOptions().setCssEnabled(false);
browser.getOptions().setJavaScriptEnabled(true);
browser.getOptions().setThrowExceptionOnScriptError(false);
try {
HtmlPage htmlPage = browser.getPage(url);
browser.waitForBackgroundJavaScript(3000);
document = Jsoup.parse(htmlPage.asXml());
} catch (IOException e) {
e.printStackTrace();
}
return document;
}
private static void save(Writer out, String url) throws IOException {
url = "https://www.novelser.com"+url;
//伪装成为浏览器
Document doc = getDocument(url);
//获取标题
String title = doc.select("div#chapter.content_read div.box_con div.bookname h1").html();
//获取小说的正文
String content = doc.select("div#chapter.content_read div.box_con div#content p").html();
//处理特殊数据
content = content.replace("<br>", "");
content = content.replace(" ", "");
out.write(title);
out.write(content);
System.out.println("章节:"+title);
//需要使用休眠,为了防止网站检测为蓄意攻击,停止我们的IP访问
/*int n = (int) (Math.random() * 1000 + 100);
try {
Thread.sleep(n);
} catch (InterruptedException e) {
e.printStackTrace();
}*/
String nextUrl = getNextPage(doc);
if(StringUtils.isNotBlank(nextUrl)){
save(out, nextUrl);
}
}
public static String getNextPage(Document doc) {
String url = "";
Elements elements = doc.select("div#chapter.content_read div.box_con div.bottem2 a.pre");
List<String> list = elements.eachAttr("href");
if (elements.last().text().equals("下一页")){
url = list.get(list.size() - 1);
}
return url;
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









