




编译期处理
所谓的 语法糖 ,其实就是指 java 编译器把 *.java 源码编译为 *.class 字节码的过程中,自动生成和转换的一些代码,主要是为了减轻程序员的负担,算是 java 编译器给我们的一个额外福利(给糖吃嘛)
注意,以下代码的分析,借助了 javap 工具,idea 的反编译功能,idea 插件 jclasslib 等工具。另外,编译器转换的结果直接就是 class 字节码,只是为了便于阅读,给出了 几乎等价 的 java 源码方式,并不是编译器还会转换出中间的 java 源码,切记。
默认构造器
public class Candy1 {
}
编译成class后的等价代码:
public class Candy1 {
// 这个无参构造是编译器帮助我们加上的
public Candy1() {
super();
// 即调用父类 Object 的无参构造方法,即调用 java/lang/Object." <init>":()V
}
}
自动拆装箱
这个特性是 JDK 5 开始加入的, 代码片段1 :
public class Candy2 {
public static void main(String[] args) {
Integer x = 1;
int y = x;
}
}
这段代码在 JDK 5 之前是无法编译通过的,必须改写为 代码片段2 :
public class Candy2 {
public static void main(String[] args) {
Integer x = Integer.valueOf(1);
int y = x.intValue();
}
}
显然之前版本的代码太麻烦了,需要在基本类型和包装类型之间来回转换(尤其是集合类中操作的都是包装类型),因此这些转换的事情在 JDK 5 以后都由编译器在编译阶段完成。即代码片段1都会在编译阶段被转换为代码片段2
泛型集合取值
泛型也是在 JDK 5 开始加入的特性,但 java 在编译泛型代码后会执行 泛型擦除 的动作,即泛型信息在编译为字节码之后就丢失了,实际的类型都当做了 Object 类型来处理:
public class Candy3 {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(10); // 实际调用的是 List.add(Object e)
Integer x = list.get(0); // 实际调用的是 Object obj = List.get(int index);
}
}
所以在取值时,编译器真正生成的字节码中,还要额外做一个类型转换的操作:
// 需要将 Object 转为 Integer
Integer x = (Integer)list.get(0);
如果前面的 x 变量类型修改为 int 基本类型那么最终生成的字节码是:
// 需要将 Object 转为 Integer, 并执行拆箱操作
int x = ((Integer)list.get(0)).intValue();
还好这些麻烦事都不用自己做。
字节码
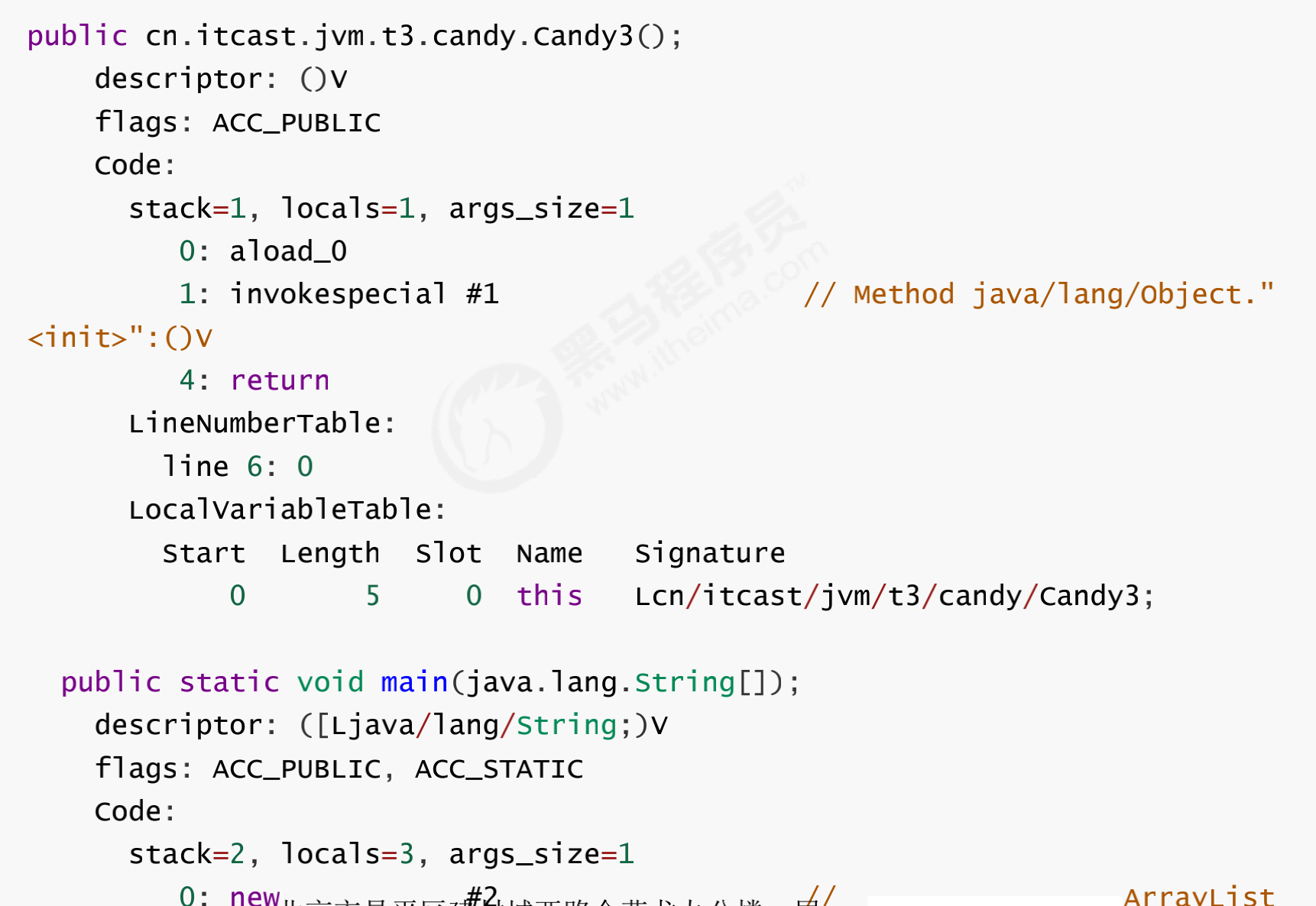

-
擦除的是字节码上的泛型信息,即本来转换成字节码时,字节码里应该是Integer类型,但是实际转换成字节码后,字节码里都是Object类型。
-
可以看到 LocalVariableTypeTable 仍然保留了方法参数泛型的信息(这样才能实现类型转换)
使用反射,仍然能够获得这些信息:
public Set<Integer> test(List<String> list, Map<Integer, Object> map) {
}
Method test = Candy3.class.getMethod("test", List.class, Map.class);
Type[] types = test.getGenericParameterTypes();
for (Type type : types) {
if (type instanceof ParameterizedType) {
ParameterizedType parameterizedType = (ParameterizedType) type;
System.out.println("原始类型 - " + parameterizedType.getRawType());
Type[] arguments = parameterizedType.getActualTypeArguments();
for (int i = 0; i < arguments.length; i++) {
System.out.printf("泛型参数[%d] - %s\n", i, arguments[i]);
}
}
}
输出

可变参数
可变参数也是 JDK 5 开始加入的新特性: 例如:
public class Candy4 {
public static void foo(String... args) {
String[] array = args; // 直接赋值
System.out.println(array);
}
public static void main(String[] args) {
foo("hello", "world");
}
}
可变参数 String… args 其实是一个 String[] args ,从代码中的赋值语句中就可以看出来。 同样 java 编译器会在编译期间将上述代码变换为:
public class Candy4 {
public static void foo(String[] args) {
String[] array = args; // 直接赋值
System.out.println(array);
}
public static void main(String[] args) {
foo(new String[]{"hello", "world"});
}
}
注意
如果调用了 foo() 则等价代码为 foo(new String[]{}) ,创建了一个空的数组,而不会
传递 null 进去
foreach循环
仍是 JDK 5 开始引入的语法糖
数组的循环:
public class Candy5_1 {
public static void main(String[] args) {
int[] array = {1, 2, 3, 4, 5}; // 数组赋初值的简化写法也是语法糖哦
for (int e : array) {
System.out.println(e);
}
}
}
会被编译器转换为:
public class Candy5_1 {
public Candy5_1() {
}
public static void main(String[] args) {
int[] array = new int[]{1, 2, 3, 4, 5};
for(int i = 0; i < array.length; ++i) {
int e = array[i];
System.out.println(e);
}
}
}
集合的循环
public class Candy5_2 {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1,2,3,4,5);
for (Integer i : list) {
System.out.println(i);
}
}
}
实际被编译器转换为对迭代器的调用:
public class Candy5_2 {
public Candy5_2() {
}
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Iterator iter = list.iterator();
while(iter.hasNext()) {
Integer e = (Integer)iter.next();
System.out.println(e);
}
}
}
注意 foreach 循环写法,能够配合数组,以及所有实现了 Iterable 接口的集合类一起使用,其中 Iterable 用来获取集合的迭代器( Iterator )
switch
switch-String
从 JDK 7 开始,switch 可以作用于字符串和枚举类,这个功能其实也是语法糖,例如:
public class Candy6_1 {
public static void choose(String str) {
switch (str) {
case "hello": {
System.out.println("h");
break;
}
case "world": {
System.out.println("w");
break;
}
}
}
}
注意 switch 配合 String 和枚举使用时,变量不能为null,原因分析完语法糖转换后的代码应当自然清楚
public class Candy6_1 {
public Candy6_1() {
}
public static void choose(String str) {
byte x = -1;
switch(str.hashCode()) {
case 99162322: // hello 的 hashCode
if (str.equals("hello")) {
x = 0;
}
break;
case 113318802: // world 的 hashCode
if (str.equals("world")) {
x = 1;
}
}
switch(x) {
case 0:
System.out.println("h"); break;
case 1:
System.out.println("w");
}
}
}
可以看到,执行了两遍 switch,第一遍是根据字符串的 hashCode 和 equals 将字符串的转换为相应byte 类型,第二遍才是利用 byte 执行进行比较。
为什么第一遍时必须既比较 hashCode,又利用 equals 比较呢?hashCode 是为了提高效率,减少可能的比较;而 equals 是为了防止 hashCode 冲突,例如 BM 和 C. 这两个字符串的hashCode值都是2123 ,如果有如下代码:
public class Candy6_2 {
public static void choose(String str) {
switch (str) {
case "BM": {
System.out.println("h");
break;
}
case "C.": {
System.out.println("w");
break;
}
}
}
}
会被编译器转换为:
public class Candy6_2 {
public Candy6_2() {
}
public static void choose(String str) {
byte x = -1;
switch(str.hashCode()) {
case 2123: // hashCode 值可能相同,需要进一步用 equals 比较
if (str.equals("C.")) {
x = 1;
} else if (str.equals("BM")) {
x = 0;
}
default:
switch(x) {
case 0:
System.out.println("h");
break;
case 1:
System.out.println("w");
}
}
}
}
switch-Enum
switch 枚举的例子,原始代码:
enum Sex {
MALE, FEMALE
}
public class Candy7 {
public static void foo(Sex sex) {
switch (sex) {
case MALE:
System.out.println("男"); break;
case FEMALE:
System.out.println("女"); break;
}
}
}
转换后代码:
public class Candy7 {
/*** 定义一个合成类(仅 jvm 使用,对我们不可见)
* 用来映射枚举的 ordinal 与数组元素的关系
* 枚举的 ordinal 表示枚举对象的序号,从 0 开始
* 即 MALE 的 ordinal()=0,FEMALE 的 ordinal()=1
*/
static class $MAP {
// 数组大小即为枚举元素个数,里面存储case用来对比的数字
static int[] map = new int[2];
static {
map[Sex.MALE.ordinal()] = 1;
map[Sex.FEMALE.ordinal()] = 2;
}
}
public static void foo(Sex sex) {
int x = $MAP.map[sex.ordinal()];
switch (x) {
case 1:
System.out.println("男");
break;
case 2:
System.out.println("女");
break;
}
}
}
枚举类
JDK 7 新增了枚举类,以前面的性别枚举为例:
enum Sex {
MALE, FEMALE
}
转换后代码:
public final class Sex extends Enum<Sex> {
public static final Sex MALE;
public static final Sex FEMALE;
private static final Sex[] $VALUES;
static {
MALE = new Sex("MALE", 0);
FEMALE = new Sex("FEMALE", 1);
$VALUES = new Sex[]{MALE, FEMALE};
}
/*** Sole constructor. Programmers cannot invoke this constructor.
* It is for use by code emitted by the compiler in response to
* enum type declarations.
*
* @param name - The name of this enum constant, which is the identifier
* used to declare it.
* @param ordinal - The ordinal of this enumeration constant (its position
* in the enum declaration, where the initial constant is assigned
*/
private Sex(String name, int ordinal) {
super(name, ordinal);
}
public static Sex[] values() {
return $VALUES.clone();
}
public static Sex valueOf(String name) {
return Enum.valueOf(Sex.class, name);
}
}
try-with-resources
JDK 7 开始新增了对需要关闭的资源处理的特殊语法 try-with-resources:
try(资源变量 = 创建资源对象){
} catch( ) {
}
其中资源对象需要实现 AutoCloseable 接口,例如 InputStream 、 OutputStream 、 Connection 、 Statement 、 ResultSet 等接口都实现了 AutoCloseable ,使用 try-with- resources 可以不用写 finally 语句块,编译器会帮助生成关闭资源代码,例如:
public class Candy9 {
public static void main(String[] args) {
try(InputStream is = new FileInputStream("d:\\1.txt")) {
System.out.println(is);
} catch (IOException e) {
e.printStackTrace();
}
}
}
会被转换为:
public class Candy9 {
public Candy9() {
}
public static void main(String[] args) {
try {
InputStream is = new FileInputStream("d:\\1.txt");
Throwable t = null;
try {
System.out.println(is);
} catch (Throwable e1) {
// t 是我们代码出现的异常
t = e1;
throw e1;
} finally {
// 判断了资源不为空
if (is != null) {
// 如果我们代码有异常
if (t != null) {
try {is.close();
} catch (Throwable e2) {
// 如果 close 出现异常,作为被压制异常添加
t.addSuppressed(e2);
}
} else {
// 如果我们代码没有异常,close 出现的异常就是最后 catch 块中的 e
is.close();
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
为什么要设计一个 addSuppressed(Throwable e) (添加被压制异常)的方法呢?是为了防止异常信息的丢失(想想 try-with-resources 生成的 fifianlly 中如果抛出了异常):
public class Test6 {
public static void main(String[] args) {
try (MyResource resource = new MyResource()) {
int i = 1/0;
} catch (Exception e) {
e.printStackTrace();
}
}
}
class MyResource implements AutoCloseable {
public void close() throws Exception {
throw new Exception("close 异常");
}
}
输出
java.lang.ArithmeticException: / by zero
at test.Test6.main(Test6.java:7)
Suppressed: java.lang.Exception: close 异常
at test.MyResource.close(Test6.java:18)
at test.Test6.main(Test6.java:6)
如以上代码所示,两个异常信息都不会丢。
方法重写时的桥接方法
我们都知道,方法重写时对返回值分两种情况:
-
父子类的返回值完全一致
-
子类返回值可以是父类返回值的子类(比较绕口,见下面的例子)
class A {
public Number m() {
return 1;
}
}
class B extends A {
@Override
// 子类 m 方法的返回值是 Integer 是父类 m 方法返回值 Number 的子类
public Integer m() {
return 2;
}
}
对于子类,java 编译器会做如下处理:
class B extends A {
public Integer m() {
return 2;
}
// 此方法才是真正重写了父类 public Number m() 方法
public synthetic bridge Number m() {
// 调用 public Integer m()
return m();
}
}
其中桥接方法比较特殊,仅对 java 虚拟机可见,并且与原来的 public Integer m() 没有命名冲突(标注了synthetic bridge),可以用下面反射代码来验证:
for (Method m : B.class.getDeclaredMethods()) {
System.out.println(m);
}
会输出
public java.lang.Integer test.candy.B.m()
public java.lang.Number test.candy.B.m()
匿名内部类
源代码:
public class Candy11 {
public static void main(String[] args) {
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("ok");
}
};
}
}
转换后代码:
// 额外生成的类
final class Candy11$1 implements Runnable {
Candy11$1() {
}
public void run() {
System.out.println("ok");
}
}
public class Candy11 {
public static void main(String[] args) {
Runnable runnable = new Candy11$1();
}
}
引用局部变量的匿名内部类,源代码:
public class Candy11 {
public static void test(final int x) {
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("ok:" + x);
}
};
}
}
转换后代码:
// 额外生成的类
final class Candy11$1 implements Runnable {
int val$x;
Candy11$1(int x) {
this.val$x = x;
}
public void run() {
System.out.println("ok:" + this.val$x);
}
}
public class Candy11 {
public static void test(final int x) {
Runnable runnable = new Candy11$1(x);
}
}
注意 这同时解释了为什么匿名内部类引用局部变量时,局部变量必须是 final 的:
因为在创建Candy11$1 对象时,将 x 的值赋值给了 Candy111对象的val属性, 所以x不应该再发生变化了,如果变化,那么x属性没有机会再跟着一起变化

















 3358
3358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









