



前言
从text获取信息的方式
词向量和预训练
为什么选择text-to-text
有利用统一,作者认为“能够比较不同迁移学习方法的有效性”
“影响迁移学习的因素”
Transfer learning objectives(迁移学习目标函数)
Unlabeled datasets(无标签数据集)
Other factors
实验
Baseline
标准transformer(2017)
验证集分数
 架构对比
架构对比
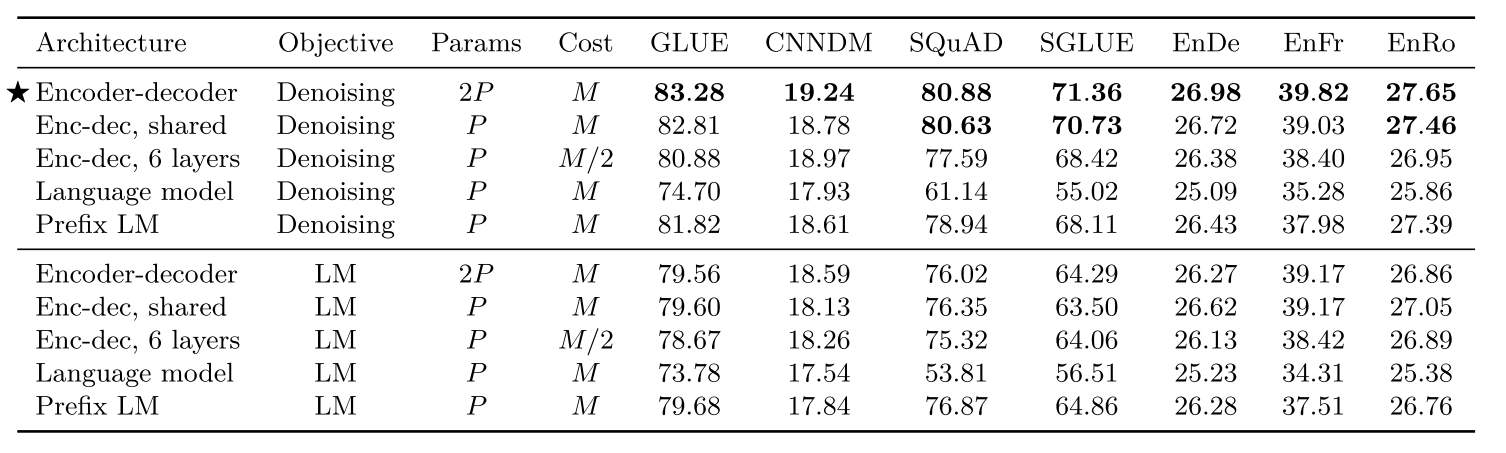
无监督目标对比
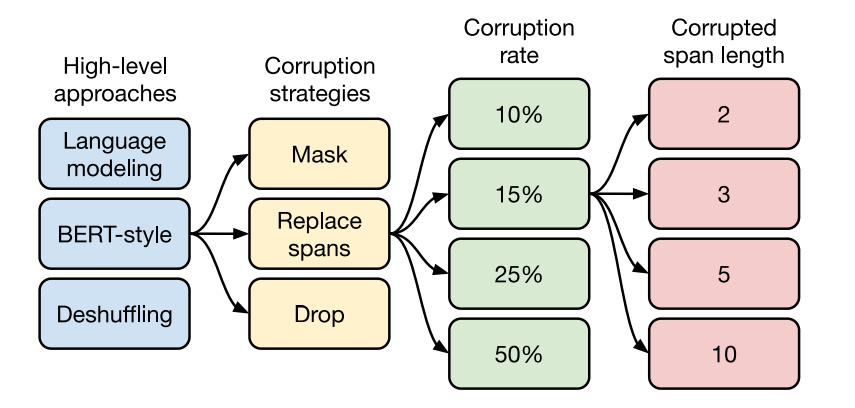
重点在后一个图,使用BERT-style的破坏方式较为有效,主要对比不同破坏策略
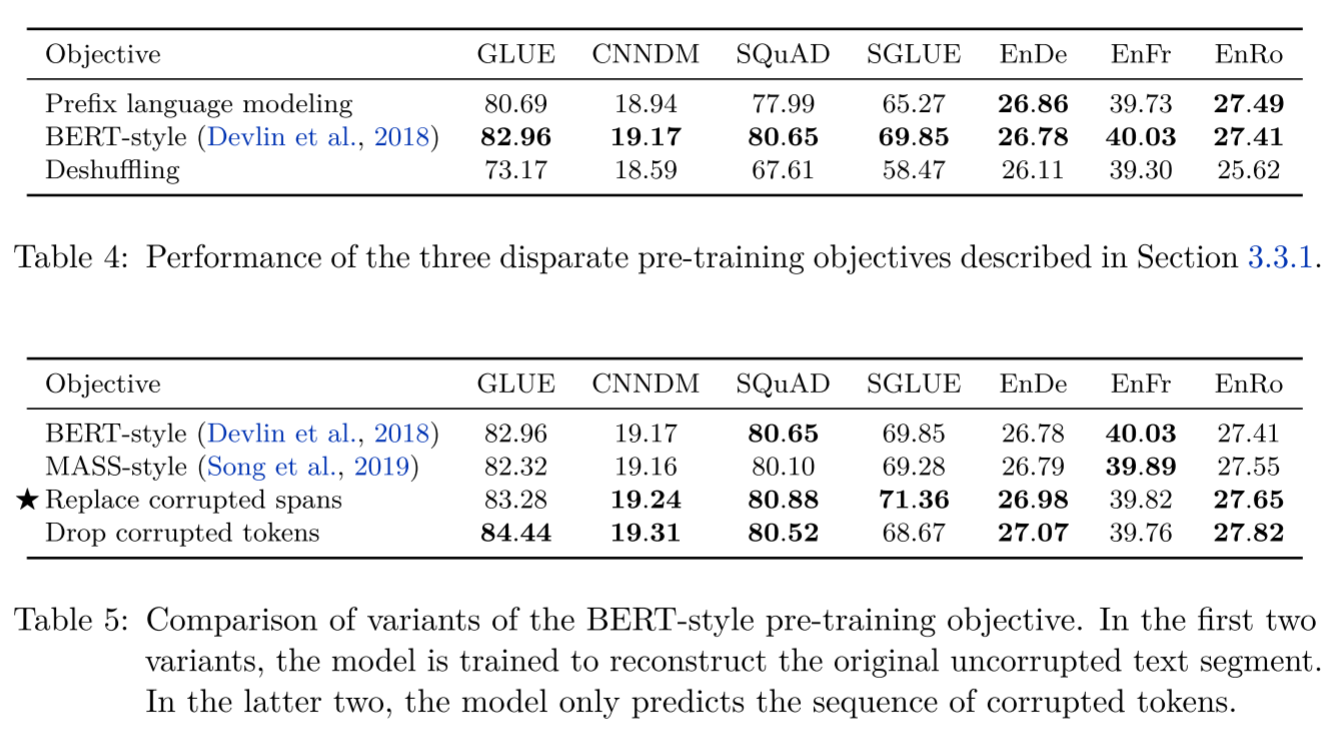 破坏程度对比
破坏程度对比
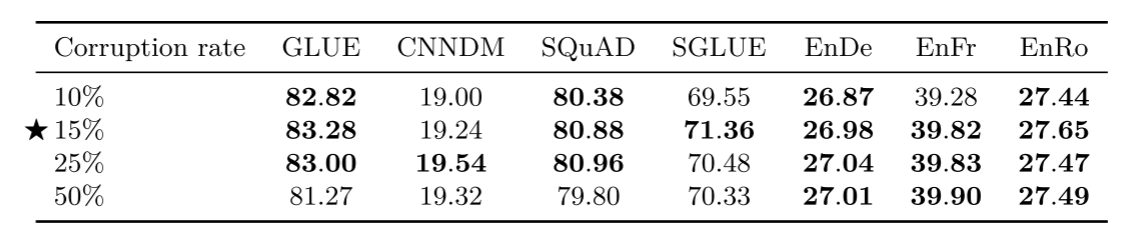
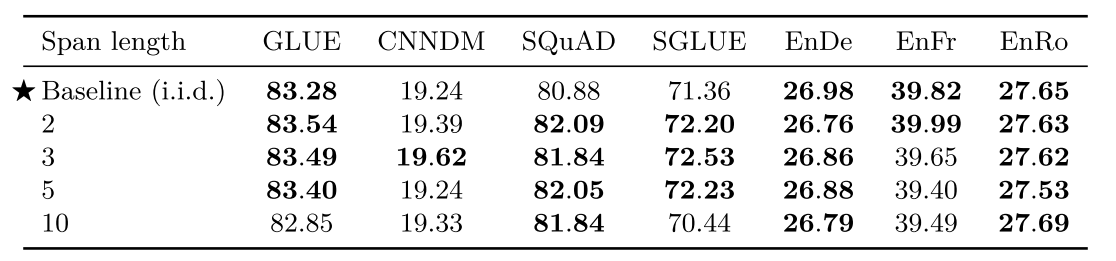
小结
以上几个对比的思路
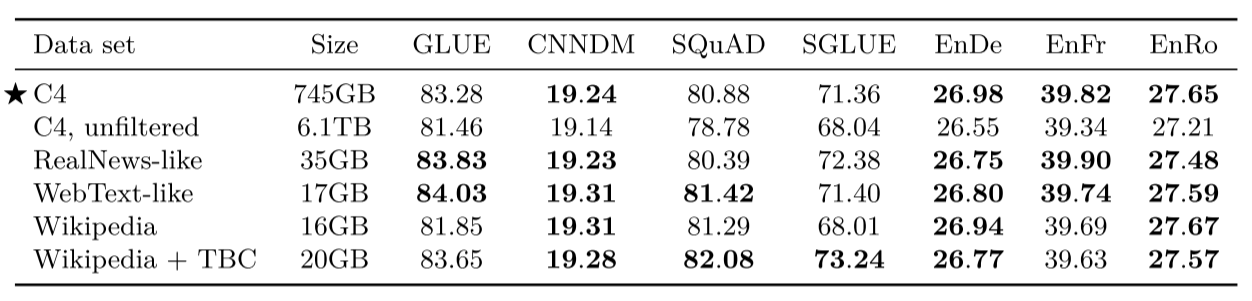
无标注数据集对比
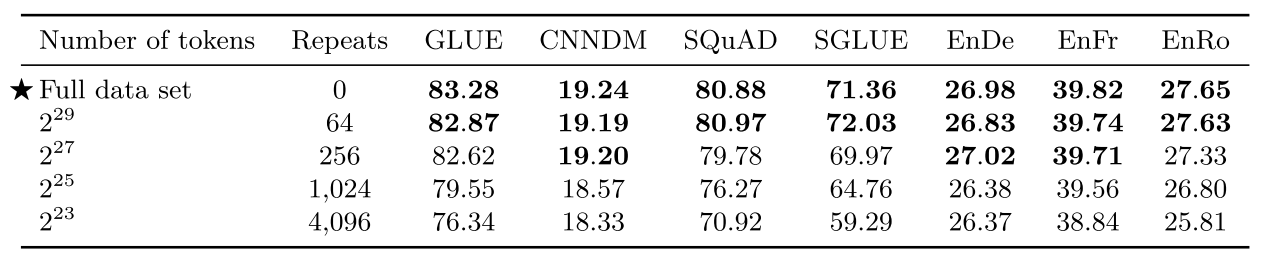
 数据集大小对比
数据集大小对比
 训练策略
训练策略
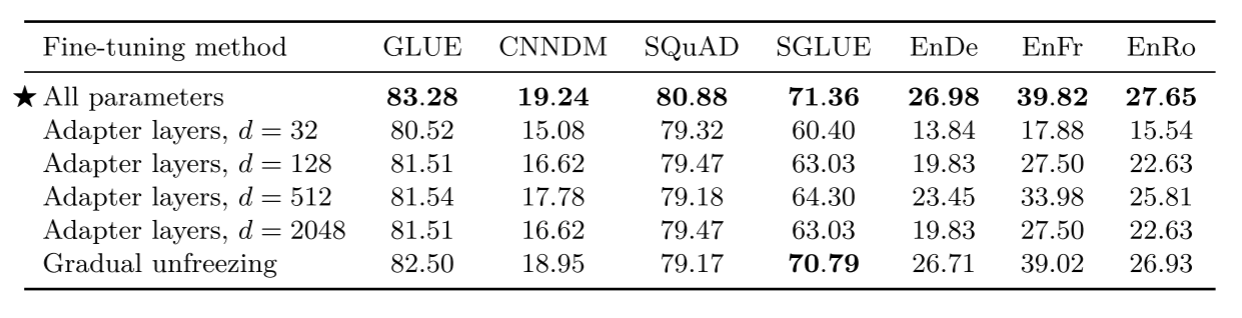
微调方法
早期研究认为在低资源任务中微调一个模型头更好。但这个方法在t5不适用,只能使用另外两个微调方法,adapter layers(适配器层)和gradual unfreezing(渐进解冻)
 多任务学习
多任务学习
对于t5,最直接的方式就是数据集混合,以下是不同混合方式的对比
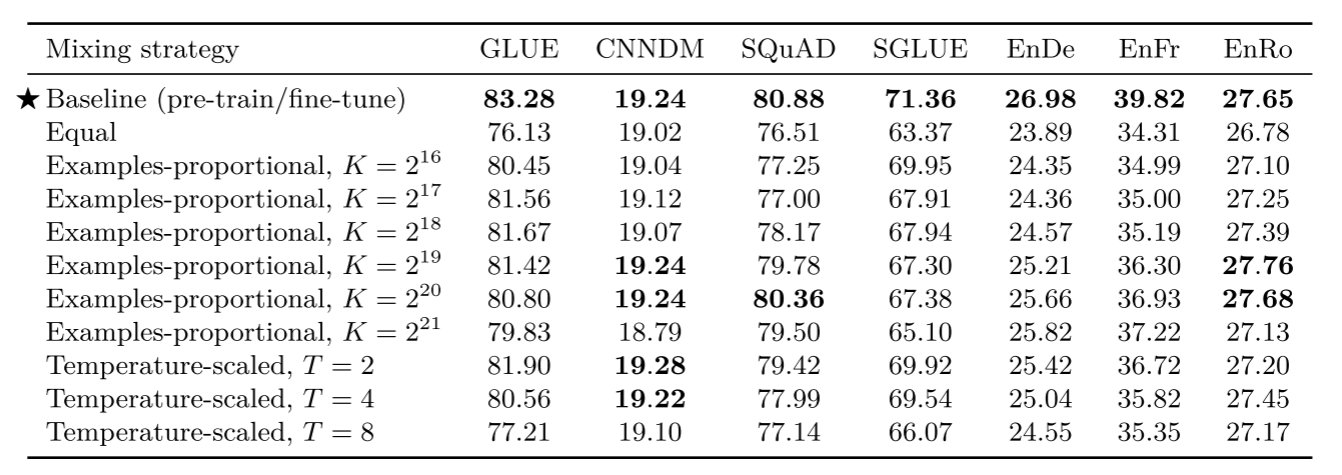
可以注意到temperature-scaled在大多数任务中获得合理性能,特别当T=2时在大多数情况最佳
将多任务学习和微调结合

将多任务学习加入预训练中并不能提高模型在几乎所有下游任务的表现,只有机器翻译是例外,作者认为这表明了机器翻译在预训练中收获很小,但在其他任务是重要因素。(此处未引用参考文献,这里的预训练应该是指无监督的预训练)
个人浅见,这句话不是很严谨,对比完全没有预训练的模型,有预训练的模型在机器翻译中明显更优,所以预训练对于机器翻译来说也很重要。只能说因为多任务中有多种语言翻译,用其他语言翻译作预训练同样有利于迁移学习,故而再加上无监督预训练可能效果不佳。
规模化
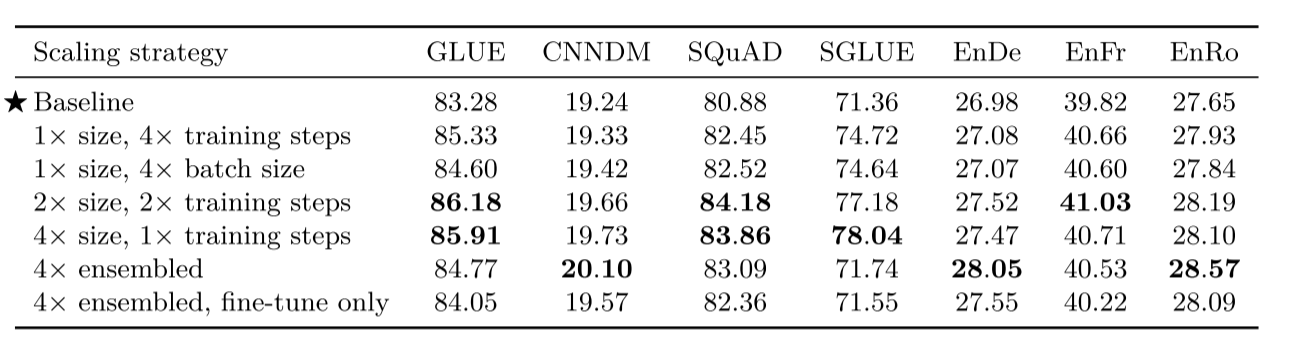
将所有东西结合


















 2141
2141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









