




DataSet
1、DataSet是什么?
DataSet是分布式的数据集合,DataSet提供了强类型支持,也是在RDD的每行数据加了类型约束。
DataSet是在Spark1.6中添加的新的接口。
它集中了RDD的优点(强类型和可以用强大lambda函数)以及使用了Spark SQL优化的执行引擎。
可以通过JVM的对象进行构建DataSet。
DataSet可以用函数式的转换(map/flatmap/filter)进行多种操作。
2、DataFrame与DataSet的区别
DataSet包含了DataFrame的功能,Spark2.0中两者统一,DataFrame表示为DataSet[Row],即DataSet的子集。
DataSet可以在编译时检查类型
DataSet是面向对象的编程接口
3、DataFrame与DataSet互相转换
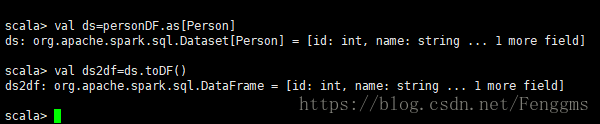
DataFrame转为 DataSet
df.as[ElementType] 这样可以把DataFrame转化为DataSet。
val ds=personDF.as[Person]
DataSet转为DataFrame
ds.toDF() 这样可以把DataSet转化为DataFrame。
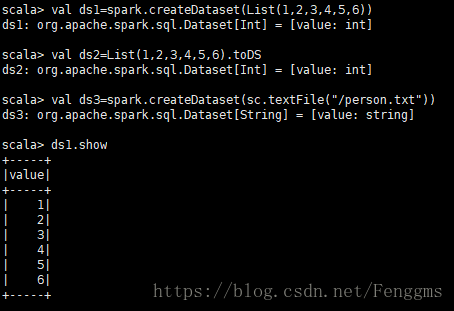
4、DataSet的创建
从一个已经存在的scala集合来构建
val ds1=spark.createDataset(List(1,2,3,4,5,6))
val ds2=List(1,2,3,4,5,6).toDS
从一个已经存在的rdd中来构建
val ds3=spark.createDataset(sc.textFile("/person.txt"))
通过dataFrame转换生成
dataSet=dataFrame.as[强类型]
Dataset相关方法

















 2884
2884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









