



记录一次查询优化
在写代码过程中,由于开发时间或者人员原因,会经常遇到刚开始开发的功能运行很快,随着数据量增加,查询会越来越慢,就要学会优化代码,这里记录一次优化SQL的过程,先看原先查询:
SELECT t.id,t.orderNo,t.FMaterialID_FNumber,t.FMaterialID_FName,t.num,t.preStartDate,f.flowName,t.dipStatus lineState ,l.lineBodyName,t.lineBodyId2,a.startTime
,t.dipStartDate,t.dipEndDate
FROM `ORDER` t LEFT JOIN FLOW f ON t.flowId = f.id
LEFT JOIN (select max(startTime) startTime,orderId from production GROUP BY orderId)a ON t.id = a.orderId,qb_line_body l
WHERE t.deleteFlag = 0 AND t.preType = 0 AND t.lineBodyId2 = l.id AND t.typeProduce in( 'DIP','SMT&DIP') AND t.dipStatus NOT IN ('完工','结束','待备料');
通过调试,最后定位到了慢的SQL
select max(startTime) startTime,orderId
from production
GROUP BY orderId
通过EXPLAIN分析一下
| id | select_type | table | parttions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | production | index | index_orderId,index_group | index_orderId | 5 | 471282 | 100.00 |
执行时间为:
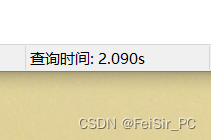
索引是走了的,但是走的不对,这条SQL是全表扫描,肯定是很慢的,因为需要查找到最新的添加时间,上面的慢SQL是查找最新的时间,然后根据工单id分组,查询很慢,优化的思想是,既然id最大的,就是最新的插入时间(因为业务逻辑是我写的),就先查询出来最新的id然后根据工单id进行分组,然后将查询出来的数据关联自身,优化后的SQL是这样的
select p.startTime,p.orderId
from production p,(select max(id) id
from production
GROUP BY orderId) p2
where p.id = p2.id
分析一下SQL的执行效率
| id | select_type | table | parttions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | <derived2> | ALL | 55 | 100.00 | Using where | |||||
| 1 | PRIMARY | p | eq_ref | PRIMARY | PRIMARY | 4 | p2.id | 1 | 10.00 | Using where | |
| 2 | DERIVED | production | range | index_orderId,index_group | index_orderId | 5 | 55 | 100.00 | Using index for group-by |
可以看到,rows变少了,速度也快了很多
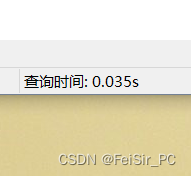
到这里,优化完成,是一个很小的优化,结合数据表设计业务逻辑,优化很简单,其实最重要的是在Java代码里面有循环,当然,循环的影响不是很大,一次查库十毫秒,循环一百次才一秒还能接受,毕竟表头不需要太多,也就几百条,主要是查询表头的数据的地方慢了,后续的SQL肯定不是这样的,肯定要重写把嵌套循环去掉的,直接把报表详情一条SQL查出来,这样才能最大限度优化效率。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











