




 本文详细介绍了Python中的字符串、列表和元组操作,包括创建、赋值、转义符、基本特征、内建方法等。讨论了字符串的连接、成员、索引和切片,以及常用方法如类型转换、开头和结尾判断、数据清洗等。同时,还涵盖了列表的创建、特征、常用方法和练习题目,以及元组的创建和操作。文章还对比了浅拷贝和深拷贝的区别,并给出了小学生计算能力测试系统的实现代码。
本文详细介绍了Python中的字符串、列表和元组操作,包括创建、赋值、转义符、基本特征、内建方法等。讨论了字符串的连接、成员、索引和切片,以及常用方法如类型转换、开头和结尾判断、数据清洗等。同时,还涵盖了列表的创建、特征、常用方法和练习题目,以及元组的创建和操作。文章还对比了浅拷贝和深拷贝的区别,并给出了小学生计算能力测试系统的实现代码。
文章目录
- 字符串str:单引号,双引号,三引号引起来的字符信息。
- 数组array:存储同种数据类型的数据结构。[1, 2, 3], [1.1, 2.2, 3.3]
- 列表list:打了激素的数组, 可以存储不同数据类型的数据结构. [1, 1.1, 2.1, ‘hello’]
- 元组tuple:带了紧箍咒的列表, 和列表的唯一区别是不能增删改。
- 集合set:不重复且无序的。 (交集和并集)
- 字典dict:{“name”:“westos”, “age”:10}
1. 字符串str
内容简介:
创建
- 单引号引起来:
name = 'westos' - 双引号引起来:
name = "westos" - 三引号引起来:
注意点: 三引号代表字符串, 也可以作为代码的块注释
基本特性
- 连接(+)重复(*)
- 成员(in, not in)
- 索引: 正向索引和反向索引
- 切片:s[start🔚step]
s = '012345'
print(s[:3]) # s[:n]获取前n个字符
print(s[2:]) # s[n:]获取除了qiann个字符的字符串信息
print(s[::-1]) # 字符串倒序
常用方法
- 判断类型(isdigit, isupper, islower, isalpha, isalnum)
- 转换类型:(lower, upper, title)
- 开头和结尾的判断(startswith, endswith)
- 数据清洗(strip, lstrip, rstrip, replace)
- 分割和拼接(split,
'172.25.254.100'.split("."), join) - 位置调整(center)
1.1字符串的创建和赋值
字符串或串(String)是由数字、字母、下划线组成的一串字符。Python 里面最常见的类型。 可以简单地通过在引号间(单引号,双引号和三引号)包含字符的方式创建它。
创建方式:
1.str1 = 'our company is westos'
2.str2 = "our company is westos"
3.用三引号引起,适用于较长字符串
a = '''
--------------------------test--------------------------
'''
1.2转义符
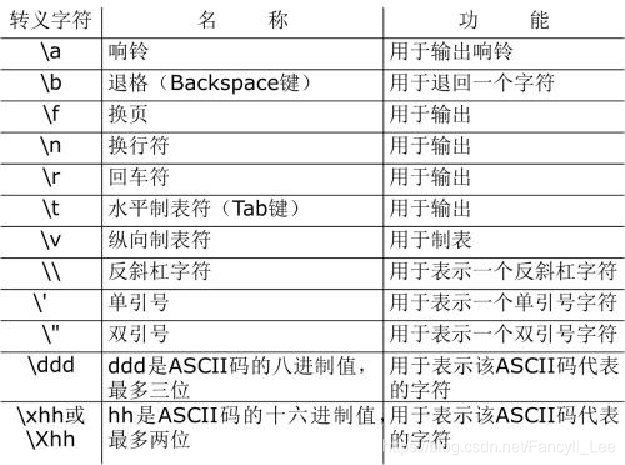
1.3字符串的基本特征
1.连接操作符和重置操作符
name = 'westos'
print('hello ' + name)
# 1元 + 1分 = 1元 + 0.01元 = 1.01元
print('hello' + str(1))
print("*" * 30 + '学生管理系统' + '*' * 30)

2.成员操作符
s = 'hello westos'
print('westos' in s) # True
print('westos' not in s) # False
print('x' in s) # False

3. 正向索引和反向索引
s = 'WESTOS'
print(s[0]) # 'W'
print(s[3]) # 'T'
print(s[-3]) # 'T'

4. 切片
回顾:
range(3):[0, 1, 2]
range(1, 4): [1, 2, 3]
range(1, 6, 2): [1, 3, 5]
切片: 切除一部分的内容
s[start:end:step]
s[:end]:
s[start:]:
总结:
s[:n]: 拿出前n个元素
s[n:]: 除了前n个元素, 其他元素保留
s[:]:从头开始访问一直到字符串结束的位置
s[::-1]: 倒序输出
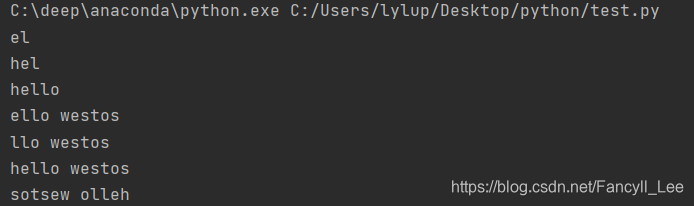
s = 'hello westos'
print(s[1:3]) # 'el'
print(s[:3]) # 'hel'
print(s[:5]) # 拿出字符串的前5个字符
print(s[1:]) # 'ello westos'
print(s[2:]) # 'llo westos'
print(s[:]) # 拷贝字符串
print(s[::-1])
5. for循环访问
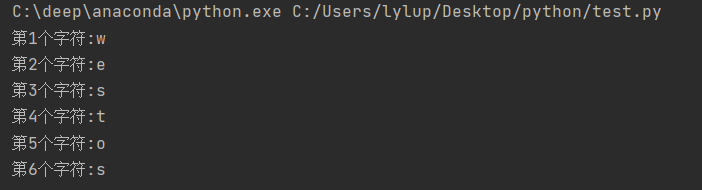
s = 'westos'
count = 0
for item in s:
count += 1
print(f"第{count}个字符:{item}")
练习:判断是否回文字符串
s = input('输入字符串:')
result = "回文字符串" if s == s[::-1] else "不是回文字符串"
print(s + "是" + result)

1.4字符串的内建方法
1.字符串的判断和转换
s = ‘HelloWESTOS’
print(s.isalnum()) # True
print(s.isdigit()) # Flase
print(s.isupper()) # False

2. 类型的转换
print(‘hello’.upper())
print(‘HellO’.lower())
print(‘HellO WOrld’.title())
print(‘HellO WOrld’.capitalize())
print(‘HellO WOrld’.swapcase())

需求: 用户输入Y或者y都继续继续代码
yum install httpd
choice = input('是否继续安装程序(y|Y):')
if choice.lower() == 'y':
print("正在安装程序......")
3.字符串开头结尾的判断
#startswith
url = 'http://www.baidu.com'
if url.startswith('http'):
#具体实现爬虫,感兴趣的话可以看request模块。
print(f'{url}是一个正确的网址,可以爬取网站的代码')

#endswith:
# 常用的场景: 判断文件的类型
filename = 'hello.png'
if filename.endswith('.png'):
print(f'{filename} 是图片文件')
elif filename.endswith('mp3'):
print(f'{filename}是音乐文件')
else:
print(f'{filename}是未知文件')

4.字符串的数据清洗
数据清洗的思路:
lstrip: 删除字符串左边的空格(指广义的空格: \n, \t, ’ ')
rstrip: 删除字符串右边的空格(指广义的空格: \n, \t, ’ ')
strip: 删除字符串左边和右边的空格(指广义的空格: \n, \t, ’ ')
replace: 替换函数, 删除中间的空格, 将空格替换为空。replace(" ", )
>>> " hello ".strip()
'hello'
>>> " hello ".lstrip()
'hello '
>>> " hello ".rstrip()
' hello'
>>> " hel lo ".replace(" ", "")
'hello'
5.字符串的位置调整
>>> "学生管理系统".center(50)
' 学生管理系统 '
>>> "学生管理系统".center(50, "*")
'**********************学生管理系统**********************'
>>> "学生管理系统".center(50, "-")
'----------------------学生管理系统----------------------'
>>> "学生管理系统".ljust(50, "-")
'学生管理系统--------------------------------------------'
>>> "学生管理系统".rjust(50, "-")
'--------------------------------------------学生管理系统'
>>>
6.字符串的搜索和统计
>>> s = "hello westos"
>>> s.find("llo")
2
>>> s.index("llo")
2
>>> s.find("xxx")
-1
>>> s.index("xxx")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
find如果找到子串, 则返回子串开始的索引位置。 否则返回-1
index如果找到子串,则返回子串开始的索引位置。否则报错(抛出异常).
>>> s.count("xxx")
0
>>> s.count("l")
2
>>> s.count("o")
2
7.字符串的分离和拼接
需求:IP地址的合法性-将ip的每一位数字拿出, 判断每位数字是否在0-255之间。
ip = "172.25.254.100"
>>> ip.split('.')
['172', '25', '254', '100']
>>> items = ip.split('.')
>>> items
['172', '25', '254', '100']
>>> # 拼接
>>> items
['172', '25', '254', '100']
需求: 将四个数字用’-'拼接起来
>>> "-".join(items)
'172-25-254-100'
8.练习:随机生成验证码
需求: 生成100个验证码, 每个验证码由2个数字和2个字母组成
import random
import string
for i in range(100):
print("".join(random.sample(string.digits, 2)) + "".join(random.sample(string.ascii_letters, 4)))
string模块可调出数字和字母;
random.sample传入待选字符串和随机挑选的个数
join将字符串拼接
1.5小学生计算能力测试系统
设计一个程序,用来实现帮助小学生进行算术运算练习,
它具有以下功能:
提供基本算术运算(加减乘)的题目,每道题中的操作数是随机产生的,
练习者根据显示的题目输入自己的答案,程序自动判断输入的答案是否正确
并显示出相应的信息。最后显示正确率。
import random
count = 10
right_count = 0
for i in range(count):
num1 = random.randint(1, 10)
num2 = random.randint(1, 10)
symbol = random.choice(["+", "-", "*"])
if symbol == "+":
result = num1 + num2
elif symbol == "-":
result = num1 - num2
elif symbol == "*":
result = num1 * num2
question = f"{num1} {symbol} {num2} = ?"
print(question)
user_answer = int(input("Answer:"))
if user_answer == result:
print("Right")
right_count += 1
else:
print("Error")
print("Right percent: %.2f%%" %(right_count/count*100))

改进版:
import random
count = 10
right_count = 0
for i in range(count):
num1 = random.randint(1, 10)
num2 = random.randint(1, 10)
symbol = random.choice(["+", "-", "*"])
result = eval(f"{num1}{symbol}{num2}")
question = f"{num1} {symbol} {num2} = ?"
print(question)
user_answer = int(input("Answer:"))
if user_answer == result:
print("Right")
right_count += 1
else:
print("Error")
print("Right percent: %.2f%%" %(right_count/count*100))
2. 列表List
数组只能存放同一种数据,列表可以存放多种数据
li1 = [1, 2, 3, 4]
print(li1, type(li1))
li2 = [1, 2.4, True, 2e+5, [1, 2, 3]]
print(li2, type(li2))

2.1列表的创建
li = []
print(li, type(li))
li1 = [1]
print(li1, type(li1))

注:单数字不是列表,列表的主要标志是"[]"
2.2列表的基本特征
1.连接操作符和重复操作符
print([1, 2] + [2, 3]) # [1, 2, 2, 3]
print([1, 2] * 3) # [1, 2, 1, 2, 1, 2]

2. 成员操作符(in, not in)
布尔类型:
True: 1
False:0
print(1 in [1, 2, 3]) # True
print(1 in ["a", False, [1, 2]]) # False
3. 索引
li = [1, 2, 3, [1, 'b', 3]]
print(li[0]) # 1
print(li[-1]) # [1, 'b', 3]
print(li[-1][0]) # 1 二次索引
print(li[3][-1]) # 3
4. 切片
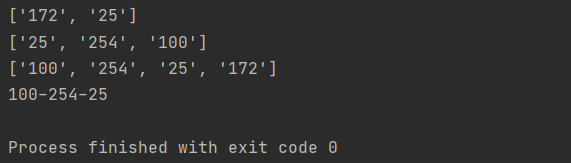
li = ['172', '25', '254', '100']
print(li[:2])
print(li[1:])
print(li[::-1])
#需求: 已知['172', '25', '254', '100'], 输出: "100-254-25"
li = ['172', '25', '254', '100']
print("-".join(li[1:][::-1]))
5. for循环
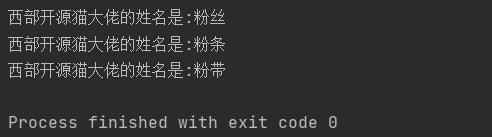
names = ["粉丝", '粉条', '粉带']
for name in names:
print(f"西部开源猫大佬的姓名是:{name}")
2.2列表的常用方法
1.增加
1-1.追加
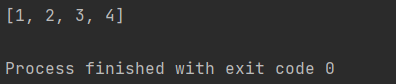
li = [1, 2, 3]
li.append(4)
print(li)
1-2.在列表开头添加
li = [1, 2, 3]
li.insert(0, 'cat')
print(li)

1-3.在索引2前面添加元素cat
li = [1, 2, 3]
li.insert(2, 'cat')
print(li)

1-4.一次追加多个元素
li = [1, 2, 3] # 添加4, 5, 6
li.extend([4, 5, 6])
print(li)

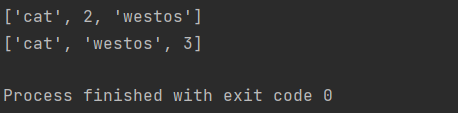
2. 修改: 通过索引和切片重新赋值的方式
li = [1, 2, 3]
li[0] = 'cat'
li[-1] = 'westos'
print(li)
li = [1, 2, 3]
li[:2] = ['cat', 'westos']
print(li)
3. 查看: 通过索引和切片查看元素。 查看索引值和出现次数
li = [1, 2, 3, 1, 1, 3]
print(li.count(1)) # 3
print(li.index(3)) # 2
4. 删除
4-1.根据索引删除
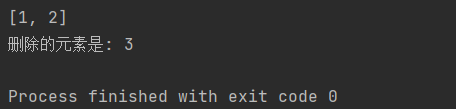
将pop方法的结果存储到delete_num变量中。
li = [1, 2, 3]
delete_num = li.pop(-1)
print(li)
print("删除的元素是:", delete_num)
4-2.根据value值删除
li = [1, 2, 3]
li.remove(1)
print(li)

4-3.全部清空
li = [1, 2, 3]
li.clear()
print(li)

其他操作
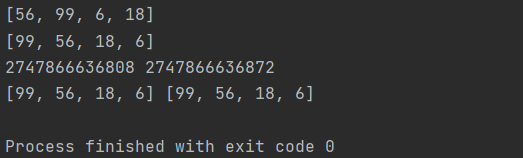
li = [18, 6, 99, 56]
li.reverse() # 类似于li[::-1]
print(li)
#sort排序默认由小到大。 如果想由大到小排序,设置reverse=True
li.sort(reverse=True)
print(li)
li1 = li.copy()
print(id(li), id(li1))
print(li, li1)
2.3列表的练习题目
编写一个云主机管理系统:
- 添加云主机(IP, hostname,IDC)
- 搜索云主机(顺序查找)
- 删除云主机
- 查看所有的云主机信息
from collections import namedtuple
menu = """
云主机管理系统
1). 添加云主机
2). 搜索云主机(IP搜索)
3). 删除云主机
4). 云主机列表
5). 退出系统
请输入你的选择: """
#思考1. 所有的云主机信息如何存储?选择哪种数据类型存储呢? 选择列表
#思考2: 每个云主机信息该如何存储?IP, hostname,IDC 选择命名元组
hosts = []
Host = namedtuple('Host', ('ip', 'hostname', 'idc'))
while True:
choice = input(menu)
if choice == '1':
print('添加云主机'.center(50, '*'))
ip = input("ip:")
hostname = input("hostname:")
idc = input('idc(eg:ali,huawei..):')
host1 = Host(ip, hostname, idc)
hosts.append(host1)
print(f"添加{idc}的云主机成功.IP地址为{ip}")
elif choice == '2':
print('搜索云主机'.center(50, '*'))
# 今天的作业: for循环(for...else),判断, break
elif choice == '3':
print('删除云主机'.center(50, '*'))
# 今天的作业:(选做)
elif choice == '4':
print('云主机列表'.center(50, '*'))
print("IP\t\t\thostname\tidc")
count = 0
for host in hosts:
count += 1
print(f'{host.ip}\t{host.hostname}\t{host.idc}')
print('云主机总个数为', count)
elif choice == '5':
print("系统正在退出,欢迎下次使用......")
exit()
else:
print("请输入正确的选项")
2.4地址引用和深拷贝和浅拷贝
1. 值的引用
nums1 = [1, 2, 3]
nums2 = nums1
nums1.append(4)
print(nums2) # 1, 2, 3, 4

2. 拷贝:浅拷贝和深拷贝
2-1. 浅拷贝
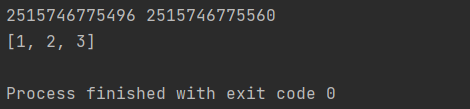
n1 = [1, 2, 3]
n2 = n1.copy() # n1.copy和n1[:]都可以实现拷贝。
print(id(n1), id(n2))
n1.append(4) #字符串指向的内存空间没变
print(n2)
2-2.深拷贝
可变数据类型(可增删改的): list
不可变数据类型:数值,str, tuple, namedtuple
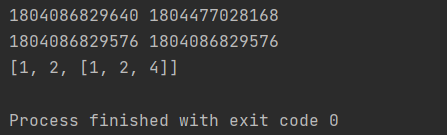
n1 = [1, 2, [1, 2]]
n2 = n1.copy()
#n1和n2的内存地址:的确拷贝了
print(id(n1), id(n2))
#n1[-1]和n2[-1]的内存地址:
print(id(n1[-1]), id(n2[-1]))
n1[-1].append(4)
print(n2)
注:如果有列表嵌套的时候,或者列表中包含可变数据类型时,拷贝一定要选择深拷贝
深拷贝和浅拷贝最根本的区别在于是否真正获取一个对象的复制体,而不是引用。
- 假设B复制了A,修改了A的时候,看B是否发生了变化
- 如果B跟着也变了,寿命是浅拷贝;
- 如果B没有改变,说明是深拷贝
2-3.实现深拷贝
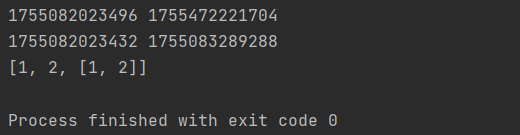
import copy
n1 = [1, 2, [1, 2]]
n2 = copy.deepcopy(n1)
print(id(n1), id(n2))
print(id(n1[-1]), id(n2[-1]))
n1[-1].append(4)
print(n2)
问题: 深拷贝和浅拷贝的区别?/python中如何拷贝一个对象?
赋值: 创建了对象的一个新的引用,修改其中任意一个变量都会影响到另一个。(=)
浅拷贝: 对另外一个变量的内存地址的拷贝,这两个变量指向同一个内存地址的变量值。(li.copy(), copy.copy())
- 公用一个值;
- 这两个变量的内存地址一样;
- 对其中一个变量的值改变,另外一个变量的值也会改变;
深拷贝: 一个变量对另外一个变量的值拷贝。(copy.deepcopy())
- 两个变量的内存地址不同;
- 两个变量各有自己的值,且互不影响;
- 对其任意一个变量的值的改变不会影响另外一个;
3. 元组tuple
#易错点: 如果元组只有一个元素,一定要加逗号。
t1 = (1, 2.4, True, 2e+5, [1, 2, 3])
print(t1, type(t1))
t2 = (1,)
print(t2, type(t2))
t3 = (1)
print(t3,type(t3))

3.1元组的操作
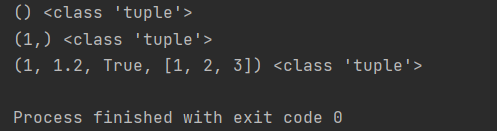
1.元组的创建
t1 = () # 空元组
print(t1, type(t1))
t2 = (1,) # 重要(易错点):元组只有一个元素时一定要加逗号
print(t2, type(t2))
t3 = (1, 1.2, True, [1, 2, 3])
print(t3, type(t3))
2. 特性
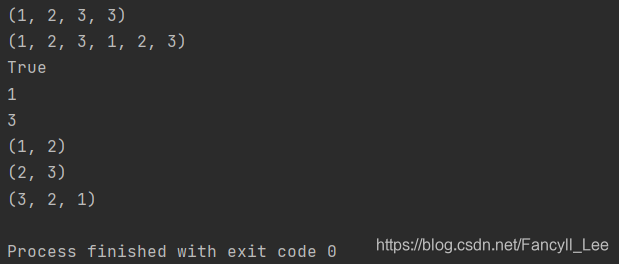
print((1, 2, 3) + (3,))
print((1, 2, 3) * 2)
print(1 in (1, 2, 3))
t = (1, 2, 3)
print(t[0])
print(t[-1])
print(t[:2])
print(t[1:])
print(t[::-1])
3. 常用方法: 元组是不可变数据类型(不能增删改)
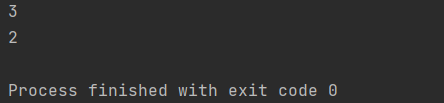
#查看: 通过索引和切片查看元素。 查看索引值和出现次数。
t = (1, 2, 3, 1, 1, 3)
print(t.count(1)) # 3
print(t.index(3)) # 2
3.2命名元组的操作
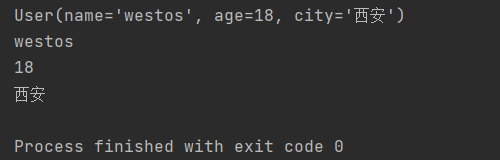
tuple = ("westos", 18, "西安")
print(tuple[0], tuple[1], tuple[2])
从collections模块中导入namedtuple工具。
from collections import namedtuple
#1. 创建命名元组对象User
User = namedtuple('User', ('name', 'age', 'city'))
# 2. 给命名元组传值
user1 = User("westos", 18, "西安")
# 3. 打印命名元组
print(user1)
# 4. 获取命名元组指定的信息
print(user1.name)
print(user1.age)
print(user1.city)
3.3is和==的区别
python语言:
==: 类型和值是否相等
is: 类型和值是否相等, 内存地址是否相等
print(1 == '1') # False
li = [1, 2, 3]
li1 = li.copy()
print(li == li1) # True
查看内存地址
print(id(li), id(li1))
print(li is li1) # False

















 1197
1197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









