






转截请注明出处: fair-jm.iteye.com
额 有段时间不写文了
这个说是简单爬虫 其实连个爬虫也算不上吧 功能太精简了...
流程很简单: 输入几个初始的网页 然后通过JSOUP获取网页中的a标签的href的值
接着把新得到的地址放入任务队列中
实现中的worker是一个单线程的派发器 用于产生Parser
Parser用于完成网页的保存 网页的解析 以及入队列操作
内容很简单 也没有使用数据库
任务队列直接用了一个Queue
已完成地址和正在处理的地址的保存用了List
具体代码如下:
package com.cc.crawler.infrastructure;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Random;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.RejectedExecutionException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Worker {
//保存地址 这里保存在G盘的html文件夹内
public static final String SAVED_FOLDER = "G:\\html\\";
private BlockingQueue<String> taskQueue = new LinkedBlockingQueue<String>(
10000); // 任务队列 最大100000
private List<String> finished = Collections
.synchronizedList(new ArrayList<String>()); // 存放已经完成处理的地址的列表
private List<String> processing = Collections
.synchronizedList(new ArrayList<String>()); // 存放正在处理中的地址的列表
private ExecutorService savedExector = Executors.newFixedThreadPool(100); // 100个文件保存队列
private ExecutorService parserExector = Executors.newFixedThreadPool(100); // 最大100的线程池
// 用来做解析工作
private volatile boolean stop = false;
public Worker() {
}
public void addStartAddress(String address) {
try {
taskQueue.put(address); // 使用阻塞的put方式
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/**
* 启动 这边是一个单线程的派发任务 内容很简单 不断地从任务队列里取值 判断是否处理过 没有的话就处理
*/
public void start() {
while (!stop) {
String task;
try {
task = taskQueue.take();
if (filter(task)) { // 这边是过路任务的 过滤条件自己写
continue;
}
// System.out.println("start():"+task);
processing.add(task); // 正在处理的任务
parserExector.execute(new Parser(task));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 立即关闭写和读的任务
parserExector.shutdownNow();
savedExector.shutdownNow();
}
public void stop() {
stop = true;
}
/**
*
* @param task 是否过滤的网址
* @return true 表示过滤 false 表示不过滤
*/
public boolean filter(String task) {
if (finished.contains(task) || processing.contains(task)) {
return true;
}
if (finished.contains(task + "/") || processing.contains(task + "/")) {
return true;
}
if(task.contains("#")){
String uri=task.substring(0,task.indexOf("#"));
if (finished.contains(uri) || processing.contains(uri)) {
return true;
}
}
return false;
// else {
// int in = task.indexOf("?");
// if (in > 0)
// contains = finished.contains(task.substring(0, in));
// }
}
/**
* 进行解析的工具
*
* @author cc fair-jm
*
*/
class Parser implements Runnable {
private final String url;
public Parser(String url) {
if (!url.toLowerCase().startsWith("http")) {
url = "http://" + url;
}
this.url = url;
}
@Override
public void run() {
try {
Document doc = Jsoup.connect(url).get();
String uri = doc.baseUri();
try {
savedExector.execute(new Saver(doc.html(), uri)); // 先进行存储
} catch (RejectedExecutionException ex) { // 产生了这个异常说明保存线程池已经关掉了
// 那么后续的工作就不要做了
// 这边可以再保存一下状态
return;
}
Elements es = doc.select("a[href]");
for (Element e : es) {
String href = e.attr("href");
// System.out.println("worker run():"+href);
if (href.length() > 1) {
if (href.startsWith("/")) {
href = doc + href;
if(href.endsWith("/")){
href=href.substring(0,href.length()-1);
}
}
if (href.startsWith("http") && !filter(href)) {
try {
taskQueue.put(href); // 堵塞的放入
} catch (java.lang.InterruptedException ex) {
System.out.println(href + ":任务中止");
return; // 后续的href也不再进行
}
}
}
}
// System.out.println("parser:"+url+" 完成");
finished.add(url); // 在这边说明这个url已经完成了
} catch (Exception e) {
e.printStackTrace();
} finally {
processing.remove(url); // 把正在处理的任务移除掉(不管是否成功完成)
}
}
}
/**
* 用于文件保存的线程
*
* @author cc fair-jm
*
*/
class Saver implements Runnable {
private final String content;
private final String uri;
private Random random = new Random(System.currentTimeMillis());
public Saver(String content, String uri) {
this.content = content;
this.uri = uri;
}
@Override
public void run() {
String[] sps = uri.split("/");
String host = sps.length > 2 ? sps[2].replaceAll("\\.", "_") : "";
String fileName = new StringBuffer(SAVED_FOLDER).append(host)
.append("_").append(TimeStamp.getTimeStamp()).append("_")
.append(random.nextInt(1000)).append(".html").toString();
FileOutputStream fos = null;
try {
fos = new FileOutputStream(new File(fileName), true);
fos.write(content.getBytes());
fos.flush();
System.out.println("saver:" + uri + "写入完成");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
}
使用如下:
package com.cc.crawler.main;
import java.util.concurrent.TimeUnit;
import com.cc.crawer.infrastructure.Worker;
public class Main {
public static void main(String[] args) throws InterruptedException {
final Worker worker=new Worker();
worker.addStartAddress("www.baidu.com");
System.out.println("任务开始");
new Thread(new Runnable() {
@Override
public void run() {
worker.start();
}
}).start();
TimeUnit.SECONDS.sleep(10);
worker.stop();
}
}
没做什么优化(也不太清楚该怎么优化)
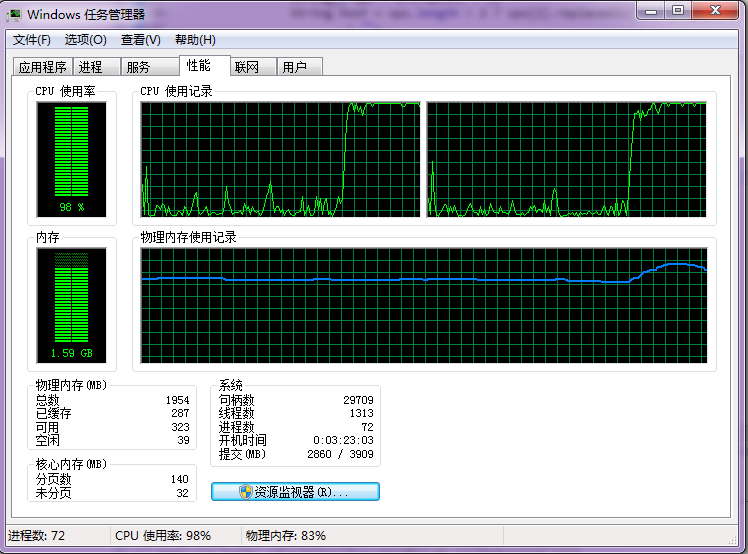
运行10s 用家中的台式机只能产生200个左右的网页
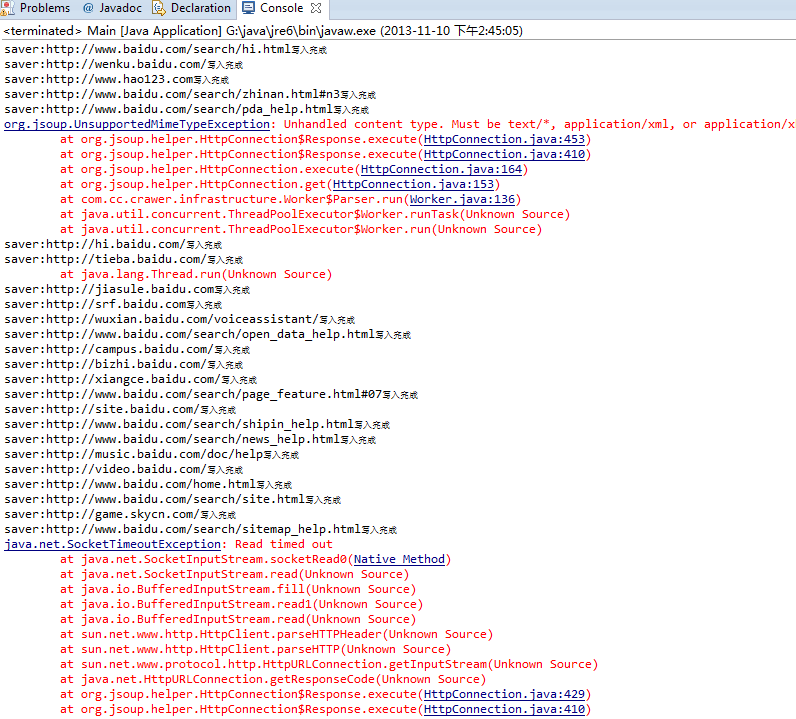
运行如下:

















 1347
1347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









