



一、selenium基本介绍
selenium主要用于Web端,可实现web自动化测试,可在多个浏览器进行并且支持多语言,自动化控制页面内容,可执行高级指令,如js脚本代码
二、selenium使用环境准备
- 安装python并配置
- 安装pycharm:编写python代码工具
- 安装selenium:安装不成功时切换镜像或者更新pip版本
更换镜像安装:pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple
pip更新:python -m pip install --upgrade pip
- 准备浏览器驱动(浏览器版本与驱动版本一致,驱动的exe文件需复制到python安装目录下)
谷歌浏览器驱动下载地址:https://googlechromelabs.github.io/chrome-for-testing/#stable
三、selenium基本用法
driver实例常用方法
- driver.get(url):加载指定的URL
- driver.back(): 返回上一页
- driver.forward(): 前进到下一页
- driver.refresh():刷新当前页面
- driver.set_window_size(200, 200) :设置浏览器的宽高大小
- driver.set_window_position(300, 300) :设置浏览器相对window页面的位置
- driver.get_window_position():获取浏览器相对window页面的位置
- driver.maximize_window():设置浏览器页面最大化,初始化浏览器页面使用
- driver.close():关闭当前页面
- driver.quit():关闭所有打开的页面
- print(driver.current_url):获取页面的当前url地址,也用于判断当前页面
- print(driver.title):获取当前页面的标题
- print(driver.name):获取当前浏览器
selenium入门
from selenium import webdriver
import time
# 创建webdriver对象
# 获取驱动对象
driver = webdriver.Chrome
# 通过驱动访问网页
driver.get('https://baidu.com')
# 页面最大化
driver.maximize_window()
# 强制等待
time.sleep(10)
# 关闭驱动对象
driver.quit()selenium元素定位
定位器
id:定位id属性与搜索值匹配的元素
name:定位name属于与搜索值匹配的元素
tag name:定位标签名称与搜索值匹配的元素
class name:定位class属于搜索值匹配的元素
link text:定位link text可视文本与搜索值匹配的元素
partial link text:定位link text可视文本部分与搜索值部分匹配的锚点元素
xpath:定位xpath表达式匹配的元素(常用)
css selector:定位css选择器匹配的元素
实例
# 元素按xpath定位
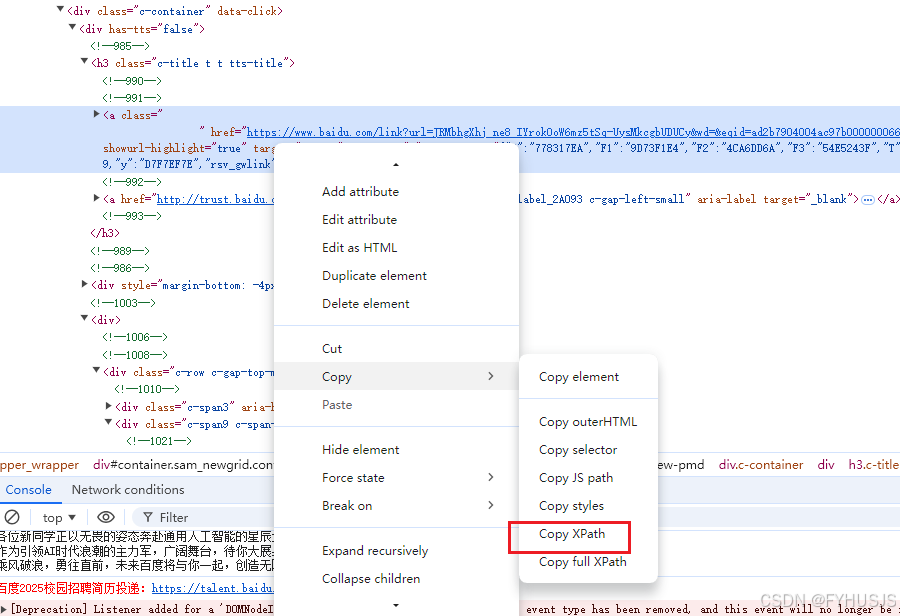
# 输入账号名
driver.find_element(By.xpath,此处是复制的值).send_keys("123456")
注意:有[]需加''"
# 输入密码
driver.find_element(By.xpath,此处为复制的值).send_keys('123456')
# 输入验证码
driver.find_elemet(By.xpath,此处为复制的值).send_keys('1234')
# 元素按id定位
driver.find_elemet(By.ID,"此处为id属性名称".send_keys('1234')# 元素按属性定位
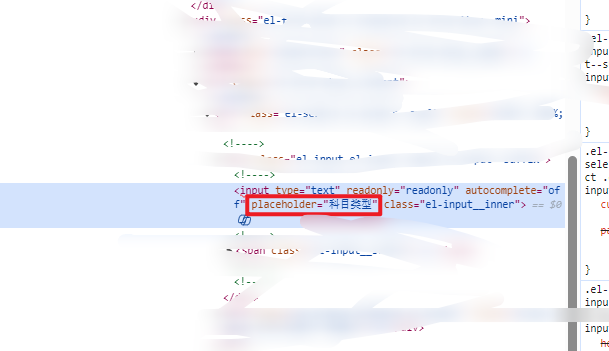
driver.find_element(By.XPATH,'//input[@placeholder="请输入科目代码"]')元素定位失败可能出现的原因
元素不可用,为只读,或元素不可见
解决:
- Window窗口Console控制台修改属性后再定位
var el = document.getElementById(‘此处是元素值名称’);
el.readOnly;
el.readOnly = false;#修改值
el.removeAttribute('readOnly');#或者删除只读属性- 通过JS脚本执行让元素改变属性后再定位
元素出现动态的属性如id
- 通过手写xpath进行定位即调用判断元素开头及结束或内容进行定位

其他原因
- 页面数据太长,可以加滚动进行定位
- 元素未加载完成,使用等待完成定位
- 元素在iframe子页面中需要切换
driver = webdriver.Chrome()
url = "https://mail.qq.com/"
driver.get(url)
driver.maximize_window ()
driver.implicitly_wait(5)
# 进入到登录框子页面中
frame1 = driver.find_element(By.XPATH,此处为登录框)
driver.switch_to.frame(frame1)
# 进入到密码登录所在的子页面中
frame2 = driver.find_element(By.XPATH,此处为登录所在子页面)
driver.switch_to.frame(frame2)
# 操作密码登录按钮
element1 = driver.find_element(By.XPATH,此处为密码).click()
sleep(5)
driver.quit()- 警告框,选择框特殊元素标签需要进行特殊处理
元素状态判断方法
预期条件模块(expected_conditions as EC)
- 使用前需导入模块:from selenium.webdriver.support import expected_conditions as EC
- 元素存在:EC.presence_of_element_located()
- 元素可见:EC.visibility_of_element_located()
- 元素不可见:EC.invisibility_of_element_located()
- 元素可点击:EC.element_to_be_clickable()
- 元素包含指定文本:EC.text_to_be_present_in_element()
- alert弹窗:EC.alert_is_present()
- 示例
try:
# 等待10秒,等待弹窗出现
wait = WebDriverWait(driver, 10)
# 判断确定按钮可点击,即弹窗出现
wait.until(EC.element_to_be_clickable(By.XPATH, 'xpath路径[contains(text(),"确定")]'))
wait.click()
print("已出现新增科目弹窗")
except:
print("没有找到新增科目弹窗")元素的其他操作
- 点击元素:click()
- 输入内容:send_keys()
- 清除文本:clear()
元素属性获取
- 元素大小:size
- 元素文本:text
- 获取属性值:get.attribute()
- 元素是否可见:is_display
- 元素是否可用:is enabled()
等待
- web中能看到的元素,不全写在HTML中,还可能会在js代码的dom(Document Object Model文档对象模型)操作产生的,js元素,需要先获取数据,处理后才会展示,不一定打开所有元素就加载完,需要等待时间
- 强制等待
time.sleep(等待的秒数)
- 隐式等待
- 创建好驱动之后,调用隐式等待方式传入等待时间
- 元素在第一次定位到时不触发隐式等待时长,直接操作元素
- 第一次定位失败,会触发隐式等待的有效时长
- 没有在有效时长定位到元素,会触发报错:nosuchelementexception
driver.implicitly_wait(等待的秒数)
- 显示等待
- 每隔一定时间不断尝试查找元素,找到元素则返回,找不到则报错
- 使用方法
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
#使用#
el1= WebDriverWait(driver,5).until(ec.presence_of_element_located((By.XPATH,复制的地址)))
driver.find_element(By.XPATH,'').click(By.XPATH,复制的地址)selenium实战
实战一 手动登录
1、测试用例设计
- 输入账号名
- 输入密码
- 输入验证码
- 点击登录
2、编写自动化用例脚本
# 输入账号名
driver.find_element(By.XPATH,复制的地址).send_keys("admin")
# 输入密码
driver.find_element(By.XPATH,复制的地址).send_keys("123456")
# 输入验证码
driver.find_element(By.XPATH,复制的地址).send_keys('1234')
# 点击登录按钮
driver.find_element(By.XPATH,复制的地址).click()3、验证码处理
- 测试阶段可关闭验证码最后再测试,或者验证码的值固定,或者动态获取验证码(第三方平台打码识别验证码)
- 第三方平台打码识别验证码:
- 截取验证码图片提取验证信息
# 截取验证码图片
driver.find_element(By.XPATH,复制的地址).screenshot("img.png")
- 验证码图片的识别三方平台-超级鹰:https://www.chaojiying.com/
- 通过发送三方接口请求识别验证码并获取响应信息的验证码结果
导包:
import requests as requests
具体代码:
封装函数 utils.py
import requests
def imgcode(file):
url="http://upload.chaojiying.net/Upload/Processing.png"
data={
# 用户名
"user":"ces1",
# 密码
"password": "123456",
# 用户id
"sofid": "949627",
# 验证码类型编码
"codetype":1902
}
# 打开读取图片二进制读取图片
files={"userfile":open(file,"rb")}
re=requests.post(url,data=data,files=files)
print(re.json())
res=re.json()
if res["err_no"]==0:
print("识别成功")
code=res["pic_str"]
print(f"验证码为:{code}")
return code
else:
print("识别失败")
return False注意:线性脚本和处理功能脚本需要独立封装进行调用
调用函数:
driver.find_element(By.XPATH,复制的地址).send_keys(code)
driver.find_element(By.XPATH,复制的地址).screenshot("img.png")
# 调用封装的截取验证码函数,获取返回结果值
code=imgcode("img.png")
driver.find_element(By.XPATH,复制的地址).send_keys(code)4、完成功能冒烟测试
实战二cookie保持登录状态
保持自动登录状态方式
- 由cookie信息的唯一标识id保持
- 程序保持登录状态,不退出
- 页面设置cookie信息,刷新页面清除缓存保持登录状态
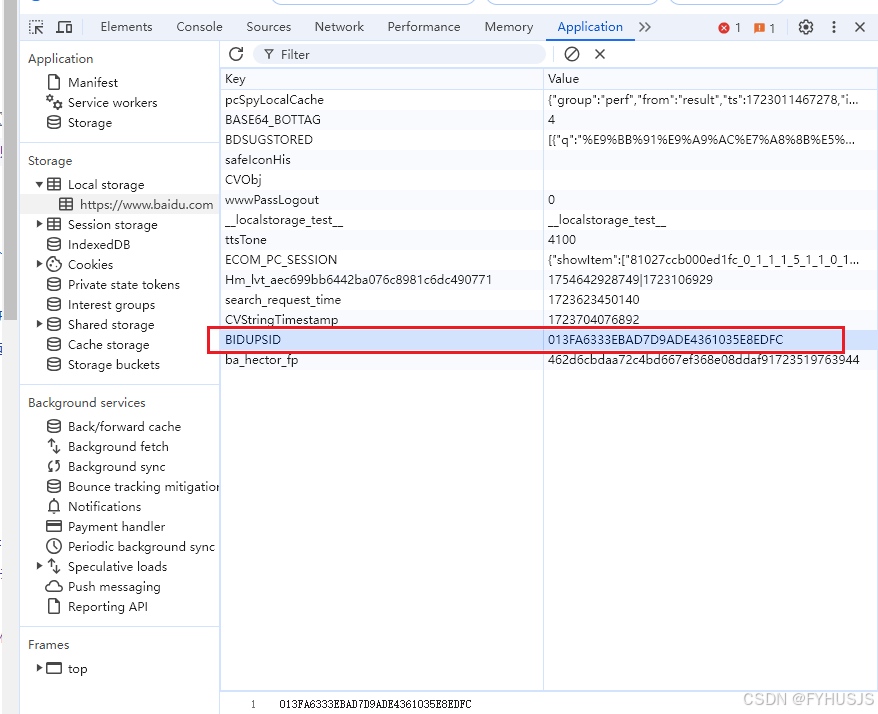
driver.add_cookie( { "key":"复制的值","value":"复制的值" } )
# 刷新页面
driver.refresh()
- 自动化获取cookie信息
页面第一次登录成功之后,保存当前页面的cookie信息
页面第二次登录及以后登录时,直接使用保存的cookie信息进行登录
代码如下:
utils.py
# 使用cookie信息
load_cookie(driver)
# 需要登录时走下面的代码,不需要则不管
if is_login(driver):
下面代码为登录模块的代码,直接tab对齐即可
time.sleep(10)# 前加入以下代码
# 保存cookie信息,调用保存函数,传入到驱动
save_cookie(driver)四、pytest测试框架基础
pytest基本概念
pytest是Python中的单元测试框架
pytest特点
- 支持参数化
- 执行用例时可以标记跳过用例或失败的用例
- 支持重复执行失败的用例
- 支持三方插件可实现自定义扩展
- 便捷管理用例,方便和持续集成工具相互结合,便于生成测试报告
测试框架的核心作用
- 找到测试用例
- 执行测试用例
- 管理测试用例
- 断言测试用例
- 生成测试报告
pytest常用插件
- pytest:测试框架
- pytest-html:生成HTML格式的自动化测试报告
- pytest-xdist:测试用例分布执行,多CPU分发
- pytest-ordering:控制测试用例的执行顺序
- allure-pytest:生成allure测试报告(美观)
- pytest-returnfailures:用例失败后重构
- pytest-base-url:管理基础路径
pytest常用插件安装步骤
- 新建requiremens.txt
- 标记所有插件名称
- 进入到venv环境
命令
- 运行安装命令:pip install - r requirements.txt
pytest默认的测试用例执行规则
- 包名必须以test开头或test结尾
- 模块名必须以test开头或test结尾
- 用例名必须以test开头或test结尾
1.函数
2.方法
- 实例方法
- 类方法
3.实战
创建一个包
创建Python文件
执行方式一:pytest
pytest -s:显示测试的详细信息(输出的信息)
pyte -vs:显示测试的详细信息,并展示执行步骤
pytest -h:查看pytest 的所有命令选项
pytest -k +用例名:指定执行具体某一条用例
执行方式二:通过主函数运行
import pytest
if __name__=="__main__":
pytest.main()
一个点代表通过用例
pytest标记跳过测试用例
1.无条件跳过测试用例
@pytest.mark.skip(reason = "用例不执行")
def test_login02():
print("开始执行登录测试用例02")2.有条件跳过测试用例(条件成立,用例不执行;条件不成立,用例执行)
# 有条件时跳过用例,默认条件是不成立的
@pytest.mark.skipif(1<10,reason = "03用例不执行")
def test_login03():
print("开始执行登录测试用例03")
pytest控制测试用例的执行顺序
默认执行顺序:按包名、文件名以及函数名前后顺序执行
pytest可以修改执行用例顺序插件:pytest-ordering
@pytest.mark.run(order = 3)
def test_login01():
print("11")pytest标记失败的用例
标记预期会出现异常的测试用例,出现异常则符合预期,无异常则用例则不符合预期
@pytest.mark.xfail(rasson = "异常用例,0不能为被除数")
def test_login04():
1 / 0
print("13")如果符合预期,则标记失败 成功(xfall)
不符合预期,则标记失败 失败(xpass)
pytest标记参数化
对于相似的用例执行过程,使用的数据不一样就可以使用参数化实现
@pytest.mark.parametrize("参数名",参数值)实例1:使用参数化实现多个用户登录
import pytest
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
@pytest.mark.parametrize("username,password,code",[(123456,1234,1),(1234,123,1)])
def test_login(username,password,code):
driver =webdriver.Chrome()
driver.get('链接')
driver.find_element(By.XPATH, 复制的值).send_keys(username)
# 输入密码
driver.find_element(By.XPATH, 复制的值).send_keys(password)
# # 输入验证码
driver.find_element(By.XPATH, 复制的值).send_keys(code)
# 点击登录按钮
driver.find_element(By.XPATH, 复制的值).click()参数化一般结合数据驱动进行自动化测试
数据驱动测试DDT:
- Data数据
- Driver驱动
- Tests用例
数据驱动测试数据存储方式类型如下:
- text文本
- csv文件(数据之间用英文逗号分隔)
import csv
# 实现数据驱动测试之读取csv数据符合参数化标准
def get_data():
da=csv.reader(open("login.csv"))
data_list=[]
print(da)
for i in da:
data_list.append(i)
else:
return data_list
print(get_data())
print(len(get_data()))- 使用csv参数
@pytest.mark.parametrize("username,password,code",get_data())- excel文件
- json文件
- yaml文件
pytest前后置(夹具)
1、夹具的作用
用例执行前后,需做的准备工作和收尾工作,主要用于固定测试环境,以及清理回收资源
2、已经定义pytest夹具分类
- 函数
- 方法
- 类
- 模块
3、自定义夹具
fixture工具:灵活调度固定的测试环境
简介:是pytes当中的一个装饰器
@pytest.fixture(夹具的作用域,参数化,自动使用)
- 一般在项目中集中管理
- 整个项目定义一个py模块:conftest.py专门用于放置自定义的fixture,文件名固定且不能修改
- 使用fixture时可不导包,直接使用
- 执行顺序:从最外面到最内,从上到下,相同名字根据Ascall编码定位fixture并执行
@pytest.fixture(scope="function",autouse=True)
def go_requse():
# 前置
print("自动登录ID")
yield
# 后置
print("保持登录成功后的用户ID")POM模式设计
POM定义
以页面对象模型进行封装和使用的模式,使得页面相互独立,便于用例管理
- P:page表示页面
- O:object表示对象
- M:module表示模型
核心思想
- 对页面元素进行封装成类的属性
- 对用例执行的流程设计成类的“实例方法”
- 通过定义好的页面类实例化一个对象,通过队对象调用实例的方式执行用例
核心作用
- 减少代码冗余
- 方便后期维护
- 页面元素发生变化,只需调整页面封装属性即可,提高用例脚本的维护性和可持续性
封装后台登录页面类
需要使用到三个文件
test_login.py
from .pom import BackgroundLoginPage
def test_Login(driver):
login_page = BackgroundLoginPage(driver)
login_page.login()
pom.py
from selenium.webdriver.common.by import By
# 封装后台登录页面类
class BackgroundLoginPage():
# 定义一个实例属性获取驱动
# 构造一个函数,设置初始状态
def __init__(self, driver):
# 将传入的driver保存为类的实例变量
self.driver = driver
self.input_username =(By.xpath,'复制的值')
self.input_password=(By.xpath,'复制的值')
self.input_code=(By.xapth,'复制的值')
self.but_login=(By.xpath,'复制的值')
def login(self):
# 使用*对上面的定位方式的元组进行解包
self.driver.find_element(*self.input_username).send_keys("123456")
self.driver.find_element(*self.input_password).send_keys("123456")
self.driver.find_element(*self.input_code).send_keys("1234")
self.driver.find_element(*self.but_login).click()
conftest.py
from selenium import webdriver
import pytest
import time
# 用例执行前获取驱动
@pytest.fixture()
# 定义一个名为driver的函数这个函数作为fixture的实现
def driver():
print("用例执行前获取驱动")
# 创建一个chome浏览器实例并启动浏览器
driver = webdriver.Chrome()
# 导航到指定的url
driver.get("http://www.baidu.com")
# 页面最大化
driver.maximize_window()
# yield关键字返回driver1对象
yield driver
# 关闭浏览器释放资源
time.sleep(10)
quit(driver)
















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









