 Net实战:搭建首个CNN目标检测网络
Net实战:搭建首个CNN目标检测网络




神经网络实战教程:打造你的首个目标检测模型
前言:环境准备,基于上一章节已经搭建好的AI环境,还需要准备如下几样Python库,直接使用pip安装即可。
albumentations2.0.8 # 数据增强库, 替换Pytorch中原有数据增强transformer
pycocotools2.0.10 # coco数据集工具
opencv-python4.11.0.86 # 视觉处理库
matplotlib3.10.3 # 数据可视化库
1.什么是神经网络,神经网络有哪几种?
🧠 一、神经网络的核心原理
(1)基本结构
神经元:基本计算单元,接收输入信号(加权求和),通过激活函数(如ReLU、Sigmoid)生成输出。
层级组织:
输入层:
接收原始数据(如图像像素、文本向量)。
隐藏层:
提取特征并逐层抽象(深度网络可达数十层)。
输出层:
生成最终结果(如分类标签、预测值)。
链接权重:
神经元间的连接强度,通过训练数据动态调整,实现模式学习。
(2)核心特性
非线性:
激活函数引入非线性,使网络能拟合复杂函数(如曲线边界分类)。
并行分布式处理:
信息分散存储于大量神经元,具备容错性(部分节点损坏不影响整体)。
自学习能力:
通过反向传播算法优化权重,最小化预测误差
🔢 二、神经网络的分类(按结构与功能)
-
前馈神经网络(Feedforward Neural Network, FNN)
结构:
信息单向流动(输入层→隐藏层→输出层),无反馈环。
典型模型:
感知机(Perceptron):
单层网络,仅处理线性可分问题(如简单二分类)。
多层感知机(MLP):
含隐藏层,可解决非线性问题(如房价预测)。
应用:
结构化数据分类、回归分析。 -
卷积神经网络(Convolutional Neural Network, CNN)
结构:
卷积层:
滑动滤波器提取局部特征(如边缘、纹理)。
池化层:
降维保留关键信息(如最大池化)。
全连接层:
整合特征进行分类。
特性:
权值共享减少参数量,平移不变性(物体位置变化不影响识别)。
应用:图像分类(ResNet)、目标检测(YOLO)、医学影像分析。 -
循环神经网络(Recurrent Neural Network, RNN)
结构:
神经元带循环连接,隐藏状态传递历史信息。
问题:
长序列训练易出现梯度消失/爆炸。
改进模型:
LSTM(长短期记忆):
引入遗忘门、输入门、输出门,选择性记忆长期依赖。
GRU(门控循环单元):
简化LSTM,减少计算量。
应用:
机器翻译、股票预测、语音识别。 -
生成对抗网络(Generative Adversarial Network, GAN)
结构:
双网络对抗训练:
生成器:
合成逼真数据(如图像)。
判别器:
区分生成数据与真实数据。
特点:
无监督学习,生成高质量新样本。
应用:
图像生成(DeepFake)、数据增强、艺术创作。 -
Transformer 网络
结构:
基于自注意力机制,并行处理序列所有元素。
核心组件:
多头注意力:
捕捉不同维度的上下文关联。
位置编码:
注入序列顺序信息
应用:
自然语言处理(ChatGPT)、文本摘要、跨模态学习
2.如何利用框架搭建神经网络?
今天小编就带大家如何利用Pytorch框架来搭建一个简单CNN目标检测网络,直接上代码,代码中有注释便于大家理解其中意思。
(1)创建基础特征提取单元ConvBlock,通过:卷积 -> 归一化 -> 激活来实现:
a.卷积Conv作用:
空间特征提取:通过卷积核(3X3)滑动扫描输入图像的特征,计算局部区域的加权和,提取边缘,纹理等低级像素特征。
参数共享与平移不变性:同一个卷积核在整个图像上可复用,减少参数量(如3X3卷积核只需要9个权重/通道),同时针对位置变化的目标让模型更具鲁棒性
维度控制:
参数stride:控制输出尺寸
参数padding:维持空间分辨率,这里pading=1即保持输入输出一致
a.归一化BN作用:
内部协变量偏移(Internal Covariate Shift)抑制:深度网络中,每一层输入的分布会随参数更新而剧烈变化,导致训练震荡。批量归一化(Batch Normalization, BN)对每个 mini-batch 的每个通道独立计算均值和标准差。
优化训练过程:
加速收敛:梯度传播更稳定,允许使用更高学习率。
正则化效果:减少对 Dropout 的依赖。
缓解梯度消失或者梯度爆炸:控制激活值分布范围。
a.激活函数Act作用:
LeakyReLU:负区域保留微小梯度(斜率 0.01),避免神经元“死亡”
Mish:负区域缓慢趋近于 0,正区域无界,缓解过拟合,提升泛化能力,避免饱和区域梯度消失
Swish/SiLU:Sigmoid 动态调节信息通过量,加速收敛,大正输入时趋近线性
ReLU :负输入置零,提升特征选择性,负输入梯度为 0,可能导致神经元死亡
class ConvBlock(nn.Module):
"""基础卷积块:Conv + BN + Activation
这是一个标准的卷积组合模块,包含卷积层、批量归一化和激活函数
用于构建深度网络的基本单元,可以有效地提取特征并稳定训练
"""
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1, activation='leaky'):
"""
初始化卷积块
参数:
in_channels: 输入通道数
out_channels: 输出通道数
kernel_size: 卷积核大小,默认3x3
stride: 步长,默认1(不改变特征图大小)
padding: 填充,默认1(保持特征图大小)
activation: 激活函数类型,支持'leaky', 'mish', 'swish', 'relu'
"""
super().__init__()
# 卷积层:不使用偏置项,因为后面的BN层会进行归一化
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=False)
# 批量归一化:加速收敛,稳定训练
self.bn = nn.BatchNorm2d(out_channels)
# 根据参数选择不同的激活函数
if activation == 'leaky':
# LeakyReLU:允许负值通过,避免神经元死亡,0.1是负斜率
self.act = nn.LeakyReLU(0.1, inplace=True)
elif activation == 'mish':
# Mish:平滑的激活函数,性能优于ReLU
self.act = nn.Mish(inplace=True)
elif activation == 'swish':
# SiLU/Swish:自门控激活函数,x * sigmoid(x)
self.act = nn.SiLU(inplace=True)
else:
# 标准ReLU激活函数
self.act = nn.ReLU(inplace=True)
def forward(self, x):
"""前向传播:卷积 -> 批量归一化 -> 激活"""
return self.act(self.bn(self.conv(x)))
(2)创建残差块ResidualBlock
a.瓶颈结构设计:1×1 降维 → 3×3 特征提取 → 残差连接
b.作用:减少计算量的同时保持特征表达能力,缓解深度网络训练困难
class ResidualBlock(nn.Module):
"""残差块:提高网络深度同时保持梯度流动
使用瓶颈结构(bottleneck):先降维再升维,减少计算量
残差连接解决深度网络的梯度消失问题
"""
def __init__(self, channels):
"""
初始化残差块
参数:
channels: 输入输出通道数(保持不变)
"""
super().__init__()
# 1x1卷积降维到一半通道数,减少计算量
self.conv1 = ConvBlock(channels, channels//2, 1, padding=0)
# 3x3卷积进行特征提取,恢复原通道数
self.conv2 = ConvBlock(channels//2, channels, 3, padding=1)
def forward(self, x):
"""前向传播:实现残差连接"""
residual = x # 保存输入用于残差连接
out = self.conv1(x) # 降维
out = self.conv2(out) # 特征提取并恢复维度
return out + residual # 残差连接:将输入直接加到输出上
(2)创建金子塔池化模块:
1.模块结构以及作用:
a. 1X1卷积降维
作用:减少通道数量降低后续多尺度池化的计算量
实现方式:
输入通道从in_channels压缩至一半(例如512→256),减少计算开销。
1×1卷积不改变特征图尺寸(stride=1, padding=0),仅融合通道信息。
b.多尺度池化
目的:通过不同大小的池化核提取不同感受野的特征,捕捉局部细节到全局上下文。
实现方式:
stride=1 + 对称padding → 保持特征图分辨率不变(输入输出尺寸相同)
最大池化(MaxPooling)保留最显著特征,抑制噪声
c.特征拼接与融合
实现方式:
拼接:将原始特征与三种池化结果在通道维度拼接(dim=1)
融合:通过1×1卷积(self.conv2)将拼接后的特征压缩至目标通道数
out_channels,整合多尺度信息,生成紧凑且表达能力强的特征。
在此小编解释一下什么是“感受野”?:其实就是指感觉系统中单个神经元能够响应的刺激区域范围,在这里能就指CNN网络响应的刺激区域范围
class SPP(nn.Module):
"""空间金字塔池化:增强多尺度特征表达
通过不同大小的池化核提取不同感受野的特征
有助于检测不同尺寸的目标
"""
def __init__(self, in_channels, out_channels):
"""
初始化SPP模块
参数:
in_channels: 输入通道数
out_channels: 输出通道数
"""
super().__init__()
# 1x1卷积降维,减少后续计算量
self.conv1 = ConvBlock(in_channels, in_channels//2, 1, padding=0)
# 三个不同大小的最大池化层,提取不同尺度的特征
self.pools = nn.ModuleList([
nn.MaxPool2d(5, stride=1, padding=2), # 5x5池化核,小感受野
nn.MaxPool2d(9, stride=1, padding=4), # 9x9池化核,中感受野
nn.MaxPool2d(13, stride=1, padding=6) # 13x13池化核,大感受野
])
# 1x1卷积融合多尺度特征
self.conv2 = ConvBlock(in_channels*2, out_channels, 1, padding=0)
def forward(self, x):
"""前向传播:多尺度特征提取和融合"""
x = self.conv1(x) # 降维
# 将原特征和三个不同尺度的池化特征拼接
pool_outputs = [x] + [pool(x) for pool in self.pools]
x = torch.cat(pool_outputs, dim=1) # 在通道维度拼接
return self.conv2(x) # 融合特征
(3)最后是神经网络的实现:
-
卷积层使用 Kaiming 初始化
-
BatchNorm 层权重初始化为 1,偏置为 0
-
检测头的置信度偏置初始化为 -5.0,降低初始假阳性
class CrazyNet(nn.Module):
"""CrazyNet: 一个用于目标检测的深度卷积神经网络
采用多阶段特征提取、残差连接和SPP增强
输出格式适配YOLO风格的目标检测
"""
def __init__(self, num_classes=80, anchors=None):
"""
初始化CrazyNet
参数:
num_classes: 检测的类别数,默认80(COCO数据集)
anchors: 锚框尺寸,用于目标检测
"""
super(CrazyNet, self).__init__()
# 设置默认锚框(宽度,高度),这些是预定义的边界框尺寸
self.anchors = anchors if anchors else [[10,13], [16,30], [33,23]]
self.num_anchors = len(self.anchors) # 锚框数量
self.num_classes = num_classes # 类别数
# **改进的特征提取网络**
# Stage 1: 输入处理 (416x416x3 -> 208x208x64)
# 初始特征提取,使用Mish激活函数提升性能
self.stage1 = nn.Sequential(
ConvBlock(3, 32, 3, 1, 1, 'mish'), # RGB输入,提取32个特征
ConvBlock(32, 64, 3, 2, 1, 'mish'), # 步长2下采样,特征图缩小一半
ResidualBlock(64), # 残差块增强特征
)
# Stage 2: 浅层特征 (208x208x64 -> 104x104x128)
# 进一步提取浅层特征,增加网络深度
self.stage2 = nn.Sequential(
ConvBlock(64, 128, 3, 2, 1, 'mish'), # 下采样并增加通道数
ResidualBlock(128), # 第一个残差块
ResidualBlock(128), # 第二个残差块,增强特征表达
)
# Stage 3: 中层特征 (104x104x128 -> 52x52x256)
# 中层特征提取,网络开始变深
self.stage3 = nn.Sequential(
ConvBlock(128, 256, 3, 2, 1, 'mish'), # 下采样到52x52
ResidualBlock(256), # 连续三个残差块
ResidualBlock(256), # 提取更复杂的特征
ResidualBlock(256), # 增强特征表达能力
)
# Stage 4: 深层特征 (52x52x256 -> 26x26x512)
# 深层特征提取,感受野继续增大
self.stage4 = nn.Sequential(
ConvBlock(256, 512, 3, 2, 1, 'mish'), # 下采样到26x26
ResidualBlock(512), # 四个残差块
ResidualBlock(512), # 学习更抽象的特征
ResidualBlock(512), # 增加网络容量
ResidualBlock(512), # 提升特征表达能力
)
# Stage 5: 最深层特征 (26x26x512 -> 13x13x1024)
# 最深层特征提取,用于检测大目标
self.stage5 = nn.Sequential(
ConvBlock(512, 1024, 3, 2, 1, 'mish'), # 下采样到13x13
ResidualBlock(1024), # 三个残差块
ResidualBlock(1024), # 提取高级语义特征
ResidualBlock(1024), # 增强特征判别能力
)
# **空间金字塔池化增强特征**
# SPP模块用于融合不同尺度的特征,提升对不同大小目标的检测能力
self.spp = SPP(1024, 1024)
# **检测头部分**
# 特征细化,为最终预测做准备
self.neck = nn.Sequential(
ConvBlock(1024, 512, 1, padding=0), # 1x1卷积降维
ConvBlock(512, 1024, 3, padding=1), # 3x3卷积特征提取
ConvBlock(1024, 512, 1, padding=0), # 1x1卷积再次降维
)
# **最终预测层**
# 输出每个锚框的预测值:(x,y,w,h,conf) + 类别概率
self.prediction = nn.Sequential(
ConvBlock(512, 1024, 3, padding=1), # 最后的特征提取
# 输出通道数 = 锚框数 * (5个边界框参数 + 类别数)
nn.Conv2d(1024, self.num_anchors * (5 + num_classes), 1, bias=True)
)
# **权重初始化**
# 合理的初始化有助于模型收敛
self._initialize_weights()
def _initialize_weights(self):
"""权重初始化:使用合适的初始化策略加速训练"""
for m in self.modules():
if isinstance(m, nn.Conv2d):
# Kaiming初始化适合ReLU类激活函数
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='leaky_relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0) # 偏置初始化为0
elif isinstance(m, nn.BatchNorm2d):
# BN层的权重初始化为1,偏置为0
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# **重要**: 对最终预测层进行特殊初始化
final_conv = self.prediction[-1] # 获取最后的卷积层
nn.init.normal_(final_conv.weight, 0, 0.01) # 权重用小的正态分布初始化
if final_conv.bias is not None:
# 按照输出格式初始化偏置
# 每个锚框预测5+num_classes个值
# 置信度偏置初始化为负值,降低初始预测,避免假阳性
nn.init.constant_(final_conv.bias[0::5+self.num_classes], -5.0) # objectness置信度
nn.init.constant_(final_conv.bias[1::5+self.num_classes], 0) # 中心点x坐标
nn.init.constant_(final_conv.bias[2::5+self.num_classes], 0) # 中心点y坐标
nn.init.constant_(final_conv.bias[3::5+self.num_classes], 0) # 边界框宽度
nn.init.constant_(final_conv.bias[4::5+self.num_classes], 0) # 边界框高度
# 类别概率偏置初始化为0
for i in range(5, 5+self.num_classes):
nn.init.constant_(final_conv.bias[i::5+self.num_classes], 0)
def forward(self, x):
"""前向传播:逐层提取特征并生成预测"""
# **逐级特征提取**
x1 = self.stage1(x) # (B, 64, 208, 208) - 浅层特征
x2 = self.stage2(x1) # (B, 128, 104, 104) - 低层特征
x3 = self.stage3(x2) # (B, 256, 52, 52) - 中层特征
x4 = self.stage4(x3) # (B, 512, 26, 26) - 深层特征
x5 = self.stage5(x4) # (B, 1024, 13, 13) - 最深层特征
# **SPP增强特征**
x5 = self.spp(x5) # (B, 1024, 13, 13) - 多尺度特征融合
# **检测头处理**
x = self.neck(x5) # (B, 512, 13, 13) - 特征细化
x = self.prediction(x) # (B, A*(5+C), 13, 13) - 生成预测
# **维度重排**
# 将输出重新组织为更易理解的格式
B, _, H, W = x.shape # 批次大小,通道数,高度,宽度
# 重塑为 (批次, 锚框数, 预测值, 高度, 宽度)
x = x.view(B, self.num_anchors, 5+self.num_classes, H, W)
# 调整维度顺序为 (批次, 锚框数, 高度, 宽度, 预测值)
x = x.permute(0, 1, 3, 4, 2) # (B, A, H, W, 5+C)
return x
(4)下面是整个神经网络CrazyNet的完整代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class ConvBlock(nn.Module):
"""基础卷积块:Conv + BN + Activation
这是一个标准的卷积组合模块,包含卷积层、批量归一化和激活函数
用于构建深度网络的基本单元,可以有效地提取特征并稳定训练
"""
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1, activation='leaky'):
"""
初始化卷积块
参数:
in_channels: 输入通道数
out_channels: 输出通道数
kernel_size: 卷积核大小,默认3x3
stride: 步长,默认1(不改变特征图大小)
padding: 填充,默认1(保持特征图大小)
activation: 激活函数类型,支持'leaky', 'mish', 'swish', 'relu'
"""
super().__init__()
# 卷积层:不使用偏置项,因为后面的BN层会进行归一化
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=False)
# 批量归一化:加速收敛,稳定训练
self.bn = nn.BatchNorm2d(out_channels)
# 根据参数选择不同的激活函数
if activation == 'leaky':
# LeakyReLU:允许负值通过,避免神经元死亡,0.1是负斜率
self.act = nn.LeakyReLU(0.1, inplace=True)
elif activation == 'mish':
# Mish:平滑的激活函数,性能优于ReLU
self.act = nn.Mish(inplace=True)
elif activation == 'swish':
# SiLU/Swish:自门控激活函数,x * sigmoid(x)
self.act = nn.SiLU(inplace=True)
else:
# 标准ReLU激活函数
self.act = nn.ReLU(inplace=True)
def forward(self, x):
"""前向传播:卷积 -> 批量归一化 -> 激活"""
return self.act(self.bn(self.conv(x)))
class ResidualBlock(nn.Module):
"""残差块:提高网络深度同时保持梯度流动
使用瓶颈结构(bottleneck):先降维再升维,减少计算量
残差连接解决深度网络的梯度消失问题
"""
def __init__(self, channels):
"""
初始化残差块
参数:
channels: 输入输出通道数(保持不变)
"""
super().__init__()
# 1x1卷积降维到一半通道数,减少计算量
self.conv1 = ConvBlock(channels, channels//2, 1, padding=0)
# 3x3卷积进行特征提取,恢复原通道数
self.conv2 = ConvBlock(channels//2, channels, 3, padding=1)
def forward(self, x):
"""前向传播:实现残差连接"""
residual = x # 保存输入用于残差连接
out = self.conv1(x) # 降维
out = self.conv2(out) # 特征提取并恢复维度
return out + residual # 残差连接:将输入直接加到输出上
class SPP(nn.Module):
"""空间金字塔池化:增强多尺度特征表达
通过不同大小的池化核提取不同感受野的特征
有助于检测不同尺寸的目标
"""
def __init__(self, in_channels, out_channels):
"""
初始化SPP模块
参数:
in_channels: 输入通道数
out_channels: 输出通道数
"""
super().__init__()
# 1x1卷积降维,减少后续计算量
self.conv1 = ConvBlock(in_channels, in_channels//2, 1, padding=0)
# 三个不同大小的最大池化层,提取不同尺度的特征
self.pools = nn.ModuleList([
nn.MaxPool2d(5, stride=1, padding=2), # 5x5池化核,小感受野
nn.MaxPool2d(9, stride=1, padding=4), # 9x9池化核,中感受野
nn.MaxPool2d(13, stride=1, padding=6) # 13x13池化核,大感受野
])
# 1x1卷积融合多尺度特征
self.conv2 = ConvBlock(in_channels*2, out_channels, 1, padding=0)
def forward(self, x):
"""前向传播:多尺度特征提取和融合"""
x = self.conv1(x) # 降维
# 将原特征和三个不同尺度的池化特征拼接
pool_outputs = [x] + [pool(x) for pool in self.pools]
x = torch.cat(pool_outputs, dim=1) # 在通道维度拼接
return self.conv2(x) # 融合特征
class CrazyNet(nn.Module):
"""CrazyNet: 一个用于目标检测的深度卷积神经网络
采用多阶段特征提取、残差连接和SPP增强
输出格式适配YOLO风格的目标检测
"""
def __init__(self, num_classes=80, anchors=None):
"""
初始化CrazyNet
参数:
num_classes: 检测的类别数,默认80(COCO数据集)
anchors: 锚框尺寸,用于目标检测
"""
super(CrazyNet, self).__init__()
# 设置默认锚框(宽度,高度),这些是预定义的边界框尺寸
self.anchors = anchors if anchors else [[10,13], [16,30], [33,23]]
self.num_anchors = len(self.anchors) # 锚框数量
self.num_classes = num_classes # 类别数
# **改进的特征提取网络**
# Stage 1: 输入处理 (416x416x3 -> 208x208x64)
# 初始特征提取,使用Mish激活函数提升性能
self.stage1 = nn.Sequential(
ConvBlock(3, 32, 3, 1, 1, 'mish'), # RGB输入,提取32个特征
ConvBlock(32, 64, 3, 2, 1, 'mish'), # 步长2下采样,特征图缩小一半
ResidualBlock(64), # 残差块增强特征
)
# Stage 2: 浅层特征 (208x208x64 -> 104x104x128)
# 进一步提取浅层特征,增加网络深度
self.stage2 = nn.Sequential(
ConvBlock(64, 128, 3, 2, 1, 'mish'), # 下采样并增加通道数
ResidualBlock(128), # 第一个残差块
ResidualBlock(128), # 第二个残差块,增强特征表达
)
# Stage 3: 中层特征 (104x104x128 -> 52x52x256)
# 中层特征提取,网络开始变深
self.stage3 = nn.Sequential(
ConvBlock(128, 256, 3, 2, 1, 'mish'), # 下采样到52x52
ResidualBlock(256), # 连续三个残差块
ResidualBlock(256), # 提取更复杂的特征
ResidualBlock(256), # 增强特征表达能力
)
# Stage 4: 深层特征 (52x52x256 -> 26x26x512)
# 深层特征提取,感受野继续增大
self.stage4 = nn.Sequential(
ConvBlock(256, 512, 3, 2, 1, 'mish'), # 下采样到26x26
ResidualBlock(512), # 四个残差块
ResidualBlock(512), # 学习更抽象的特征
ResidualBlock(512), # 增加网络容量
ResidualBlock(512), # 提升特征表达能力
)
# Stage 5: 最深层特征 (26x26x512 -> 13x13x1024)
# 最深层特征提取,用于检测大目标
self.stage5 = nn.Sequential(
ConvBlock(512, 1024, 3, 2, 1, 'mish'), # 下采样到13x13
ResidualBlock(1024), # 三个残差块
ResidualBlock(1024), # 提取高级语义特征
ResidualBlock(1024), # 增强特征判别能力
)
# **空间金字塔池化增强特征**
# SPP模块用于融合不同尺度的特征,提升对不同大小目标的检测能力
self.spp = SPP(1024, 1024)
# **检测头部分**
# 特征细化,为最终预测做准备
self.neck = nn.Sequential(
ConvBlock(1024, 512, 1, padding=0), # 1x1卷积降维
ConvBlock(512, 1024, 3, padding=1), # 3x3卷积特征提取
ConvBlock(1024, 512, 1, padding=0), # 1x1卷积再次降维
)
# **最终预测层**
# 输出每个锚框的预测值:(x,y,w,h,conf) + 类别概率
self.prediction = nn.Sequential(
ConvBlock(512, 1024, 3, padding=1), # 最后的特征提取
# 输出通道数 = 锚框数 * (5个边界框参数 + 类别数)
nn.Conv2d(1024, self.num_anchors * (5 + num_classes), 1, bias=True)
)
# **权重初始化**
# 合理的初始化有助于模型收敛
self._initialize_weights()
def _initialize_weights(self):
"""权重初始化:使用合适的初始化策略加速训练"""
for m in self.modules():
if isinstance(m, nn.Conv2d):
# Kaiming初始化适合ReLU类激活函数
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='leaky_relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0) # 偏置初始化为0
elif isinstance(m, nn.BatchNorm2d):
# BN层的权重初始化为1,偏置为0
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# **重要**: 对最终预测层进行特殊初始化
final_conv = self.prediction[-1] # 获取最后的卷积层
nn.init.normal_(final_conv.weight, 0, 0.01) # 权重用小的正态分布初始化
if final_conv.bias is not None:
# 按照输出格式初始化偏置
# 每个锚框预测5+num_classes个值
# 置信度偏置初始化为负值,降低初始预测,避免假阳性
nn.init.constant_(final_conv.bias[0::5+self.num_classes], -5.0) # objectness置信度
nn.init.constant_(final_conv.bias[1::5+self.num_classes], 0) # 中心点x坐标
nn.init.constant_(final_conv.bias[2::5+self.num_classes], 0) # 中心点y坐标
nn.init.constant_(final_conv.bias[3::5+self.num_classes], 0) # 边界框宽度
nn.init.constant_(final_conv.bias[4::5+self.num_classes], 0) # 边界框高度
# 类别概率偏置初始化为0
for i in range(5, 5+self.num_classes):
nn.init.constant_(final_conv.bias[i::5+self.num_classes], 0)
def forward(self, x):
"""前向传播:逐层提取特征并生成预测"""
# **逐级特征提取**
x1 = self.stage1(x) # (B, 64, 208, 208) - 浅层特征
x2 = self.stage2(x1) # (B, 128, 104, 104) - 低层特征
x3 = self.stage3(x2) # (B, 256, 52, 52) - 中层特征
x4 = self.stage4(x3) # (B, 512, 26, 26) - 深层特征
x5 = self.stage5(x4) # (B, 1024, 13, 13) - 最深层特征
# **SPP增强特征**
x5 = self.spp(x5) # (B, 1024, 13, 13) - 多尺度特征融合
# **检测头处理**
x = self.neck(x5) # (B, 512, 13, 13) - 特征细化
x = self.prediction(x) # (B, A*(5+C), 13, 13) - 生成预测
# **维度重排**
# 将输出重新组织为更易理解的格式
B, _, H, W = x.shape # 批次大小,通道数,高度,宽度
# 重塑为 (批次, 锚框数, 预测值, 高度, 宽度)
x = x.view(B, self.num_anchors, 5+self.num_classes, H, W)
# 调整维度顺序为 (批次, 锚框数, 高度, 宽度, 预测值)
x = x.permute(0, 1, 3, 4, 2) # (B, A, H, W, 5+C)
return x
模型架构:
|输入 (416×416×3)
| ↓
|Stage 1: Conv + Downsample → 208×208×64
| ↓
|Stage 2: Conv + Downsample + 2×Residual → 104×104×128
| ↓
|Stage 3: Conv + Downsample + 3×Residual → 52×52×256
| ↓
|Stage 4: Conv + Downsample + 4×Residual → 26×26×512
| ↓
|Stage 5: Conv + Downsample + 3×Residual → 13×13×1024
| ↓
|SPP Module → 13×13×1024
| ↓
|Detection Neck → 13×13×512
| ↓
|Prediction Head → 13×13×(num_anchors×(5+num_classes))
| ↓
|输出重排 → (B, A, H, W, 5+C)
用例模拟测试输出:
from model_classes.CrazyNet import CrazyNet
import torch
if __name__ == "__main__":
# 创建模型实例
model = CrazyNet(num_classes=80) # COCO 数据集有 80 个类别
# 输入数据
batch_size = 4
input_tensor = torch.randn(batch_size, 3, 416, 416)
# 前向传播
output = model(input_tensor)
print(f"输出形状: {output.shape}") # (4, 3, 13, 13, 85)
batch_size为4时的输出:

batch_size为1时的输出:
输出说明:
模型输出张量的形状为 (B, A, H, W, 5+C),其中:
B:批处理大小
A:锚框数量(默认3)
H,W:特征图的高度和宽度(13X13)
5+C:每个预测框的参数
前5个值:(x, y, w, h, conf) ----> (边界框中心坐标,边界框宽度和高度,目标置信度)
后C个值:各类别的概率分数
感觉系统中单个神经元能够响应的
参数说明: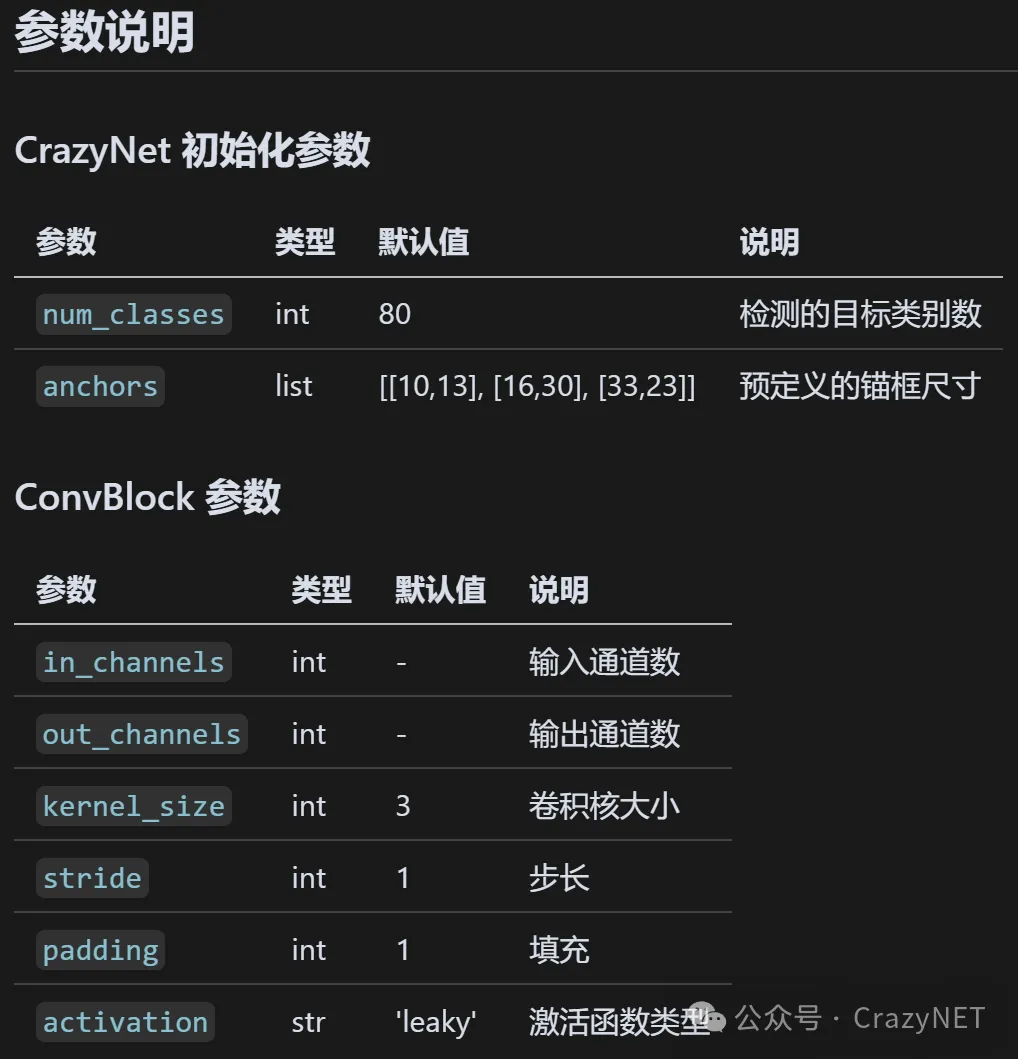
当然博主还有个轻量版CrazyNet如果想要整个工程源码的,请关注博主公众号#“CrazyNET”,然后回复数字 “x235a7910ob” 即可。
图片



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









