



本文首发于极市平台公众号,作者Happy。转载需获得授权并标明出处。

paper: https://arxiv.org/abs/2103.08756
code: https://github.com/liyunsheng13/dcd
本文是微软&加大圣地亚哥分校的研究员在动态卷积方面的一次突破性的探索,针对现有动态卷积(如CondConv、DY-Conv)存在的参数量大、联合优化困难问题,提出了一种动态通道融合机制替换之前的动态注意力。相比CondConv与DY-Conv,所提DCD以更少的参数量取得了更佳的性能。以MobileNetV2为例,所提方法仅需CondConv25%的参数量,同时可取得0.6%的性能提升(75.2% vs 74.6%)。本文对动态卷积进行了更为深入的解释,值得各位同学研读一番。
Abstract
近期关于动态卷积的一些研究表明:源于K个静态卷积核的自适应集成,动态卷积可以有效的提升现有CNN的性能。然而动态卷积同样存在两个局限:(1) 提升了卷积核参数量(K倍);(2)动态注意力与静态卷积核的联合优化极具挑战性。
我们从矩阵分解的角度对动态卷积进行了重思考并揭示了其中的关键问题:动态卷积是将动态注意力映射到高维隐空间后再对通道组进行动态关注。为解决该问题,我们提出采用动态融合替换作用于通道组的动态注意力。动态通道融合不仅有助于降低隐空间的维度,同时可以缓解联合问题问题。因此,所提方法更易于训练,仅需要更少的参数量且不会造成性能损失。
Dynamic Neural Network
动态卷积不同于常规卷积的地方在于:动态卷积的卷积核参数会随着输入的变换而动态的发生变化;而常规卷积则对任意输入均采用相同的卷积核参数。
在CNN领域知名的SE注意力机制就是一种知名的动态网络,它可以根据输入自适应的调整每个通道的加权系数;SKNet则是在不同尺寸的核上自适应调整注意力信息;谷歌的CondConv与微软的DY-Conv不约而同的采用类似“三个臭皮匠赛过诸葛亮”的思想自适应集成融合多个静态卷积核。
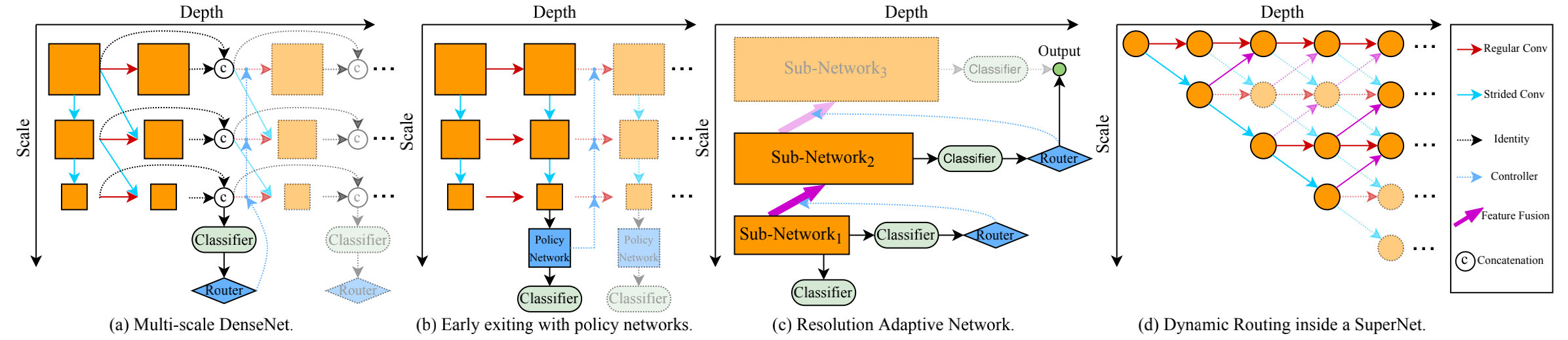
动态神经网络包含但不限于这里所提到的卷积核自适应调整,同时还包含自适应深度的神经网络、自适应输入分辨率的神经网络等等(可参考上图)。关于动态神经网络更系统的介绍可参考综述:《Dynamic Neural Network A Survey》。这里提供一个比较全面的动态神经网络的类型图,更详细的建议查看上述综述。
Dynamic Convolution Decomposition
动态卷积的最本质思想是根据输入动态的集成多个卷积核生成新的权重参数:
W(x)=∑k=1Kπk(x)Wks.t.0≤πk(x)≤1,∑k=1Kπk(x)=1
W(x) = \sum_{k=1}^K \pi_k(x)W_k \\
s.t. 0 \le \pi_k(x) \le 1, \sum_{k=1}^K \pi_k(x) = 1
W(x)=k=1∑Kπk(x)Wks.t.0≤πk(x)≤1,k=1∑Kπk(x)=1
目前比较知名的动态卷积有:谷歌提出的CondConv、MSRA提出的DY-Conv、华为提出的DyNet等等。然而动态卷积有两个主要的局限性:
- 紧致性的缺失;
- 联合优化问题。
针对上述两个问题,从矩阵分解角度出发,我们将动态卷积表示成如下形式:
Wk=W0+ΔWk,k∈{1,⋯ ,K}
W_k = W_0 + \Delta W_k , k \in \{1,\cdots, K\}
Wk=W0+ΔWk,k∈{1,⋯,K}
其中W0=1K∑WkW_0= \frac{1}{K} \sum W_kW0=K1∑Wk表示均值核,ΔWk=Wk−W0\Delta W_k = W_k -W_0ΔWk=Wk−W0表示残差核矩阵。对后者采用SVD进行更进一步的分解:ΔWk=UkSkVkT\Delta W_k = U_k S_k V_k^TΔWk=UkSkVkT,此时有:
W(x)=∑πk(x)W0+∑πk(x)UkSkVkT=W0+UΠ(x)SVT
W(x) = \sum \pi_k(x)W_0 + \sum \pi_k(x)U_kS_kV_k^T = W_0 + U\Pi(x)SV^T
W(x)=∑πk(x)W0+∑πk(x)UkSkVkT=W0+UΠ(x)SVT
下图给出了上述矩阵分解的示意图,也就是说:通过分解,W(x)W(x)W(x)的动态特性可以通过动态残差UΠ(x)SVTU\Pi(x)SV^TUΠ(x)SVT实现,而动态残差则是将输入x投影到了更高维空间SVTxSV^TxSVTx,然后再实施动态注意力Π(x)\Pi(x)Π(x)。这也就意味着:常规动态卷积的局限性源于通道组上的注意力,它引入了一个高维隐空间,导致较小的注意力值可能会抑制相应核的学习。
Dynamic Channel Fusion
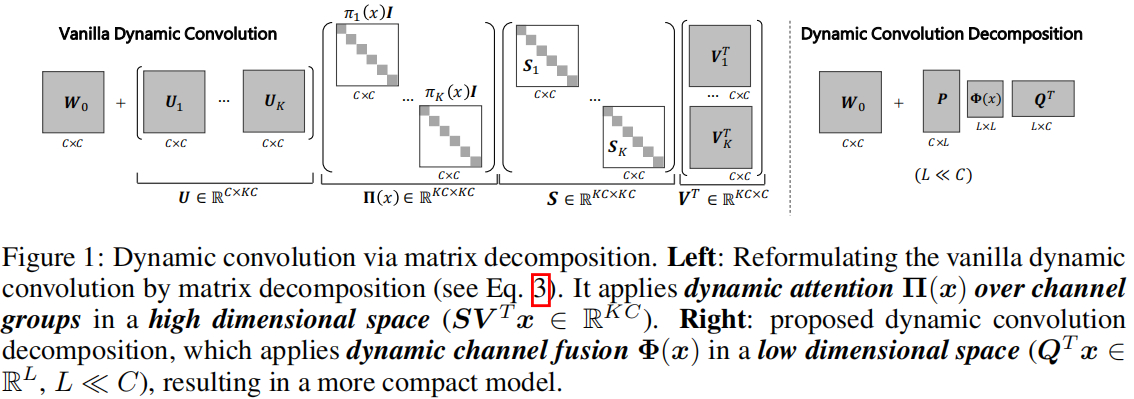
为解决上述问题,我们提出了Dynamic Convolution Decomposition(DCD),它采用动态通道融合替换动态注意力。所提DCD基于全动态矩阵Φ(x)\Phi(x)Φ(x)进行通道融合,见上图右,动态残差的实现可以表示为PΦ(x)QTP\Phi(x)Q^TPΦ(x)QT。动态通道融合的关键创新在于:Φ(x)\Phi(x)Φ(x)可以显著的减少隐空间的维度。基于动态通道融合的动态卷积可以表示如下:
W(x)=W0+PΦ(x)QT=W0+∑i=1L∑j=1Lpiϕi,j(x)qjT
W(x) = W_0 + P\Phi(x)Q^T = W_0 + \sum_{i=1}^L \sum_{j=1}^L p_i \phi_{i,j}(x) q_j^T
W(x)=W0+PΦ(x)QT=W0+i=1∑Lj=1∑Lpiϕi,j(x)qjT
其中Q∈RC×LQ \in R^{C\times L}Q∈RC×L用于将输入压缩到低维空间QTx∈RLQ^Tx \in R^LQTx∈RL,所得L个通道通过Φ(x)\Phi(x)Φ(x)进行动态融合,并通过PPP扩展到输出通道。这个过程即为动态卷积分解。隐空间的维度L通过L2<CL^2 < CL2<C进行约束,默认设置为⌊C2⌊log2C⌋⌋\lfloor \frac{C}{2^{\lfloor log_2 \sqrt{C} \rfloor}} \rfloor⌊2⌊log2C⌋C⌋。
通过上述方式,静态卷积参数量可以显著减少(LC v.s. KV2LC \text{ v.s. } KV^2LC v.s. KV2),进而可以得到一个更紧致模型。
与此同时,动态通道融合同时还缓解了常规动态卷积的联合优化问题。由于P与Q的每一列均与多个动态系数相关,因此pip_ipi的学习几乎不太可能被少量几个小的动态系数抑制。
总而言之,DCD采用了与常规动态卷积不同的动态集成形式,可以描述如下:
- 常规动态卷积采用共享的注意力机制在高维隐空间集成不共享的静态基向量;
- DCD再采用了不共享的动态通道融合机制在低维隐空间集成共享的静态基向量。
General Formulation
前面内容主要聚焦于动态残差部分,并提出了动态通道融合机制实现动态卷积。接下来,我们将讨论一下静态核W0W_0W0。在这里,我们对其约束∑kπx(x)=1\sum_k \pi_x(x)=1∑kπx(x)=1进行松弛得到了更广义形式:
W(x)=Λ(x)W0+PΦ(x)QT
W(x) = \Lambda(x) W_0 +P\Phi(x)Q^T
W(x)=Λ(x)W0+PΦ(x)QT
其中Λ(x)\Lambda(x)Λ(x)为C×CC\times CC×C对角矩阵,也就是说:Λ(x)\Lambda(x)Λ(x)在静态核上实现了通道级注意力。而这种广义形式可以进一步提升模型性能。
注意事项:这里的动态通道注意力与SE类似但不同,不同之处如下:
- Λ(x)\Lambda(x)Λ(x)并行于卷积,且与卷积共享输入x;计算复杂为min(O(C2),O(HWC))min(O(C^2), O(HWC))min(O(C2),O(HWC));
- SE则是位于卷积之后,并以卷积的输出作为输入;计算复杂度为O(HWC)O(HWC)O(HWC)。
- 很明显,当特征图的分辨率较大时,SE需要更多的计算量。
Implementation
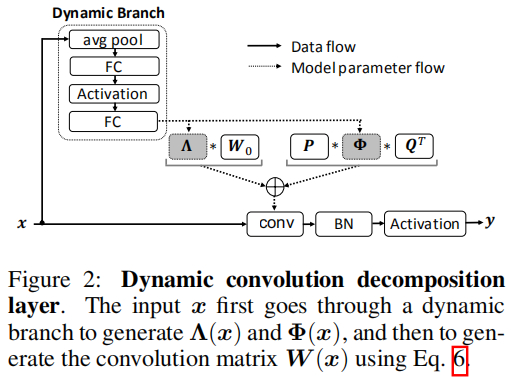
上图给出了DCD的实现示意图,它采用轻量的动态分支生成动态通道注意力Λ(x)\Lambda(x)Λ(x)于动态通道融合Φ(x)\Phi(x)Φ(x)。该动态分支的实现与SE类似:均值池化+两个全连接层。最后基于上述公式生成最终的卷积核参数。类似于静态卷积,DCD同样后接BatchNorm与非线性激活层。
在计算复杂度方面,DCD具有与常规动态卷积相似的复杂度。因此,我们主要针对参数量进行简单的分析。静态卷积与常规动态卷积的参数量分别为C2,KC2C^2, KC^2C2,KC2;而DCD的参数量则是C2+2CL+(2C+L2)CrC^2+2CL+(2C+L^2)\frac{C}{r}C2+2CL+(2C+L2)rC。由于L2<CL^2 < CL2<C,故参数量上限为(1+3/r)C2+2CC(1+3/r)C^2 +2C\sqrt{C}(1+3/r)C2+2CC。当r=16r=16r=16时,其参数量则约为1116C21\frac{1}{16}C^21161C2,这远小于DynamicConv的4C24C^24C2与CondConv的8C28C^28C2。
Extension
前面的介绍主要是以1×11\times 11×1卷积为例进行介绍分析,接下来,我们采用三种方式对其进行扩展:(a) 稀疏动态残差;(b) k×kk \times kk×k深度卷积;© $ k\times k$卷积。
Sparse Dynamic Residual
动态残差PΦ(x)QTP\Phi(x)Q^TPΦ(x)QT可以进一步简化为块对角阵形式PbΦb(x)QbT,b∈{1,⋯ ,B}P_b\Phi_b(x)Q_b^T, b\in\{1,\cdots,B\}PbΦb(x)QbT,b∈{1,⋯,B},可以表示如下:
W(x)=Λ(x)W0+⨁b=1BPbΦb(x)QbT
W(x) = \Lambda(x)W_0 + \bigoplus_{b=1}^{B} P_b \Phi_b(x) Q_b^T
W(x)=Λ(x)W0+b=1⨁BPbΦb(x)QbT
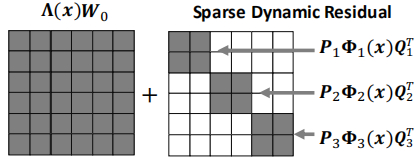
其中⨁i=1nAi=diag(A1,⋯ ,An)\bigoplus_{i=1}^n A_i = diag(A_1,\cdots,A_n)⨁i=1nAi=diag(A1,⋯,An)。这种形式具有一个特殊形式:B=1。即静态核仍为全矩阵,仅仅动态残差部分是稀疏的,下图给出了该特殊形式的示意图。在后续的实验中,我们会表明:B=8时可以取得最小的性能衰减,但仍会比静态核具有更好的性能。
k×kk \times kk×k深度卷积
k×kk \times kk×k深度卷积的权值构成了C×k2C\times k^2C×k2矩阵,DCD可以对前述公式中Q采用矩阵R 替换得到:
W(x)=Λ(x)W0+PΦ(x)QT
W(x) = \Lambda(x) W_0 +P\Phi(x)Q^T
W(x)=Λ(x)W0+PΦ(x)QT
其中,W(x),W0W(x), W_0W(x),W0均为C×k2C\times k^2C×k2矩阵,Λ(x)\Lambda(x)Λ(x)不变仍为对角矩阵,Q∈Rk2×LkQ \in R^{k^2 \times L_k}Q∈Rk2×Lk用于降低核元素数量;Φ(x)∈RLk×Lk\Phi(x) \in R^{L_k \times L_k}Φ(x)∈RLk×Lk用于动态融合,而P则是C×LkC\times L_kC×Lk用于LkL_kLk个核元素上进行深度卷积。我们默认Lk=⌊k2/2⌋L_k=\lfloor k^2/2 \rfloorLk=⌊k2/2⌋。由于深度卷积是通道分离的,故Φ(x)\Phi(x)Φ(x)不进行通道融合,而是进行隐核元素融合。
k×kk\times kk×k卷积
由于k×kk\times kk×k卷积核形式为C×C×k2C\times C \times k^2C×C×k2,DCD可以通过如下公式进行扩展:
W(x)=W0×2Λ(x)+Φ(x)×1Q×2P×3R
W(x) = W_0 \times_2 \Lambda(x) + \Phi(x) \times_1 Q \times_2 P \times_3 R
W(x)=W0×2Λ(x)+Φ(x)×1Q×2P×3R
这里的参数含义与深度卷积部分类似,默认参数:Lk=⌊k2/2⌋,L=⌊C/Lk2⌊log2C/Lk⌋⌋L_k =\lfloor k^2/2 \rfloor, L=\lfloor \frac{C/L_k}{2^{\lfloor log_2\sqrt{C/L_k} \rfloor}} \rfloorLk=⌊k2/2⌋,L=⌊2⌊log2C/Lk⌋C/Lk⌋
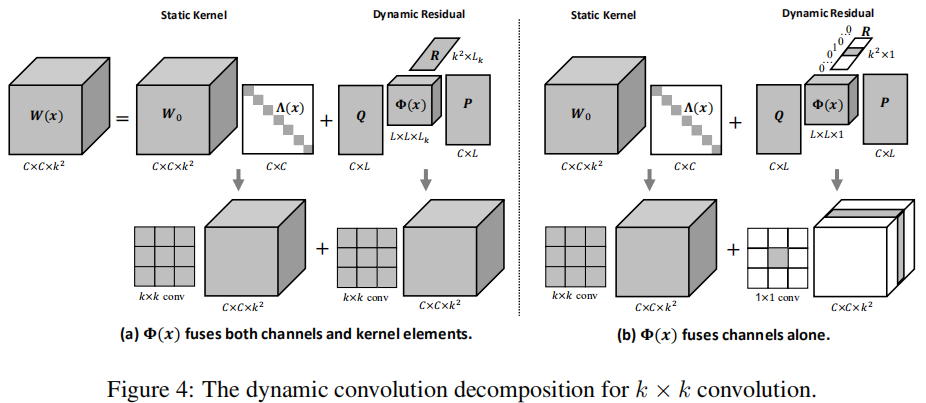
我们发现:Φ(x)×1Q\Phi(x)\times_1 QΦ(x)×1Q要比Φ(x)×3R\Phi(x)\times_3 RΦ(x)×3R更重要。因此,我们将LkL_kLk降低到1,并将L对应提升。此时,R简化为one-hot向量。上图给出了该形式下的动态卷积示意图。从上图b可以看到:动态残差仅仅具有一个非零切片,这等价于1×11\times 11×1卷积。因此**k×kk\times kk×k卷积的DCD等价于在静态核上添加了1×11\times 11×1动态残差**。
Experiments
为验证所提方案的有效性,我们在ImageNet数据集上的进行了一系列的对比试验&消融实验。基线模型包含ResNet与MobileNetV2,ResNet中的所有卷积均采用DCD实现,而MobileNetV2则对所有1×11\times 11×1卷积采用DCD实现。
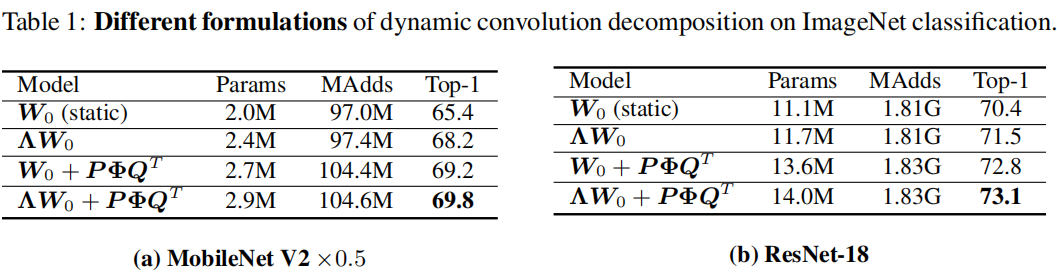
上图比较了DCD不同成分的影响性分析(在两个轻量型模型上进行了对比),从中可以看到:
- 相比静态卷积,两个动态成分Λ(x),Φ(x)\Lambda(x), \Phi(x)Λ(x),Φ(x)均可显著提升模型的精度;
- 相比动态通道注意力,动态通道融合具有稍高的精度、参数量以及FLOPs;而两者的组合则可以进一步提升模型性能。
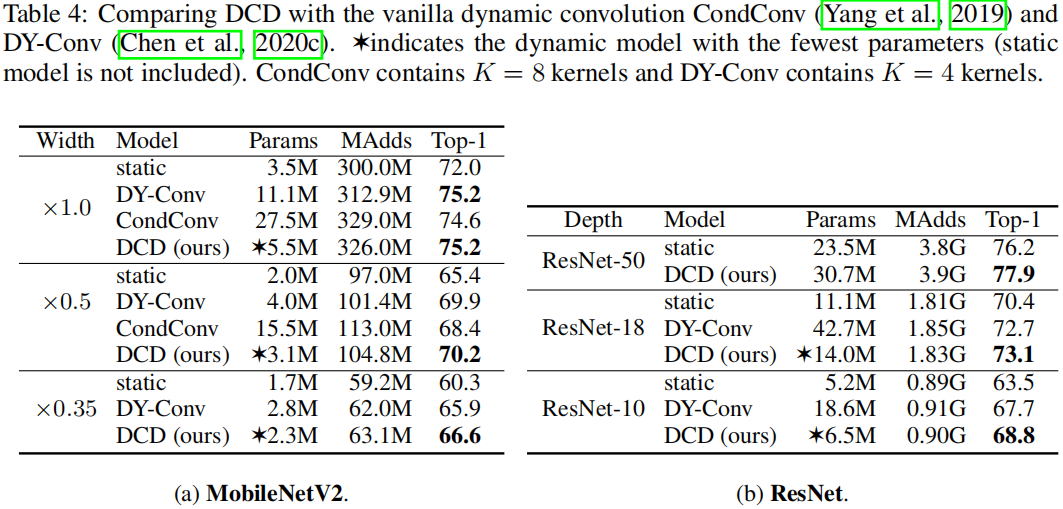
上表给出了所提方法与其他动态卷积的性能对比,可以看到:DCD可以显著减少模型参数量,同时提升模型的精度。比如MobileNetV2x1.0,DCD仅需更少(DynamicConv50%、CondConv25%)的参数量的参数量即可达到相当的精度;在ResNet18上,它仅需DynamicConv33%的参数量,且以0.4%指标优于DynamicConv。
全文到此结束,更多消融实验与分析建议各位同学查看原文。

















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









