



 介绍Facebook研究团队在CVPR2019上发布的逆向烹饪技术,该技术能够从食物图像中生成完整的食谱,包括食物名称、配料及烹饪步骤。采用两阶段训练流程,先预训练图像编码器和食材解码器,后训练食材编码器和指令解码器。
介绍Facebook研究团队在CVPR2019上发布的逆向烹饪技术,该技术能够从食物图像中生成完整的食谱,包括食物名称、配料及烹饪步骤。采用两阶段训练流程,先预训练图像编码器和食材解码器,后训练食材编码器和指令解码器。
文章目录
原文: Inverse Cooking: Recipe Generation from Food Images
Intro
Facebook research 在 CVPR2019 上发表的文章,做的是烹饪食谱生成,大致就是输入食物图像,输出预测的食物名 / 配料 / 菜谱指导。
此前有食物识别 / 菜谱检索的工作,但这里所有的内容都是生成的,以下是附录材料里给出的示例:


蛮讲道理,甚至感觉可以试试照着做(
Framework
Image
I
I
I -> Feature
e
I
e_I
eI -> label
l
l
l -> Ingredient embeddings
e
L
e_L
eL -> Predicted words
(
r
0
,
⋯
 
,
r
t
−
1
)
(r_0,\cdots,r_{t-1})
(r0,⋯,rt−1)
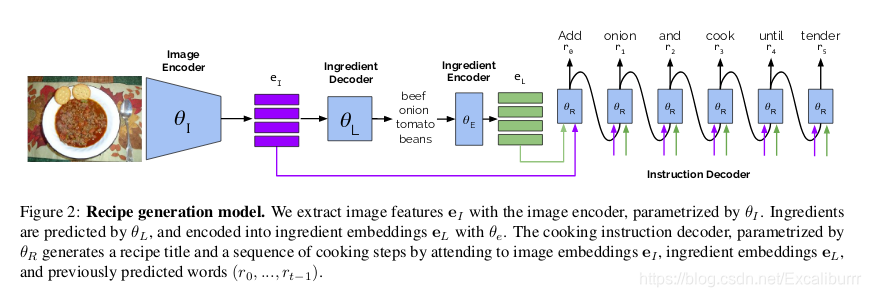
图像提取视觉特征,生成对应的食材标签,embedding到向量空间,最后由decoder生成句子。
比较特别的是生成食材标签的Decoder。
Encoder-Decoder Structure
用了两对Encoder-Decoder,主要流程如下:
Image I I I,
f
I
m
a
g
e
E
n
c
o
d
e
r
(
θ
I
,
I
)
=
e
I
f_{ImageEncoder}(\theta_I, I) = e_I
fImageEncoder(θI,I)=eI
f
I
n
g
r
e
d
i
e
n
t
D
e
c
o
d
e
r
(
θ
L
,
e
I
)
=
l
f_{IngredientDecoder}(\theta_L, e_I) = l
fIngredientDecoder(θL,eI)=l
f
I
n
g
r
e
d
i
e
n
t
E
n
c
o
d
e
r
(
θ
E
,
l
)
=
e
L
f_{IngredientEncoder}(\theta_E, l) = e_L
fIngredientEncoder(θE,l)=eL
f
I
n
s
t
r
u
c
t
i
o
n
D
e
c
o
d
e
r
(
θ
R
,
e
I
,
e
L
,
r
n
−
1
)
=
r
n
f_{InstructionDecoder}(\theta_R,e_I, e_L, r_{n-1}) = r_n
fInstructionDecoder(θR,eI,eL,rn−1)=rn
Encoder-Decoder Ⅰ(图像到语义的转化): Image I I I -> Feature e I e_I eI -> label l l l
Encoder-Decoder Ⅱ(语义到句子的转化): label l l l -> Ingredient embeddings e L e_L eL -> Predicted words ( r 0 , ⋯   , r t − 1 ) (r_0,\cdots,r_{t-1}) (r0,⋯,rt−1)
(这里Encoder-Decoder Ⅱ还补充了图像的feature, 以attention的形式输入)
Image Encoder
Resnet[:-2] + Conv + Dropout
...
self.resnet = nn.Sequential(*modules)
self.linear = nn.Sequential(
nn.Conv2d(resnet.fc.in_features, embed_size, kernel_size=1, padding=0),
nn.Dropout2d(dropout))
...
def forward(self, images, keep_cnn_gradients=False):
"""Extract feature vectors from input images."""
if keep_cnn_gradients:
raw_conv_feats = self.resnet(images)
else:
with torch.no_grad():
raw_conv_feats = self.resnet(images)
features = self.linear(raw_conv_feats)
features = features.view(features.size(0), features.size(1), -1)
return features
Ingredients Decoder
有两种表示食材的方式,分别是有序的 list 和无序的 set,而实际上,人类写菜谱食材的顺序也许有意义。
有训练数据 groundtruth: { ( x ( i ) , L ( i ) ) } i = 0 K \{(x^{(i)},L^{(i)})\}_{i=0}^{K} {(x(i),L(i))}i=0K,以交叉熵的形式逼近,
这样无序 set 的预测实现相对简单。
有序list旨在挖掘 element dependencies , 按 p ( L k ( i ) ^ ∣ x ( i ) , L < k ( i ) ) p(\hat{L_k^{(i)}}|x^{(i)},L_{<k}^{(i)}) p(Lk(i)^∣x(i),L<k(i))排序生成
从随机词开始,由前一个one-hot词预测下一步的词,为了避免 time step 顺序带来的惩罚,最后沿时间轴pooling(Softmax probabilities are pooled across time to avoid penalizing for order)
Two-Stage Training
- pre-train the image encoder and ingredients decoder.
- train the ingredient encoder and instruction decoder.
分两阶段训练,先训练Image Encoder和Ingredients Decoder,再训练剩下的部分。
Demo
Facebook research 在github开源了相关代码 , 其中包括可运行的demo以及权重。
先clone项目到本地:
git clone https://github.com/facebookresearch/inversecooking.git
按照提示下载: ingr_vocab.pkl ,instr_vocab.pkl,modelbest.ckpt,存放在data目录下
打开 demo.ipynb即可运行示例(我是用vscode导入到.py了),注意修改use_gpu = True
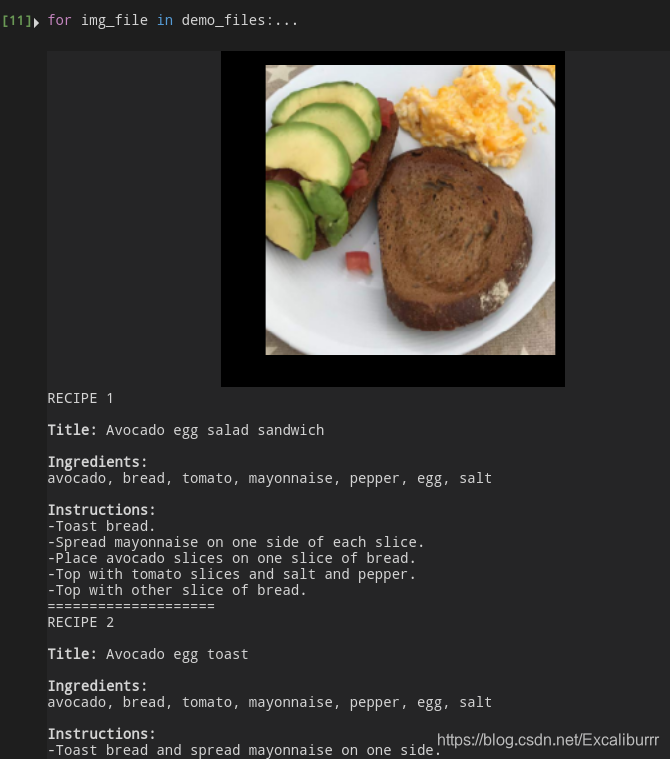
默认读取的是data/demo_imgs下的6张示例图片,效果如下:
[外链图片转存失败(img-qXENWyZl-1562139510157)(/home/sh/Pictures/DeepinScreenshot_select-area_20190703113712.png)]
感觉就光识别来讲就已经很不错了, 而且速度不算慢


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









