




 本文深入探讨了Java集合框架中的HashSet、LinkedHashSet、TreeSet、HashMap、LinkedHashMap及TreeMap的内部实现机制,包括数据结构特点、核心方法剖析及其应用场景。
本文深入探讨了Java集合框架中的HashSet、LinkedHashSet、TreeSet、HashMap、LinkedHashMap及TreeMap的内部实现机制,包括数据结构特点、核心方法剖析及其应用场景。
1、HashSet 和 HashMap
总体介绍:
之所以把HashSet和HashMap放在一起讲解,是因为二者在Java里有着相同的实现,前者仅仅是对后者做了一层包装,也就是说HashSet里面有一个HashMap(适配器模式)。因此本文将重点分析HashMap。 HashMap实现了Map接口,允许放入null元素,除该类未实现同步外,其余跟Hashtable大致相同,跟TreeMap不同,该容器不保证元素顺序,根据需要该容器可能会对元素重新哈希,元素的顺序也会被重新打散,因此不同时间迭代同一个HashMap的顺序可能会不同。 根据对冲突的处理方式不同,哈希表有两种实现方式,一种开放地址方式(Open addressing),另一种是冲突链表方式(Separate chaining with linked lists)。Java HashMap采用的是冲突链表方式。
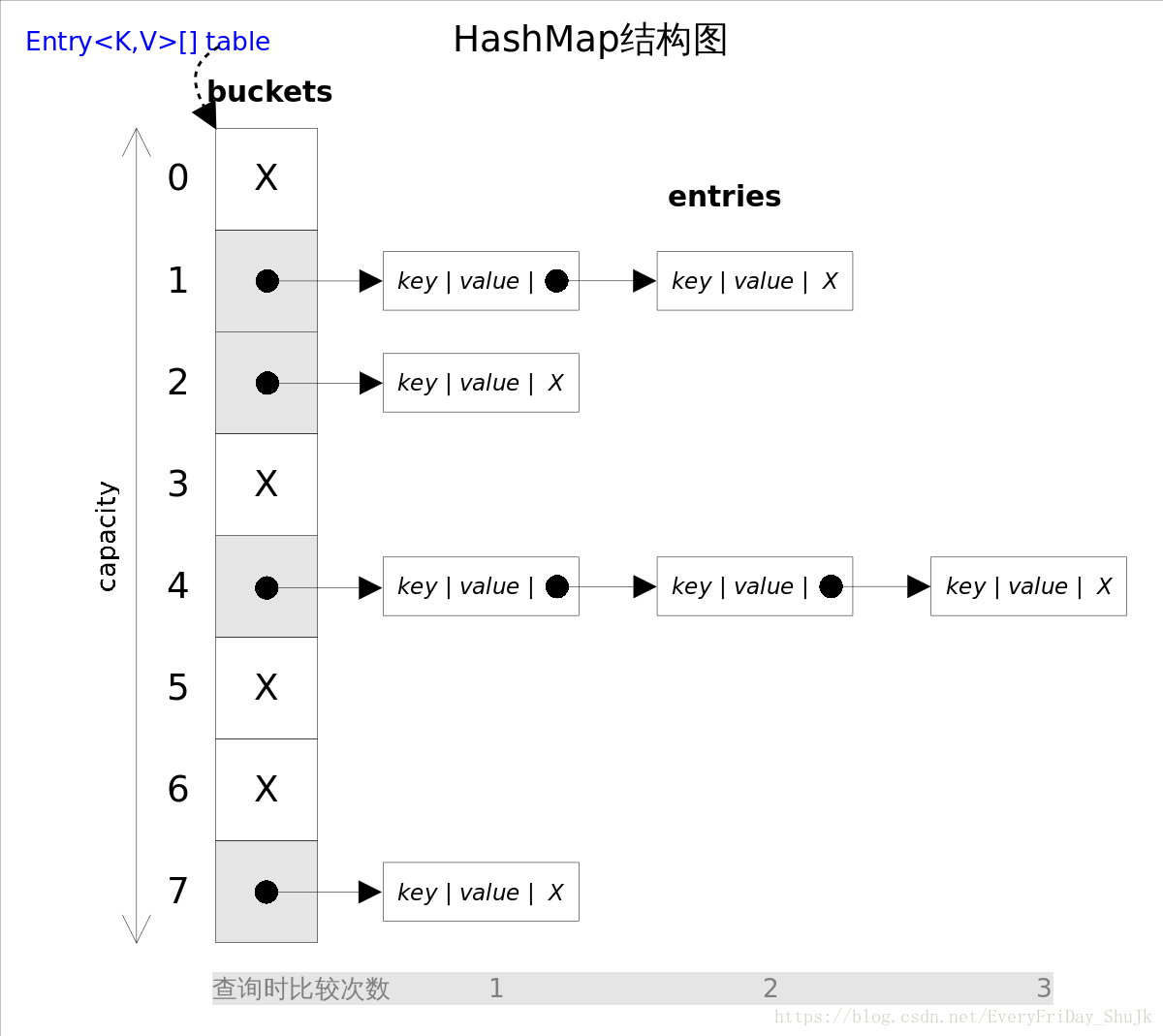
从上图容易看出,如果选择合适的哈希函数,put()和get()方法可以在常数时间内完成。但在对HashMap进行迭代时,需要遍历整个table以及后面跟的冲突链表。因此对于迭代比较频繁的场景,不宜将HashMap的初始大小设的过大。 有两个参数可以影响HashMap的性能:初始容量(inital capacity)和负载系数(load factor)。初始容量指定了初始table的大小,负载系数用来指定自动扩容的临界值。当entry的数量超过capacity*load_factor时,容器将自动扩容并重新哈希。对于插入元素较多的场景,将初始容量设大可以减少重新哈希的次数。 将对向放入到HashMap或HashSet中时,有两个方法需要特别关心:hashCode()和equals()。 hashCode()方法决定了对象会被放到哪个bucket里,当多个对象的哈希值冲突时,equals()方法决定了这些对象是否是“同一个对象”。所以,如果要将自定义的对象放入到HashMap或HashSet中,需要@Override hashCode()和equals()方法。
方法剖析
(1) get()
get(Object key)方法根据指定的key值返回对应的value,该方法调用了getEntry(Object key)得到相应的entry,然后返回entry.getValue()。因此getEntry()是算法的核心。 算法思想是首先通过hash()函数得到对应bucket的下标,然后依次遍历冲突链表,通过key.equals(k)方法来判断是否是要找的那个entry。
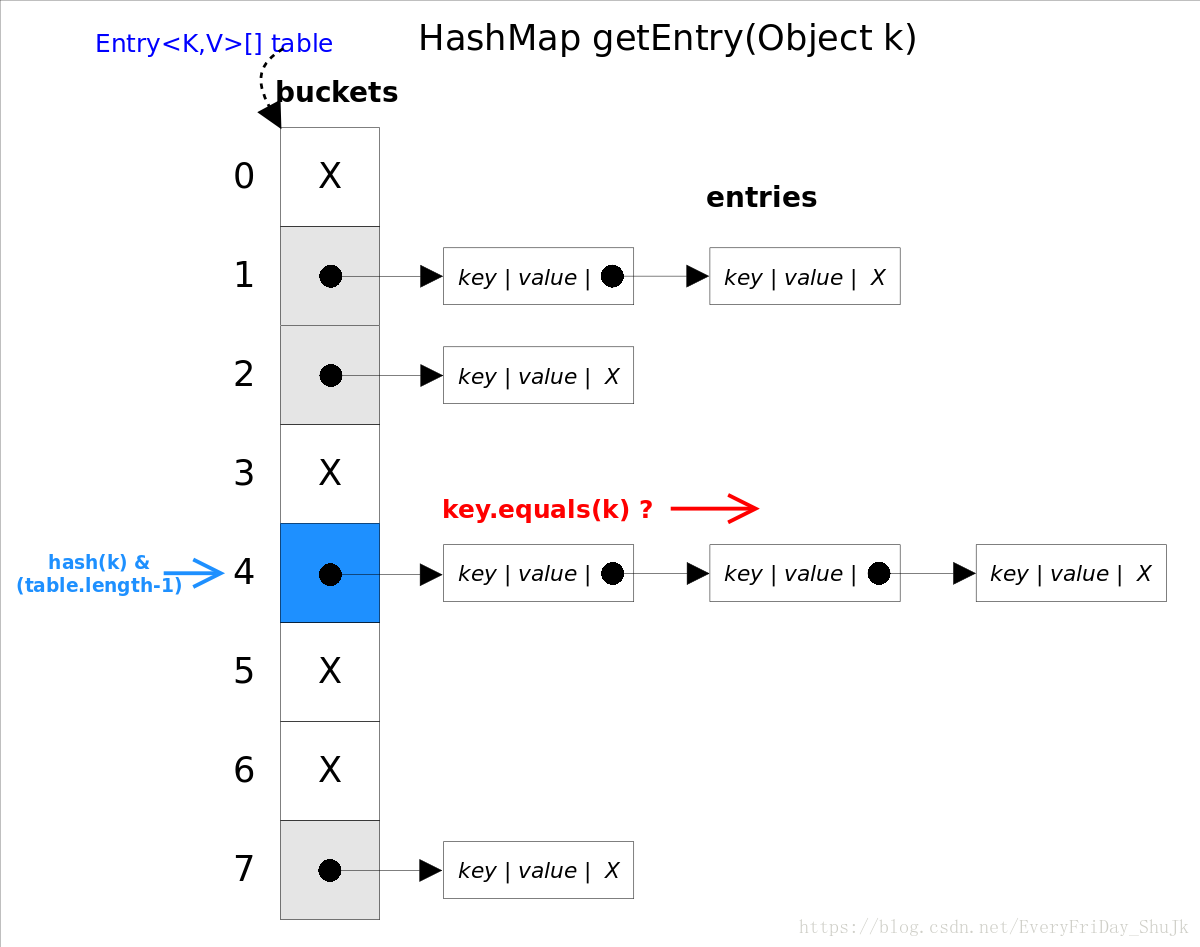
上图中hash(k)&(table.length-1)等价于hash(k)%table.length,原因是HashMap要求table.length必须是2的指数,因此table.length-1就是二进制低位全是1,跟hash(k)相与会将哈希值的高位全抹掉,剩下的就是余数了。
//getEntry()方法
final Entry<K,V> getEntry(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[hash&(table.length-1)];//得到冲突链表
e != null; e = e.next) {//依次遍历冲突链表中的每个entry
Object k;
//依据equals()方法判断是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}(2) put()
put(K key, V value)方法是将指定的key, value对添加到map里。该方法首先会对map做一次查找,看是否包含该元组,如果已经包含则直接返回,查找过程类似于getEntry()方法;如果没有找到,则会通过addEntry(int hash, K key, V value, int bucketIndex)方法插入新的entry,插入方式为头插法。
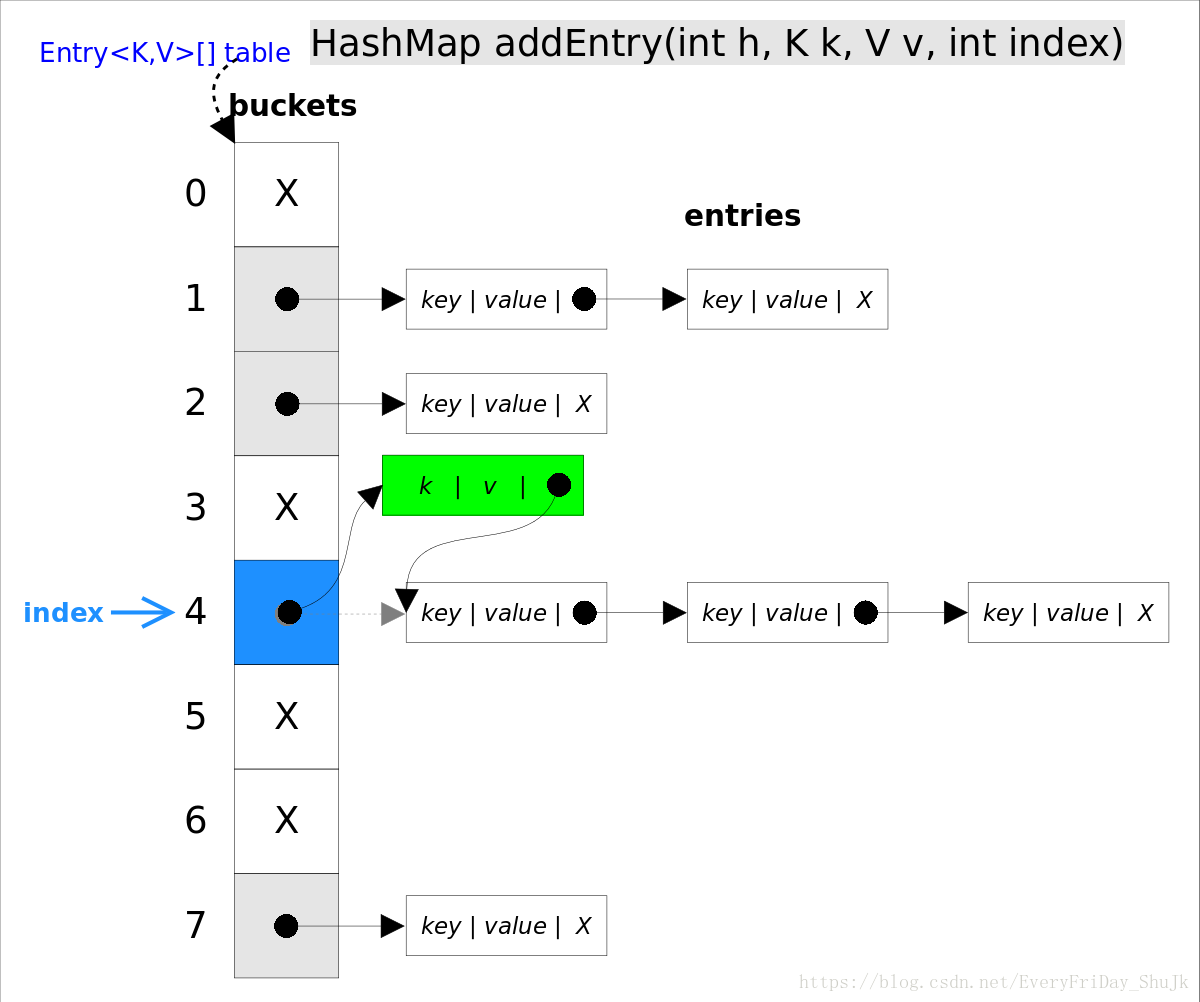
//addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);//自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);//hash%table.length
}
//在冲突链表头部插入新的entry
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}(3) remove()
remove(Object key)的作用是删除key值对应的entry,该方法的具体逻辑是在removeEntryForKey(Object key)里实现的。removeEntryForKey()方法会首先找到key值对应的entry,然后删除该entry(修改链表的相应指针)。查找过程跟getEntry()过程类似。

//removeEntryForKey()
final Entry<K,V> removeEntryForKey(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);//hash&(table.length-1)
Entry<K,V> prev = table[i];//得到冲突链表
Entry<K,V> e = prev;
while (e != null) {//遍历冲突链表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {//找到要删除的entry
modCount++; size--;
if (prev == e) table[i] = next;//删除的是冲突链表的第一个entry
else prev.next = next;
return e;
}
prev = e; e = next;
}
return e;
}HashSet
前面已经说过HashSet是对HashMap的简单包装,对HashSet的函数调用都会转换成合适的HashMap方法,因此HashSet的实现非常简单,只有不到300行代码。这里不再赘述。
//HashSet是对HashMap的简单包装
public class HashSet<E>
{
......
private transient HashMap<E,Object> map;//HashSet里面有一个HashMap
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
......
public boolean add(E e) {//简单的方法转换
return map.put(e, PRESENT)==null;
}
......
}2、LinkeHashSet和LInkedHashMap
总体介绍
如果你已看过前面关于HashSet和HashMap,以及TreeSet和TreeMap的讲解,一定能够想到本文将要讲解的LinkedHashSet和LinkedHashMap其实也是一回事。LinkedHashSet和LinkedHashMap在Java里也有着相同的实现,前者仅仅是对后者做了一层包装,也就是说LinkedHashSet里面有一个LinkedHashMap(适配器模式)。因此本文将重点分析LinkedHashMap。 LinkedHashMap实现了Map接口,即允许放入key为null的元素,也允许插入value为null的元素。从名字上可以看出该容器是linked list和HashMap的混合体,也就是说它同时满足HashMap和linked list的某些特性。可将LinkedHashMap看作采用linked list增强的HashMap。
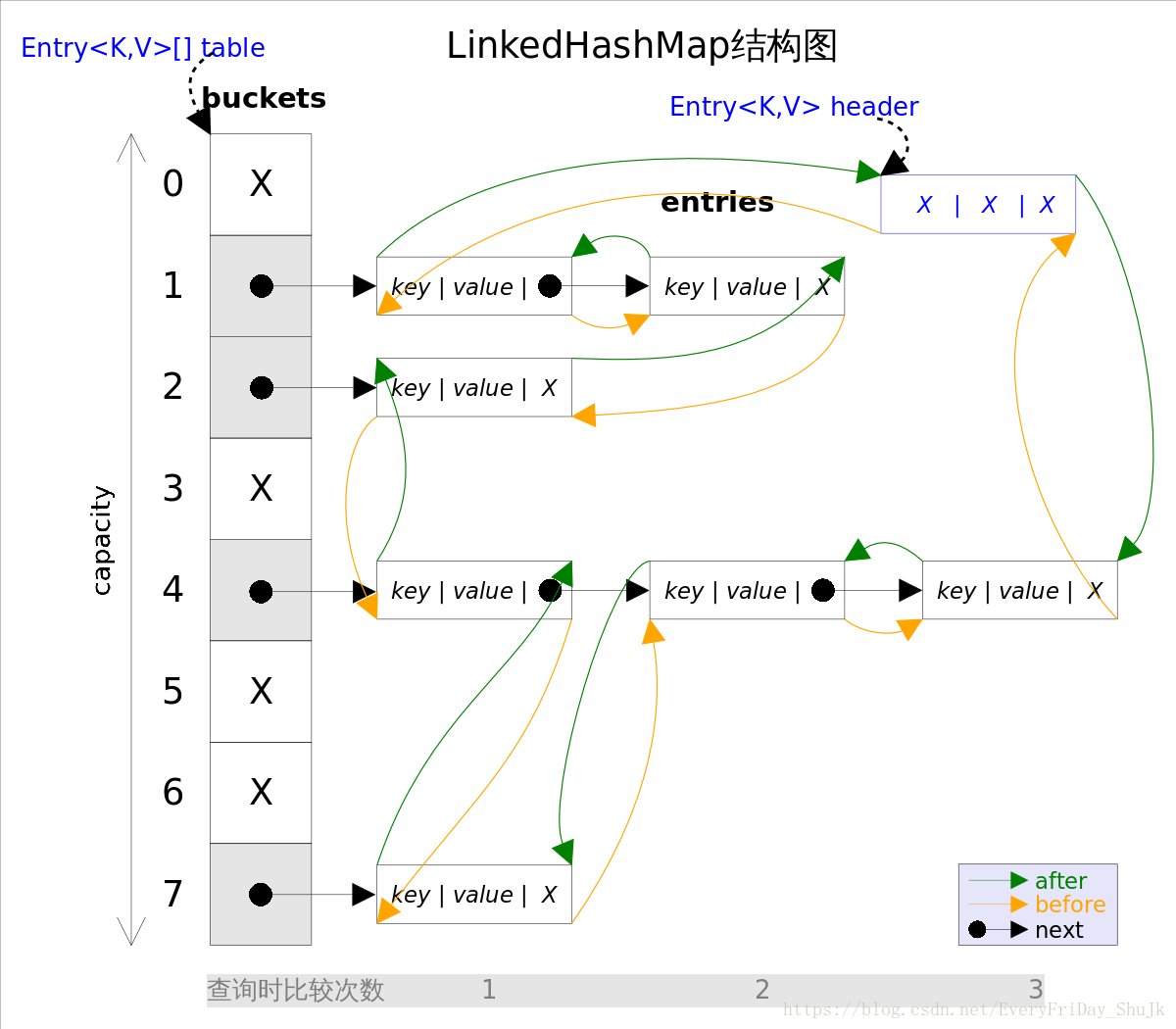
事实上LinkedHashMap是HashMap的直接子类,二者唯一的区别是LinkedHashMap在HashMap的基础上,采用双向链表(doubly-linked list)的形式将所有entry连接起来,这样是为保证元素的迭代顺序跟插入顺序相同。上图给出了LinkedHashMap的结构图,主体部分跟HashMap完全一样,多了header指向双向链表的头部(是一个哑元),该双向链表的迭代顺序就是entry的插入顺序。 除了可以保迭代历顺序,这种结构还有一个好处:迭代LinkedHashMap时不需要像HashMap那样遍历整个table,而只需要直接遍历header指向的双向链表即可,也就是说LinkedHashMap的迭代时间就只跟entry的个数相关,而跟table的大小无关。 有两个参数可以影响LinkedHashMap的性能:初始容量(inital capacity)和负载系数(load factor)。初始容量指定了初始table的大小,负载系数用来指定自动扩容的临界值。当entry的数量超过capacity*load_factor时,容器将自动扩容并重新哈希。对于插入元素较多的场景,将初始容量设大可以减少重新哈希的次数。 将对象放入到LinkedHashMap或LinkedHashSet中时,有两个方法需要特别关心:hashCode()和equals()。hashCode()方法决定了对象会被放到哪个bucket里,当多个对象的哈希值冲突时,equals()方法决定了这些对象是否是“同一个对象”。所以,如果要将自定义的对象放入到LinkedHashMap或LinkedHashSet中,需要*@Override*hashCode()和equals()方法。
通过如下方式可以得到一个跟源Map 迭代顺序一样的LinkedHashMap:
void foo(Map m) {
Map copy = new LinkedHashMap(m);
...
}出于性能原因,LinkedHashMap是非同步的(not synchronized),如果需要在多线程环境使用,需要程序员手动同步;或者通过如下方式将LinkedHashMap包装成(wrapped)同步的: Map m = Collections.synchronizedMap(new LinkedHashMap(...));
方法剖析
(1) get()
get(Object key)方法根据指定的key值返回对应的value。该方法跟HashMap.get()方法的流程几乎完全一样,读者可自行参考前文,这里不再赘述。
(2) put()
put(K key, V value)方法是将指定的key, value对添加到map里。该方法首先会对map做一次查找,看是否包含该元组,如果已经包含则直接返回,查找过程类似于get()方法;如果没有找到,则会通过addEntry(int hash, K key, V value, int bucketIndex)方法插入新的entry。 注意,这里的插入有两重含义: 1.从table的角度看,新的entry需要插入到对应的bucket里,当有哈希冲突时,采用头插法将新的entry插入到冲突链表的头部。 2.从header的角度看,新的entry需要插入到双向链表的尾部。
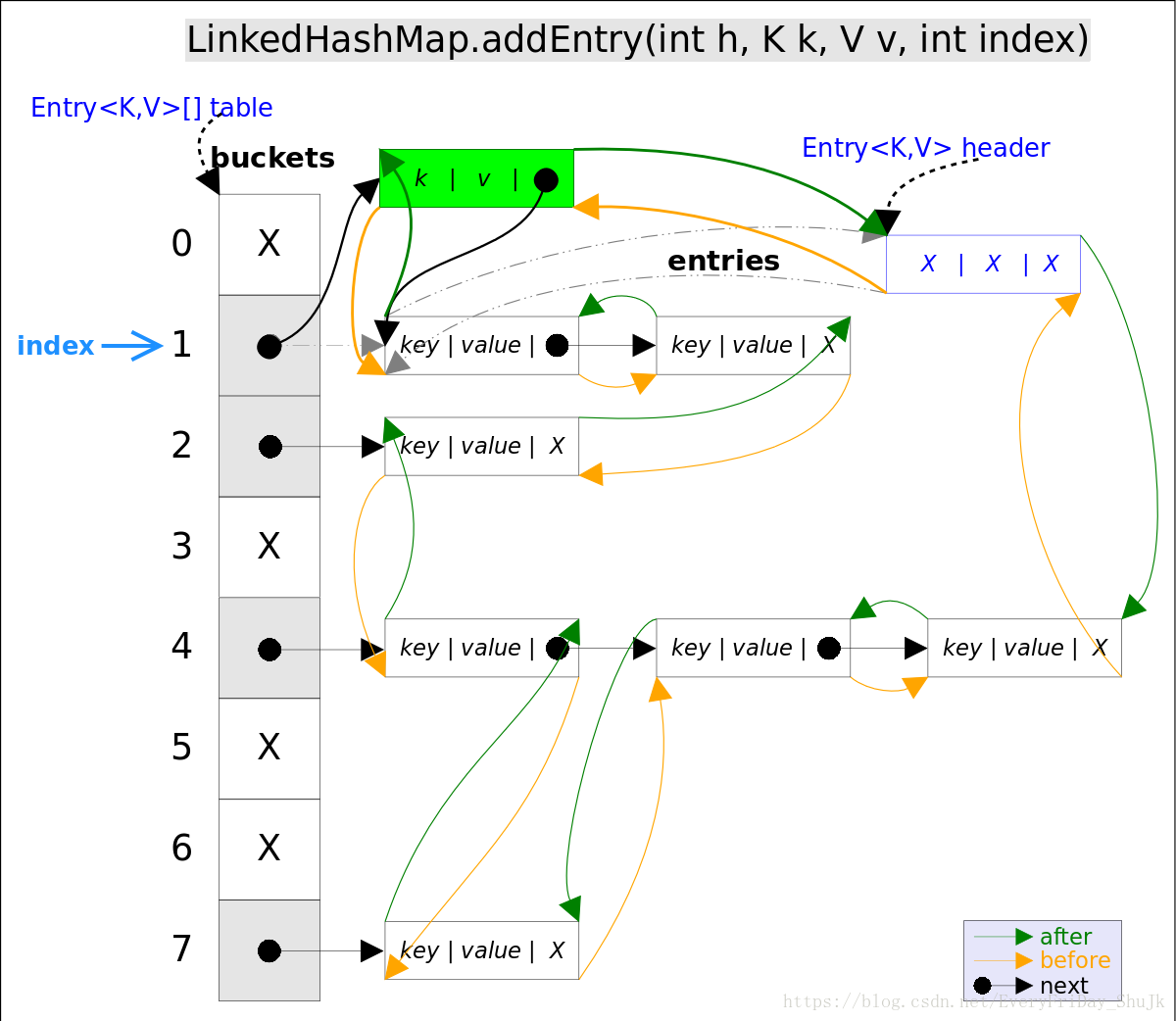
addEntry()代码如下:
// LinkedHashMap.addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);// 自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);// hash%table.length
}
// 1.在冲突链表头部插入新的entry
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
// 2.在双向链表的尾部插入新的entry
e.addBefore(header);
size++;
}上述代码中用到了addBefore()方法将新entry e插入到双向链表头引用header的前面,这样e就成为双向链表中的最后一个元素。addBefore()的代码如下:
// LinkedHashMap.Entry.addBefor(),将this插入到existingEntry的前面
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}上述代码只是简单修改相关entry的引用而已。
(3) remove()
remove(Object key)的作用是删除key值对应的entry,该方法的具体逻辑是在removeEntryForKey(Object key)里实现的。removeEntryForKey()方法会首先找到key值对应的entry,然后删除该entry(修改链表的相应引用)。查找过程跟get()方法类似。 注意,这里的删除也有两重含义: 1.从table的角度看,需要将该entry从对应的bucket里删除,如果对应的冲突链表不空,需要修改冲突链表的相应引用。 2.从header的角度来看,需要将该entry从双向链表中删除,同时修改链表中前面以及后面元素的相应引用。
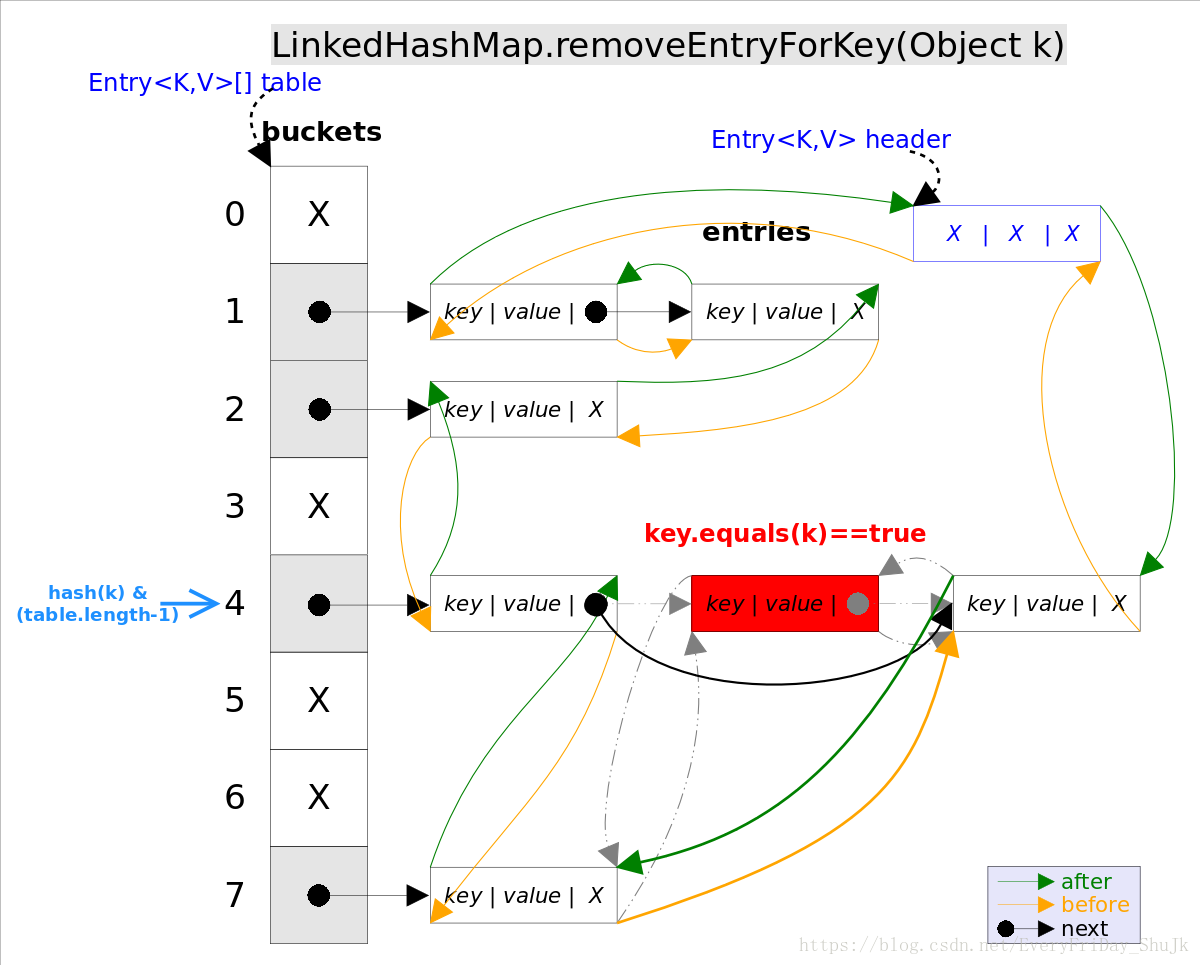
removeEntryForKey()对应的代码如下:
// LinkedHashMap.removeEntryForKey(),删除key值对应的entry
final Entry<K,V> removeEntryForKey(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);// hash&(table.length-1)
Entry<K,V> prev = table[i];// 得到冲突链表
Entry<K,V> e = prev;
while (e != null) {// 遍历冲突链表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {// 找到要删除的entry
modCount++; size--;
// 1. 将e从对应bucket的冲突链表中删除
if (prev == e) table[i] = next;
else prev.next = next;
// 2. 将e从双向链表中删除
e.before.after = e.after;
e.after.before = e.before;
return e;
}
prev = e; e = next;
}
return e;
}LinkedHashSet
前面已经说过LinkedHashSet是对LinkedHashMap的简单包装,对LinkedHashSet的函数调用都会转换成合适的LinkedHashMap方法,因此LinkedHashSet的实现非常简单,这里不再赘述。
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
......
// LinkedHashSet里面有一个LinkedHashMap
public LinkedHashSet(int initialCapacity, float loadFactor) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
......
public boolean add(E e) {//简单的方法转换
return map.put(e, PRESENT)==null;
}
......
}3、TreeSet 和 TreeMap
总体介绍
之所以把TreeSet和TreeMap放在一起讲解,是因为二者在Java里有着相同的实现,前者仅仅是对后者做了一层包装,也就是说TreeSet里面有一个TreeMap(适配器模式)。因此本文将重点分析TreeMap。 Java TreeMap实现了SortedMap接口,也就是说会按照key的大小顺序对Map中的元素进行排序,key大小的评判可以通过其本身的自然顺序(natural ordering),也可以通过构造时传入的比较器(Comparator)。 TreeMap底层通过红黑树(Red-Black tree)实现,也就意味着containsKey(), get(), put(), remove()都有着log(n)的时间复杂度。其具体算法实现参照了《算法导论》。
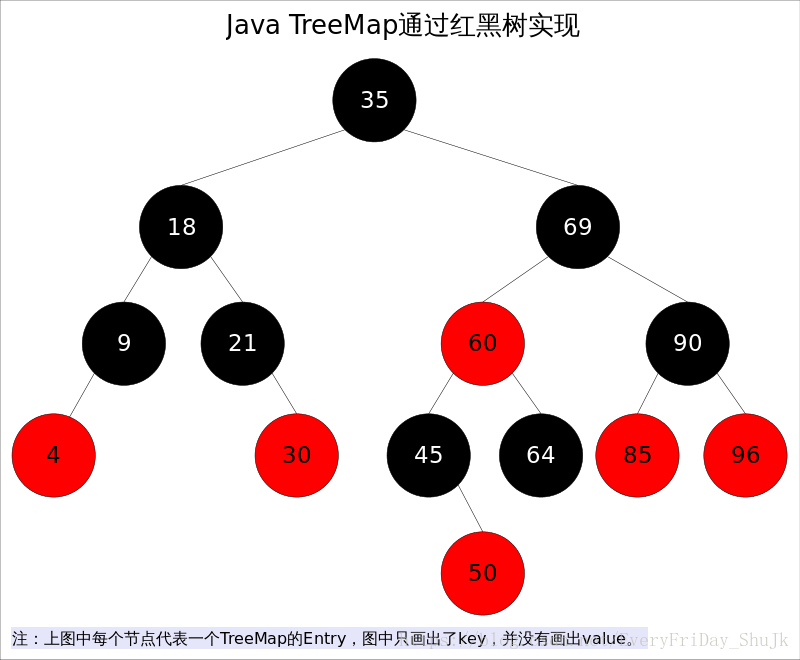
出于性能原因,TreeMap是非同步的(not synchronized),如果需要在多线程环境使用,需要程序员手动同步;或者通过如下方式将TreeMap包装成(wrapped)同步的: SortedMap m = Collections.synchronizedSortedMap(new TreeMap(...));
红黑树是一种近似平衡的二叉查找树,它能够确保任何一个节点的左右子树的高度差不会超过二者中较低那个的一陪。具体来说,红黑树是满足如下条件的二叉查找树(binary search tree): 1.每个节点要么是红色,要么是黑色。 2.根节点必须是黑色 3.红色节点不能连续(也即是,红色节点的孩子和父亲都不能是红色)。 4.对于每个节点,从该点至null(树尾端)的任何路径,都含有相同个数的黑色节点。 在树的结构发生改变时(插入或者删除操作),往往会破坏上述条件3或条件4,需要通过调整使得查找树重新满足红黑树的约束条件。
预备知识
前文说到当查找树的结构发生改变时,红黑树的约束条件可能被破坏,需要通过调整使得查找树重新满足红黑树的约束条件。调整可以分为两类:一类是颜色调整,即改变某个节点的颜色;另一类是结构调整,集改变检索树的结构关系。结构调整过程包含两个基本操作:左旋(Rotate Left),右旋(RotateRight)。
左旋 左旋的过程是将x的右子树绕x逆时针旋转,使得x的右子树成为x的父亲,同时修改相关节点的引用。旋转之后,二叉查找树的属性仍然满足。
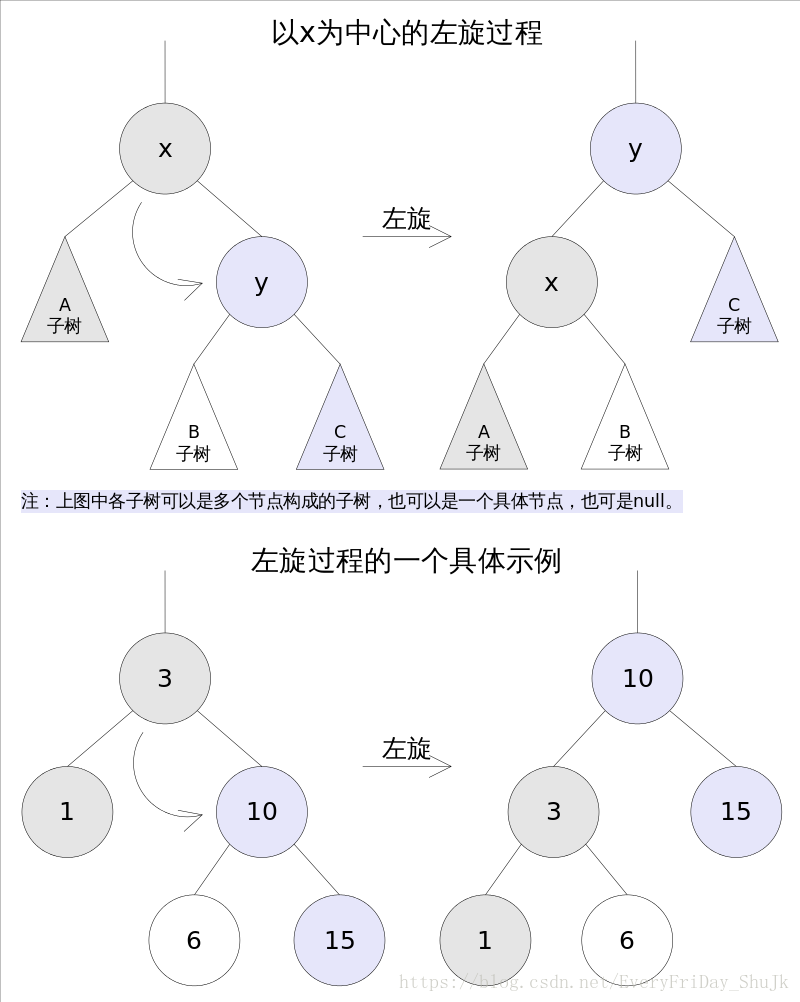
TreeMap中左旋代码如下:
//Rotate Left
private void rotateLeft(Entry<K,V> p) {
if (p != null) {
Entry<K,V> r = p.right;
p.right = r.left;
if (r.left != null)
r.left.parent = p;
r.parent = p.parent;
if (p.parent == null)
root = r;
else if (p.parent.left == p)
p.parent.left = r;
else
p.parent.right = r;
r.left = p;
p.parent = r;
}
}右旋 右旋的过程是将x的左子树绕x顺时针旋转,使得x的左子树成为x的父亲,同时修改相关节点的引用。旋转之后,二叉查找树的属性仍然满足。
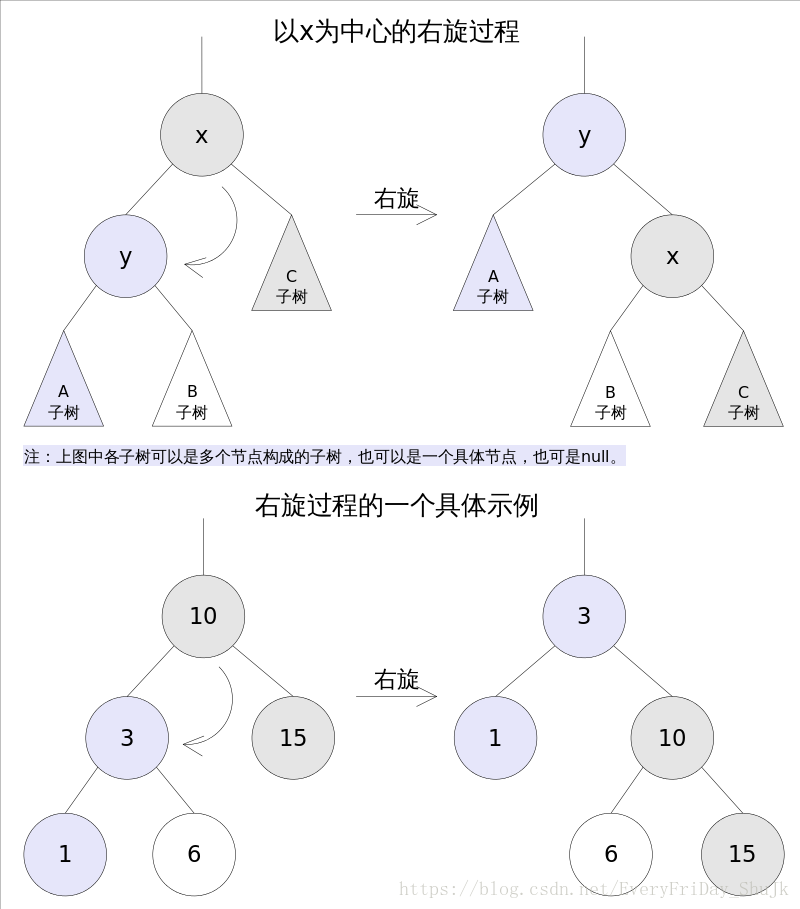
TreeMap中右旋代码如下:
//Rotate Right
private void rotateRight(Entry<K,V> p) {
if (p != null) {
Entry<K,V> l = p.left;
p.left = l.right;
if (l.right != null) l.right.parent = p;
l.parent = p.parent;
if (p.parent == null)
root = l;
else if (p.parent.right == p)
p.parent.right = l;
else p.parent.left = l;
l.right = p;
p.parent = l;
}
}寻找节点后继 对于一棵二叉查找树,给定节点t,其后继(树种比大于t的最小的那个元素)可以通过如下方式找到: 1.t的右子树不空,则t的后继是其右子树中最小的那个元素。 2.t的右孩子为空,则t的后继是其第一个向左走的祖先。 后继节点在红黑树的删除操作中将会用到。
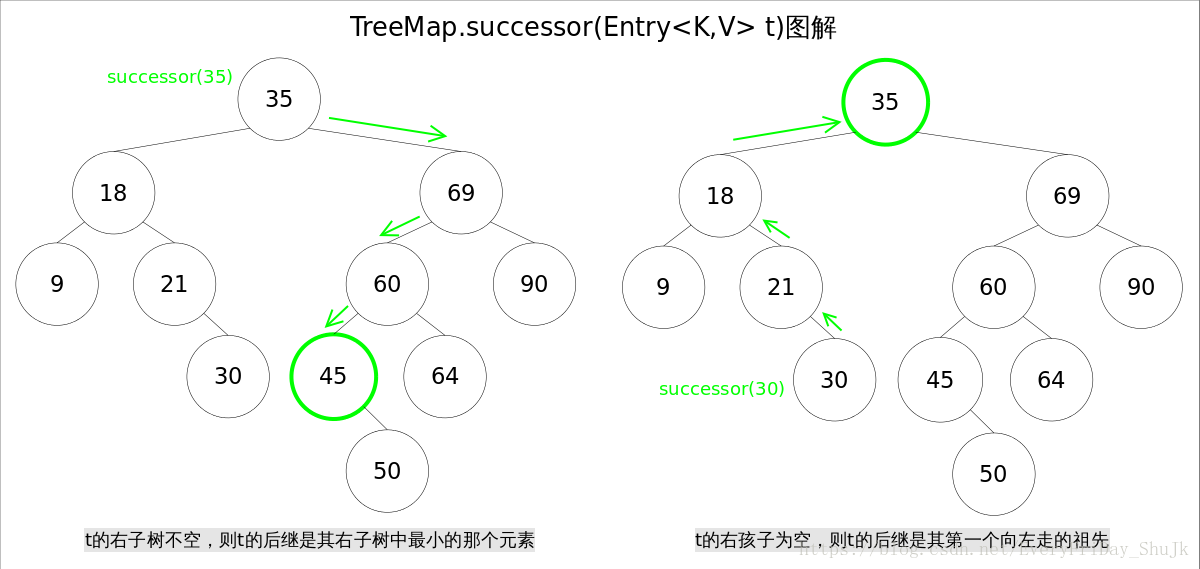
TreeMap中寻找节点后继的代码如下:
// 寻找节点后继函数successor()
static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) {
if (t == null)
return null;
else if (t.right != null) {// 1. t的右子树不空,则t的后继是其右子树中最小的那个元素
Entry<K,V> p = t.right;
while (p.left != null)
p = p.left;
return p;
} else {// 2. t的右孩子为空,则t的后继是其第一个向左走的祖先
Entry<K,V> p = t.parent;
Entry<K,V> ch = t;
while (p != null && ch == p.right) {
ch = p;
p = p.parent;
}
return p;
}
}方法剖析
(1) get()
get(Object key)方法根据指定的key值返回对应的value,该方法调用了getEntry(Object key)得到相应的entry,然后返回entry.value。因此getEntry()是算法的核心。算法思想是根据key的自然顺序(或者比较器顺序)对二叉查找树进行查找,直到找到满足k.compareTo(p.key) == 0的entry。
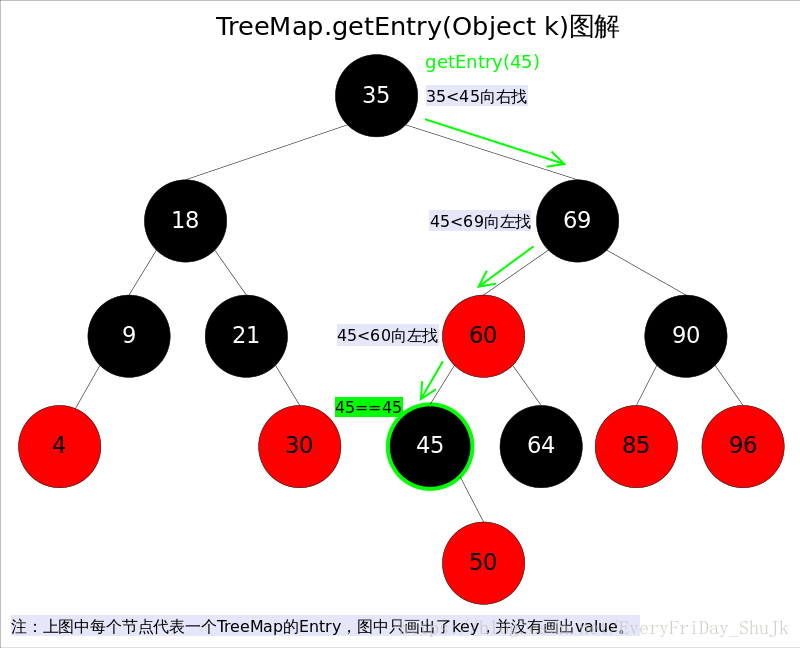
具体代码如下:
//getEntry()方法
final Entry<K,V> getEntry(Object key) {
......
if (key == null)//不允许key值为null
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;//使用元素的自然顺序
Entry<K,V> p = root;
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)//向左找
p = p.left;
else if (cmp > 0)//向右找
p = p.right;
else
return p;
}
return null;
}(2) put()
put(K key, V value)方法是将指定的key, value对添加到map里。该方法首先会对map做一次查找,看是否包含该元组,如果已经包含则直接返回,查找过程类似于getEntry()方法;如果没有找到则会在红黑树中插入新的entry,如果插入之后破坏了红黑树的约束条件,还需要进行调整(旋转,改变某些节点的颜色)。
public V put(K key, V value) {
......
int cmp;
Entry<K,V> parent;
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;//使用元素的自然顺序
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0) t = t.left;//向左找
else if (cmp > 0) t = t.right;//向右找
else return t.setValue(value);
} while (t != null);
Entry<K,V> e = new Entry<>(key, value, parent);//创建并插入新的entry
if (cmp < 0) parent.left = e;
else parent.right = e;
fixAfterInsertion(e);//调整
size++;
return null;
}上述代码的插入部分并不难理解:首先在红黑树上找到合适的位置,然后创建新的entry并插入(当然,新插入的节点一定是树的叶子)。难点是调整函数fixAfterInsertion(),前面已经说过,调整往往需要1.改变某些节点的颜色,2.对某些节点进行旋转。
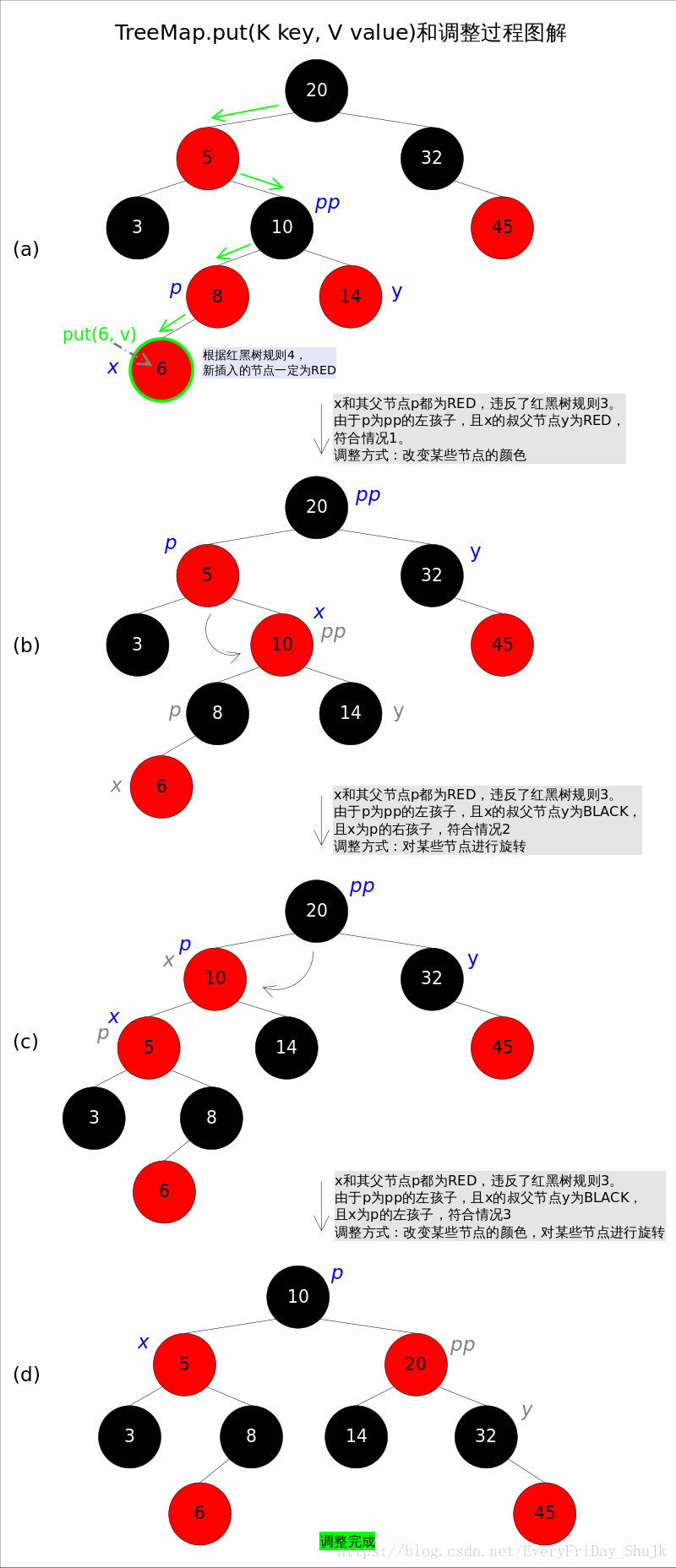
调整函数fixAfterInsertion()的具体代码如下,其中用到了上文中提到的rotateLeft()和rotateRight()函数。通过代码我们能够看到,情况2其实是落在情况3内的。情况4~情况6跟前三种情况是对称的,因此图解中并没有画出后三种情况,读者可以参考代码自行理解。
//红黑树调整函数fixAfterInsertion()
private void fixAfterInsertion(Entry<K,V> x) {
x.color = RED;
while (x != null && x != root && x.parent.color == RED) {
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
Entry<K,V> y = rightOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK); // 情况1
setColor(y, BLACK); // 情况1
setColor(parentOf(parentOf(x)), RED); // 情况1
x = parentOf(parentOf(x)); // 情况1
} else {
if (x == rightOf(parentOf(x))) {
x = parentOf(x); // 情况2
rotateLeft(x); // 情况2
}
setColor(parentOf(x), BLACK); // 情况3
setColor(parentOf(parentOf(x)), RED); // 情况3
rotateRight(parentOf(parentOf(x))); // 情况3
}
} else {
Entry<K,V> y = leftOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK); // 情况4
setColor(y, BLACK); // 情况4
setColor(parentOf(parentOf(x)), RED); // 情况4
x = parentOf(parentOf(x)); // 情况4
} else {
if (x == leftOf(parentOf(x))) {
x = parentOf(x); // 情况5
rotateRight(x); // 情况5
}
setColor(parentOf(x), BLACK); // 情况6
setColor(parentOf(parentOf(x)), RED); // 情况6
rotateLeft(parentOf(parentOf(x))); // 情况6
}
}
}
root.color = BLACK;
}remove(Object key)的作用是删除key值对应的entry,该方法首先通过上文中提到的getEntry(Object key)方法找到key值对应的entry,然后调用deleteEntry(Entry
// 红黑树entry删除函数deleteEntry()
private void deleteEntry(Entry<K,V> p) {
modCount++;
size--;
if (p.left != null && p.right != null) {// 2. 删除点p的左右子树都非空。
Entry<K,V> s = successor(p);// 后继
p.key = s.key;
p.value = s.value;
p = s;
}
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
if (replacement != null) {// 1. 删除点p只有一棵子树非空。
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
p.left = p.right = p.parent = null;
if (p.color == BLACK)
fixAfterDeletion(replacement);// 调整
} else if (p.parent == null) {
root = null;
} else { // 1. 删除点p的左右子树都为空
if (p.color == BLACK)
fixAfterDeletion(p);// 调整
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}上述代码中占据大量代码行的,是用来修改父子节点间引用关系的代码,其逻辑并不难理解。下面着重讲解删除后调整函数fixAfterDeletion()。首先请思考一下,删除了哪些点才会导致调整?只有删除点是BLACK的时候,才会触发调整函数,因为删除RED节点不会破坏红黑树的任何约束,而删除BLACK节点会破坏规则4。 跟上文中讲过的fixAfterInsertion()函数一样,这里也要分成若干种情况。记住,无论有多少情况,具体的调整操作只有两种:1.改变某些节点的颜色,2.对某些节点进行旋转。
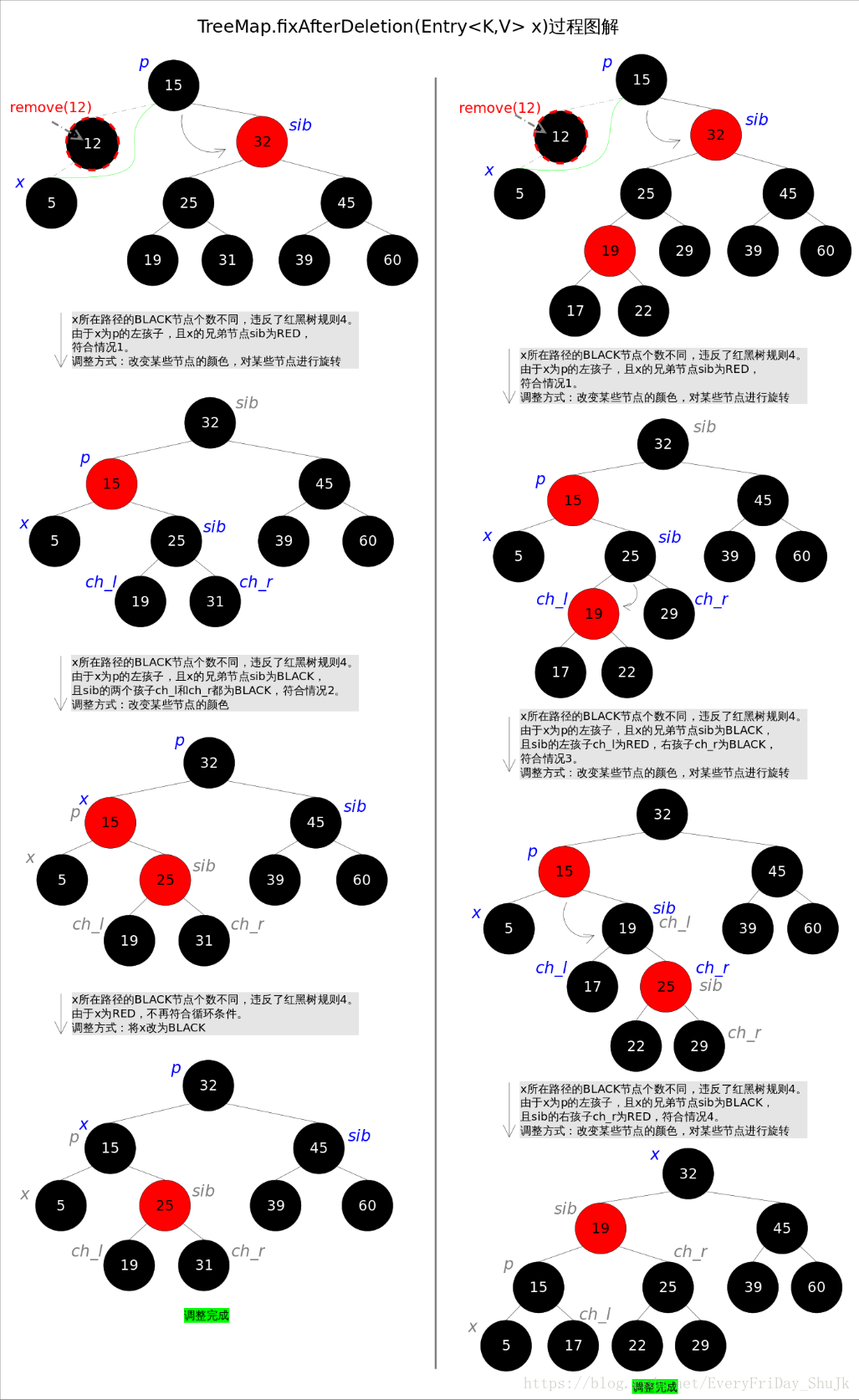
上述图解的总体思想是:将情况1首先转换成情况2,或者转换成情况3和情况4。当然,该图解并不意味着调整过程一定是从情况1开始。通过后续代码我们还会发现几个有趣的规则:a).如果是由情况1之后紧接着进入的情况2,那么情况2之后一定会退出循环(因为x为红色);b).一旦进入情况3和情况4,一定会退出循环(因为x为root)。 删除后调整函数fixAfterDeletion()的具体代码如下,其中用到了上文中提到的rotateLeft()和rotateRight()函数。通过代码我们能够看到,情况3其实是落在情况4内的。情况5~情况8跟前四种情况是对称的,因此图解中并没有画出后四种情况,读者可以参考代码自行理解。
private void fixAfterDeletion(Entry<K,V> x) {
while (x != root && colorOf(x) == BLACK) {
if (x == leftOf(parentOf(x))) {
Entry<K,V> sib = rightOf(parentOf(x));
if (colorOf(sib) == RED) {
setColor(sib, BLACK); // 情况1
setColor(parentOf(x), RED); // 情况1
rotateLeft(parentOf(x)); // 情况1
sib = rightOf(parentOf(x)); // 情况1
}
if (colorOf(leftOf(sib)) == BLACK &&
colorOf(rightOf(sib)) == BLACK) {
setColor(sib, RED); // 情况2
x = parentOf(x); // 情况2
} else {
if (colorOf(rightOf(sib)) == BLACK) {
setColor(leftOf(sib), BLACK); // 情况3
setColor(sib, RED); // 情况3
rotateRight(sib); // 情况3
sib = rightOf(parentOf(x)); // 情况3
}
setColor(sib, colorOf(parentOf(x))); // 情况4
setColor(parentOf(x), BLACK); // 情况4
setColor(rightOf(sib), BLACK); // 情况4
rotateLeft(parentOf(x)); // 情况4
x = root; // 情况4
}
} else { // 跟前四种情况对称
Entry<K,V> sib = leftOf(parentOf(x));
if (colorOf(sib) == RED) {
setColor(sib, BLACK); // 情况5
setColor(parentOf(x), RED); // 情况5
rotateRight(parentOf(x)); // 情况5
sib = leftOf(parentOf(x)); // 情况5
}
if (colorOf(rightOf(sib)) == BLACK &&
colorOf(leftOf(sib)) == BLACK) {
setColor(sib, RED); // 情况6
x = parentOf(x); // 情况6
} else {
if (colorOf(leftOf(sib)) == BLACK) {
setColor(rightOf(sib), BLACK); // 情况7
setColor(sib, RED); // 情况7
rotateLeft(sib); // 情况7
sib = leftOf(parentOf(x)); // 情况7
}
setColor(sib, colorOf(parentOf(x))); // 情况8
setColor(parentOf(x), BLACK); // 情况8
setColor(leftOf(sib), BLACK); // 情况8
rotateRight(parentOf(x)); // 情况8
x = root; // 情况8
}
}
}
setColor(x, BLACK);
}TreeSet
前面已经说过TreeSet是对TreeMap的简单包装,对TreeSet的函数调用都会转换成合适的TreeMap方法,因此TreeSet的实现非常简单。这里不再赘述。
// TreeSet是对TreeMap的简单包装
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
......
private transient NavigableMap<E,Object> m;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public TreeSet() {
this.m = new TreeMap<E,Object>();// TreeSet里面有一个TreeMap
}
......
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
......
}
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









