




 本文探讨了线程并发控制中的线程互斥问题,指出处理器的乱序执行可能导致并发错误。文章通过例子说明了如何利用原子指令如`lock add`来保证指令的顺序性、原子性和可见性,以确保多线程环境下代码的正确性。同时,介绍了x86架构下的`xchg`指令用于实现简单的互斥锁,并提供了简化版的锁算法实现。
本文探讨了线程并发控制中的线程互斥问题,指出处理器的乱序执行可能导致并发错误。文章通过例子说明了如何利用原子指令如`lock add`来保证指令的顺序性、原子性和可见性,以确保多线程环境下代码的正确性。同时,介绍了x86架构下的`xchg`指令用于实现简单的互斥锁,并提供了简化版的锁算法实现。










看线程1,load(y)前面的是和y无关的store,所以操作系统允许store和load乱序。
这就使得实际可能是,线程1先执行load(y),线程2先执行load(x),然后分别进入(if !t1) goto,t1和t2同时进入临界区,所以Peterson算法出错。
Perterson算法在现代计算机上实际上是错误的

在do_sum代码中使用了内联汇编,使得其真正循环相加,彻底阻止了编译器的优化。

如果我们的状态机在每一个时刻,确实是执行一个线程的一条汇编指令的话,我们应该看到正确的值4n

这个结果就推翻了上面写的那个上节课的假设(状态机每一时刻执行一条指令),而要改为这节课的假设——指令每个时刻只能执行一个load/store或者一些线程本地的计算,如果一个x86的指令里面包含超过一个load/store,那么就会拆成若干条指令执行,每一个指令最多只能load一次或者store一次。
那么进入结果的解释:
一条add指令拆分成 t=load(x);t++;store(x,t),这样的话结果就位于区间(n,4n]之间了,但是为什么也有小于n的情况。
下面进入进一步的解释:
每一个处理器都有一个写队列
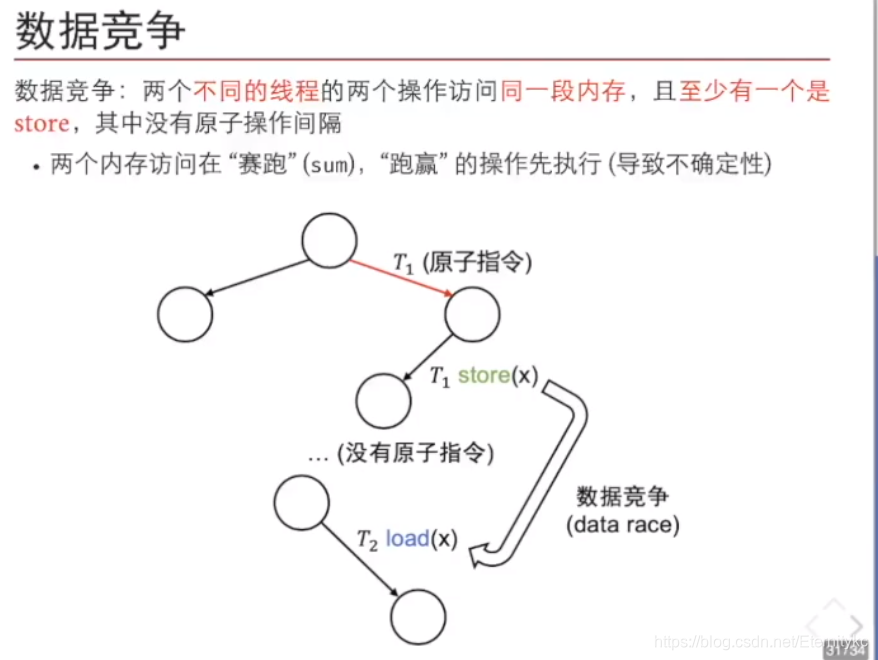
store buffer,每次对x的store,不会立即写入内存,而是首先写入store buffer,运行时,那个队列写入x=1,x=2,x=3…。而我们在load的时候,只有当buffer里没有x时,才会去cpu 外面读,若存在buffer中直接从buffer中读取。store buffer里的数值不是立即写入内存,而是按照1,2,3…这个写入的顺序写入内存。(例如x=1,实际上会写出cpu )。而写出cpu不是立即到达共享的内存中,而是到达cpu的缓存中。如果这时线程1在cpu1上已经完成了x=1,x=2,x=3的写入,但是有可能所有的数值都还留在store buffer中,当我们的线程2在另一个cpu上执行load,会去共享内存中读取,线程2会读到sum=0,所以在线程1上完成了3次sum++的操作,但是在线程2看不到这个操作,因此sum<n就很合理了。
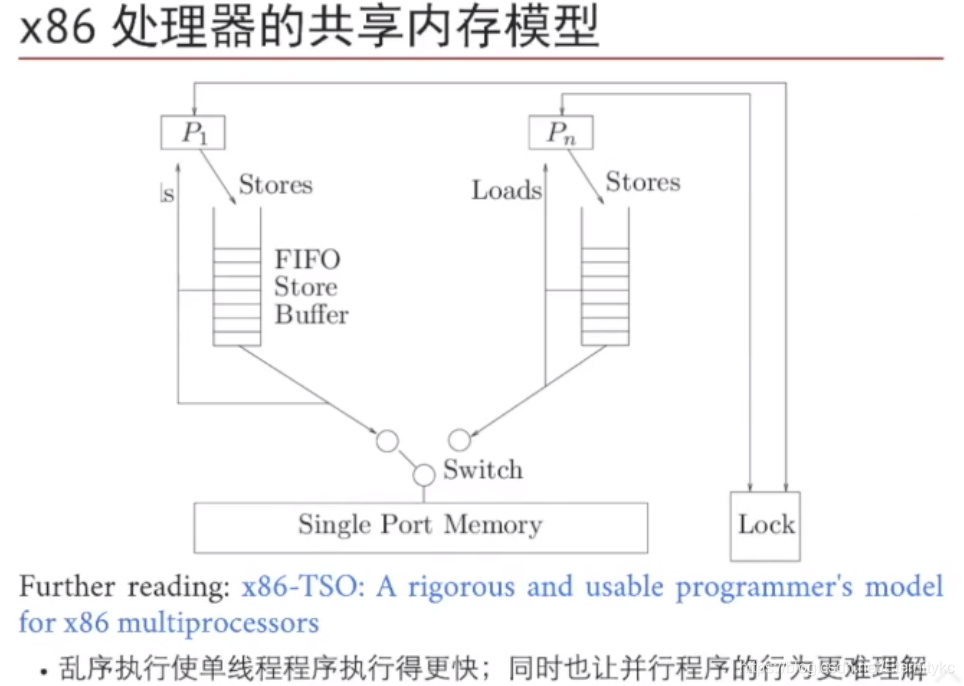
多处理器设计这么复杂完全是为了单线程执行更快而设计的,像store buffer,cache,但是这就让多线程的运行难以理解。
上一节课中,状态机每一步执行一个指令的假设被推翻。一条指令会分解成若干条更小的指令,处理器的乱序会得到奇怪的结果。

如果硬件提供一点点更多的支持,在多处理器上实现互斥就变得非常容易。

如果硬件能提供一些指令帮我们就好了。

刚才提到,在共享内存上实现互斥,只能使用load,store,和线程本地计算。而load和store本身是存在能力上的缺陷的。
例如load环顾四周,只能看不能写,而且每次只能看内存里的一个地址
而store在改变物理世界状态的时候,不能读,只能把眼睛蒙起来动手。这时候这个动手成功没有,在动手的期间有没有别的线程再动过手,这都是不知道的。
再加上现代多处理器上load和store执行时可能乱序,就更复杂了。
上面那个是有着明显错误的锁实现,如果状态[IP1,IP2,locked]=[2,2,0](即if判断成功进入了那个if,这个时候后面可以同时进入临界区。

如果能保证load和store这中间不被打断,就不会出现[2,2,0]的情况,就可以保证这段程序的正确性。
这种指令叫做:test-and-set
t=load(locked);
if (t == 0) store(locked,1);
实际上我们的硬件我们提供了很多的原子指令.

能保证
原子性(这样一条指令不会被打断)
能保证顺序以及多处理器间的可见性。
能保证在原子指令之前所有的store会在其他的处理器之间可见,以及这样的一条原子指令能保证在这个指令前后的load和store不能被乱序,所以保证了内存访问的顺序
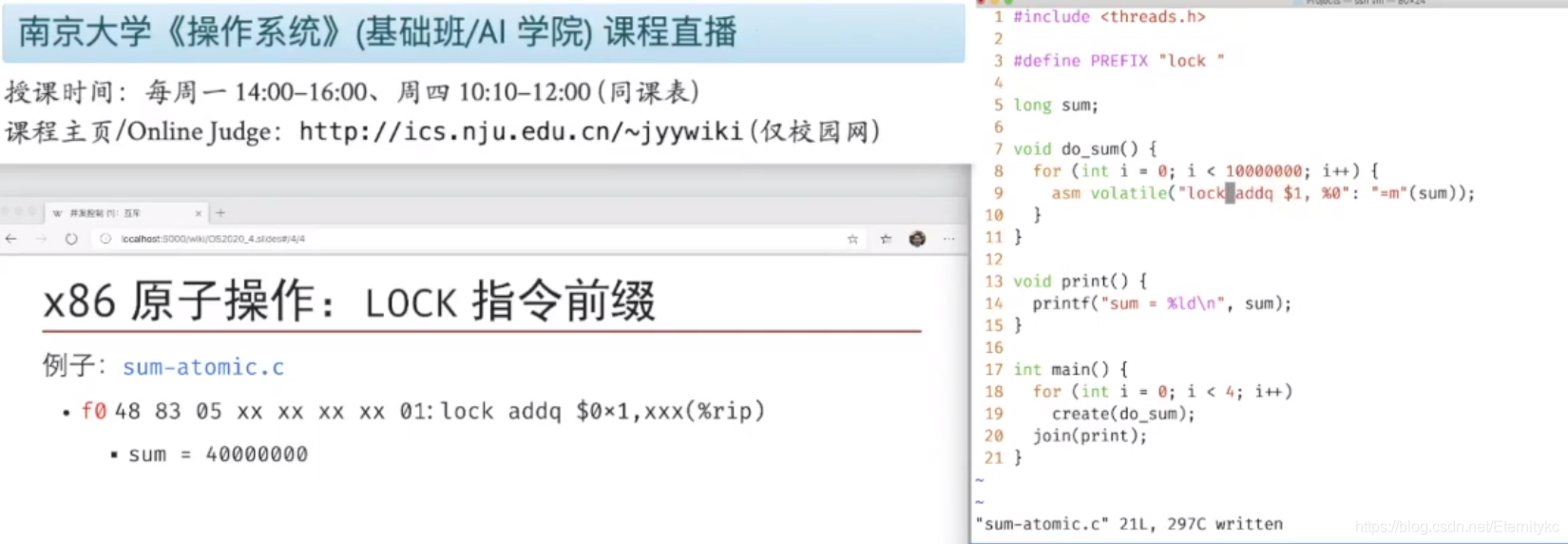
上述代码在addq上添加了一个lock
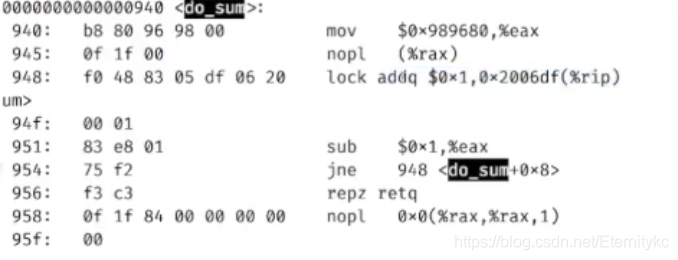
和前面相比,就多了一个lock,然后指令开头多了一个f0,表示这个指令需要锁定,我们的CPU在访问这条指令的时候就可以保证原子性,顺序性和可见性,因此运行时的到了正确的结果4n。
命令time ./a.out,得到这个运行的结果是0.422s。
而之前那个错误的指令是0.043s,在原子指令调用比较密集的情况下,可能会有10倍甚至更多的性能差距
为了实现互斥锁,x86给我们提供了xchg指令(英文原单词应该是exchange交换).

xchg将传入的内存地址addr的值和传入的参数newval的值做交换,他将瞬间完成*addr 和 newval数值的交换,不会被其他处理器打断,原子完成

把线程想象成人,物理世界想象为共享内存,看上面的ppt,非常清楚。于是我们可以实现os课上的地一个锁算法——自旋锁。
所谓的自旋spin来自量子力学,量子不断地旋转,交换交换交换
直到换到了一把钥匙,进入,所以成为自旋锁。

可以改写成一段非常精简的代码:
可以把tabel重命名为locked,Key=0,NOTE=1
改写成->:
while (1){
int ret = xchg(locked,1);
if (ret == 0) break;
}
可以进一步改写成:
while( xchg(locked,1) ) ;




对内存中x这个地址做标记,让它归属某一个CPU,表示被这个CPU盯上了,之后store x的时候检查是不是那个盯上的CPU,如果是的话那返回SUCC,如果不是的话,那就返回FAILE。




















 390
390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









