



 本文详细介绍了MySQL数据库的安装步骤及基本配置方法,并提供了创建、查询、修改数据库和数据表的具体操作示例。
本文详细介绍了MySQL数据库的安装步骤及基本配置方法,并提供了创建、查询、修改数据库和数据表的具体操作示例。
下载
下载地址:https://dev.mysql.com/downloads/mysql/
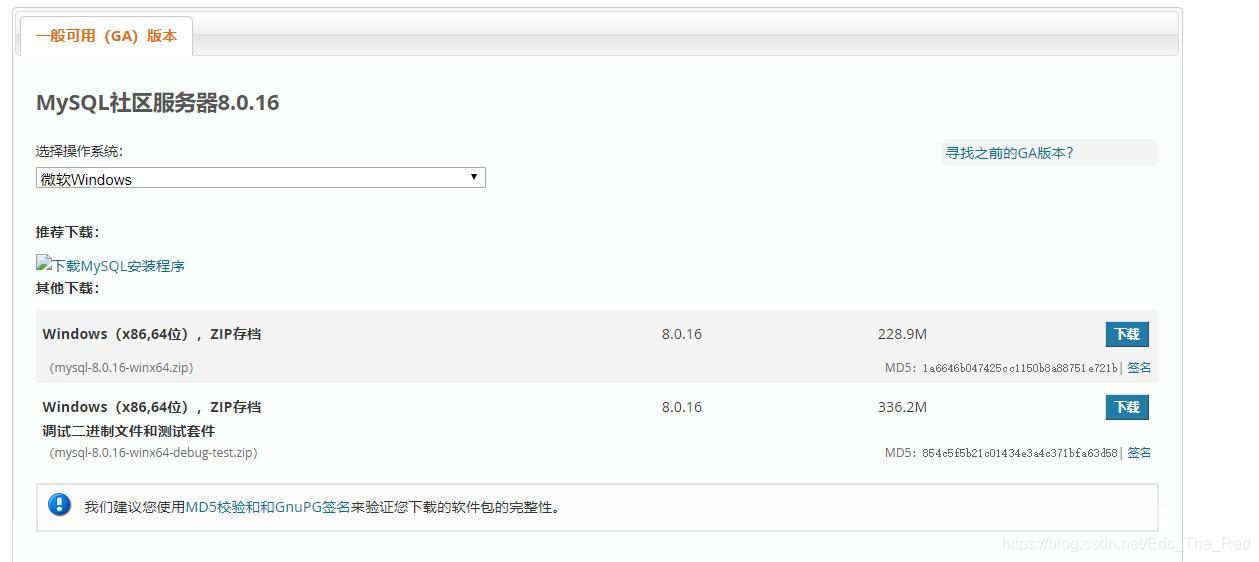
我们选择64位的下载
使用前的配置
下载后先解压
1.my.ini
在解压后的文件夹下新建一个my.ini文本文件
然后打开my.ini文件,配置信息如下:
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[mysqld]
#设置3306端口
port = 3306
# 设置mysql的安装目录
basedir=F:\MySQL\mysql8
# 设置mysql数据库的数据的存放目录
datadir=F:\MySQL\mysql8\data
# 允许最大连接数
max_connections=200
# 允许连接失败的次数。这是为了防止有人从该主机试图攻击数据库系统
max_connect_errors=20
# 服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
# 有新的配置信息继续在这里添加
bind-address=127.0.0.1
2.启动MySQL
打开命令行,进入文件夹的bin目录,然后输入:
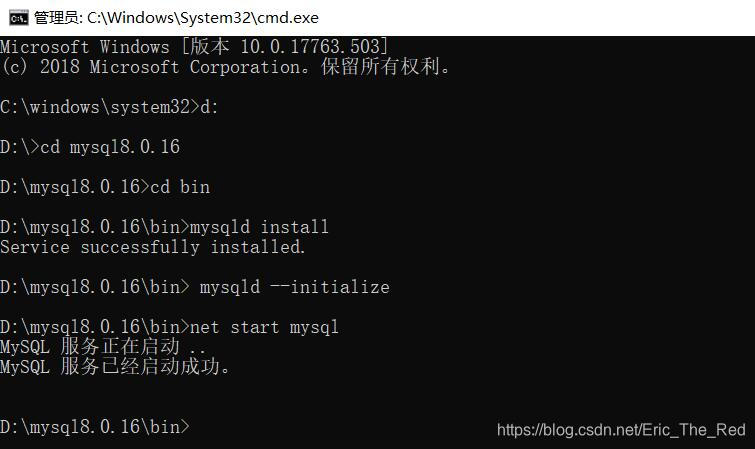
mysqld install
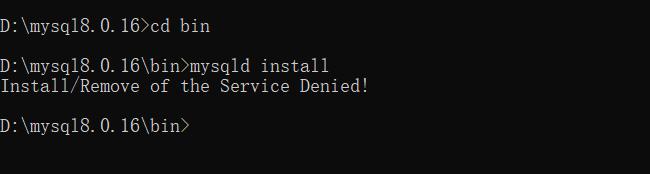
出现Install/Remove of the Service Denied!
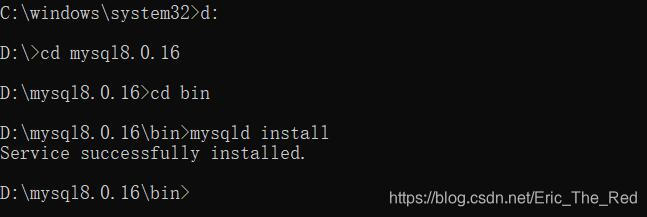
查了一下一下,是权限问题,进入系统盘找到C:\Windows\System32\cmd.exe右键以管理员身份运行 再次进入相应目录执行
mysqld -install 显示Service successfully installed
进入到mysql的bin目录下,输入命令初始化data文件夹(很重要)
mysqld --initialize
然后启动服务:
net start mysql
3.配置环境变量
复制bin目录 的地址,添加到path变量:

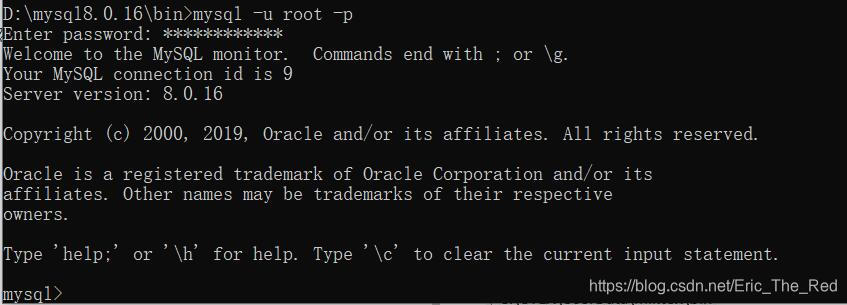
进入MySQL
打开data文件夹中的LAPTOP-K2HGBEO5.err文件,复制初始密码。然后在命令行输入:mysql -u root -p
然后复制上初始密码:
然后更改密码:输入 alter user user() identified by ‘new password’

这样,使用之前的基本配置工作就完成了。
MySQL的操作语句和方法
(首先,固定语句不区分大小写)
1.链接数据库
上文已经展示了,在启动数据库后输入:
mysql -u root -p
然后输入密码即可。
2.创建数据库
create database 数据库名;
实例1:最简单的创建 MySQL 数据库的语句
在 MySQL 中创建一个名为 test_db 的数据库,输入的 SQL 语句与执行结果如下:

补充说明:为防止字符混乱的情况发生,MySQL 有时需要在创建数据库时明确指定字符集;在中国大陆地区,常用的字符集有 utf8 和 gbk:
---------> utf8 能够存储全球的所有字符,在任何国家都可以使用,默认的校对规则为 utf8_general_ci,对于中文可以使用 utf8_general_ci。
---------> gbk 只能存储汉语涉及到的字符,不具有全球通用性,默认的校对规则为 gbk_chinese_ci。
所以如果在创建数据库时要指定字符集和校对规则,语句如下:
create database test_db_char;
default character set utf8;
default collate utf8_chinese_ci;
3.查看数据库
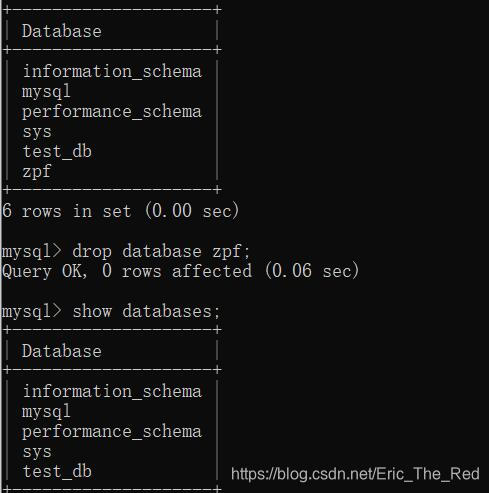
show databases;

//使用 LIKE 从句,查看与 test_db 完全匹配的数据库
show databases like 'test_db';
// 使用 LIKE 从句,查看名字中包含 test 的数据库
show databases like '%test%';
使用 LIKE 从句,查看名字以 db 开头的数据库
show databases like 'db%';
使用 LIKE 从句,查看名字以 db 结尾的数据库
show databases like '%db';
4.选择数据库
use 数据库名;
5.删除数据库
drop database 数据库名;
数据表的相关基本操作
1.创建数据表
create table <表名> ([表定义选项])[表选项][分区选项];
其中,[表定义选项]的格式为:
<列名1> <类型1> [,…] <列名n> <类型n>
举例:

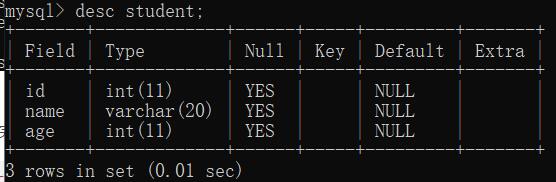
创建完表可以查询表的结构:
desc 表名;
2.插入数据
- INSERT…VALUES语句
insert into 表名 (列名1,列名2,列名3..............)
values (值1,值2,值3.........);
或
insert into 表名 values (值1,值2,值3.........);
举例:

3.查询数据表
基本的查询:
select * from 表名;
select field1, field2...from 表名;

查询时指定别名的语句
(临时的)
SELECT ,字段 AS '别名' FROM 表名;
查询时添加常量列
(临时使用的列)
举例:
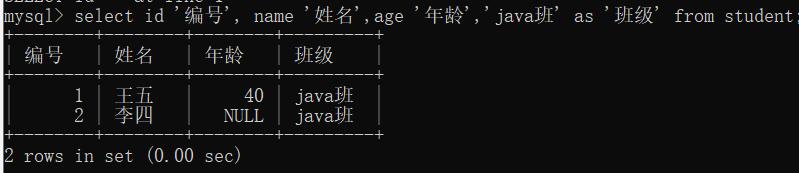
select id '编号', name '姓名',age '年龄','java班' as '班级' from student;
查询时合并列
举例:
SELECT NAME '姓名',(servlet+jsp) '总成绩' FROM student;
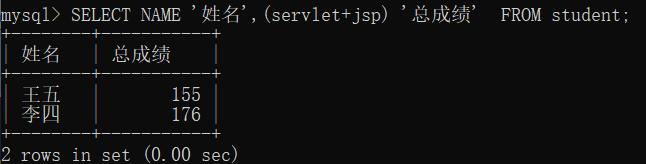
注意,只有数据类型是数值时才有意义。
查询去除重复数据
举例:统计学生来自哪里(不重复)
SELECT DISTINCT address FROM student;

单一条件的查询语句
假设有如下数据表:
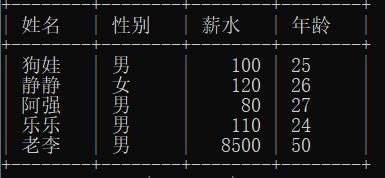
在表 employee 中查询薪水为 110的员工的姓名,输入的 SQL 语句和行结果如下所示
select 姓名,薪水 from employee
where 薪水=8500;

多条件的查询语句
在表 employee 中查询薪水小于120且年龄小于26的员工的姓名,输入的 SQL 语句和行结果如下所示
select * from employee
where 薪水<120 and 年龄<26;

如果是:
select * from employee
where 薪水<120 or 年龄<26;
则两个判定条件满足一个即可。
还有一种特别情况是判空条件:
注意null 和 空字符串的区别(<>是不等号)
-null: 没有数据。 判断null: is null,判断不为null: is not null
- 空字符: 有数据,数据就是空字符串。判断空字符: =’’; 判断不为空字符串: <>’’;
聚合查询
现有表如下:
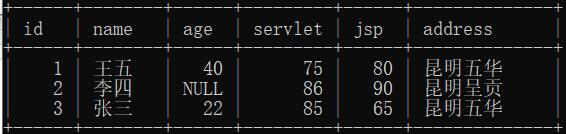
– 需求: 查询所有学生servlet的总分 (SUM: 求和函数)
SELECT SUM(servlet) FROM student;
– 需求: 查询所有学生servlet的平均分(AVG; 平均函数)
SELECT AVG(servlet) FROM student;
– 需求:查询最高的servlet分数(MAX:最大值函数)
SELECT MAX(servlet) FROM student;
– 需求:查询最低的servlet分数(MIN:最小值函数)
SELECT MIN(servlet) FROM student;


需求: 一共几个学生(COUNT: 统计数量函数)
SELECT COUNT(*) FROM student;
SELECT COUNT(id) FROM student; -- 效率会比count(*)效率稍高
(注意: 聚合函数,会排除null值的数据)
分页查询
需求: 查询第一条和第二条数据
(注意:格式为:limit 起始行数,查询的总行数
且起始行数从0开始)
select * from student limit 0,2;
结论-----分页查询当前页数据的sql: select * from student limit (当前页码-1)*每页显示条数,每页显示条数;
查询后排序
– desc: 降序。数值从大到小,字母z-a
– asc: 升序。数值从小到大,字母a-z
– 默认情况下,按照插入的顺序排序
– 需求:按照id的升序排序
SELECT * FROM student ORDER BY id ASC;
– 需求: 按照servlet成绩降序排序
SELECT * FROM student ORDER BY servlet DESC;
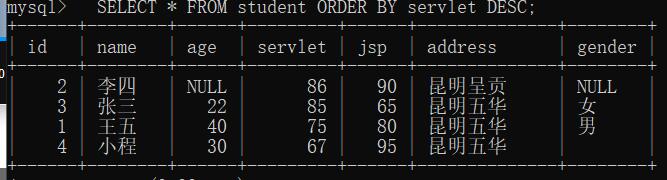
多个排序条件的情况:先按照前面的条件排序,当出现重复记录,再按照后面的条件排序。
– 需求: 按照age升序,按照servlet成绩升序排序
SELECT * FROM student ORDER BY age ASC,servlet ASC;
分组查询(group by)
– 需求: 查询每个地区有多少人
方法:1)对地区进行分组 2)在分组的基础可以进行统计,统计的是每组的数据
SELECT address,COUNT(*) FROM student GROUP BY address;

–需求: 统计男女的人数
SELECT gender,COUNT(*) FROM student WHERE gender IS NOT NULL AND gender<>'' GROUP BY gender;
分组后筛选(having)
需求:分组查询后筛选哪些地区的人数大于2个的地区
SELECT address,COUNT(*) FROM student GROUP BY address HAVING COUNT(*)>2 ;
4.删除数据表
drop table 表名;
5.修改数据表
基本的语法
常用的语法格式如下:
ALTER TABLE 表名 [修改选项]
修改选项的语法格式如下:
{ ADD COLUMN <列名> <类型>
| CHANGE COLUMN <旧列名> <新列名> <新列类型>
| ALTER COLUMN <列名> { SET DEFAULT <默认值> | DROP DEFAULT }
| MODIFY COLUMN <列名> <类型>
| DROP COLUMN <列名>
| RENAME TO <新表名> }
总结
修改表:
(1)修改时添加字段:alter table 表名 add 字段 字段类型 ;
(2)修改字段类型的大小:alter table 表名 modify 表字段 字段类型;
(3)修改表名: alter table 表名 rename to 新表名;
(4)修改列名 : alter table 表名 change 字段 新字段 新字段类型;
添加字段及修改表中数据的举例
alter table 表名
-> add 字段名 字段类型 after 要跟随的字段名;
比如,添加age列:
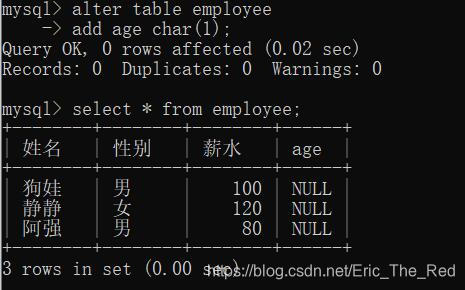
给age列赋值:
update 表名
-> set age=赋的值;

把第四行的(姓名,性别,薪水赋予新的值):
先将狗娃,静静,阿强的年龄分别改为25,26,27
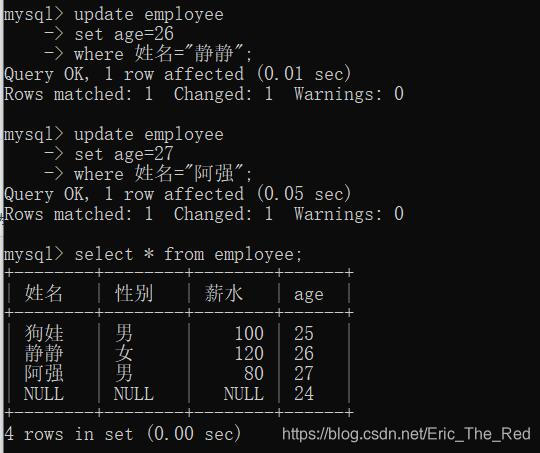
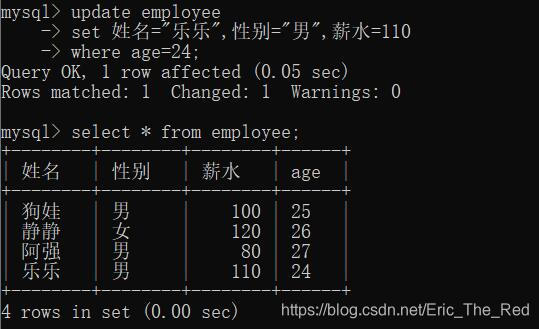
然后把第四行的姓名,性别,薪水赋值:
update employee
set 姓名="乐乐",性别="男",薪水=110
where age=24;
修改数据类型
现在薪水列的数据类型范围过小,,我们改一下:
alter table employee
modify 薪水 int;
这样,我们就可以把薪水改成较大的整数值了,比如将老李的薪水改为8500:
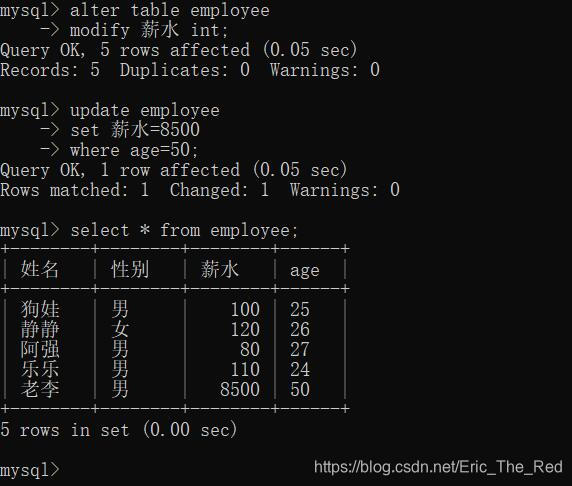
修改字段名称
alter table employee
change age 年龄 char(20);
将age改为了年龄:
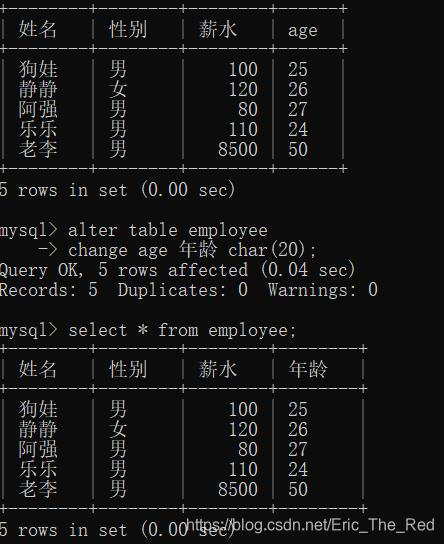
6.删除数据
删除字段名称
alter table 表名 drop column 字段;
删除具体的某项数据
(注意:用delete删除数据只能删除表中的数据,不能影响表中的自增长约束;另外,使用delete删除的数据,通过事务可以回滚。)
DELETE FROM 表名 WHERE 条件;
(注意:用truncate既能删除表的数据,也能够把表的自增长约束置为0;另外,使用truncate删除的数据不能回滚;其次,truncate与delete不同,后面不能带条件)
TRUNCATE TABLE 表名;
7.字段类型的介绍与比较
– char(20) vs varchar(20)
– char(20): 固定长度的字符串。不管实际存储的数据的大小,一定占用20个字符空间
– varchar(20): 可变长度的字符串。占用的空间大小就是实际存储的数据大小。
– int vs int(4)
– int: 默认最多11位,长度根据实际存储的数值的长度
– int(4): 固定的数组长度
– date vs datetime vs timestamp
– date: 日期
– datetime: 日期+时间
– timestamp: 时间戳,用于记录当前数据的插入或更新的时间
8.小结
管理数据库:
增: create database 数据库名 default character set 字符集;
修: alter database 数据库名 default character set 新的字符集;
删: drop database 数据库名;
查: show databases;
管理表:
增: create table 表名(字段名1 字段类型,字段名2 字段类型…);
修:
增加字段: alter table 表名 add column 字段名 字段类型;
修改字段类型: alter table 表名 modify column 字段名 新的字 段类型;
修改字段名: alter table 表名 change column 旧字段名 新的字段名 字段类型;
修改表名: alter table 表名 rename to 新表名;
删: drop table 表名;
查: show tables; desc 表名;
管理数据:
增: insert into 表名(字段名1,字段名2…) values(值1,值2…);
修: update 表名 set 字段名1=值1,字段名2=值2… where 条件;
删: delete from 表名 where 条件;
truncate table 表名;
查: (12中查询)
a)所有字段:select * from 表名;
b)指定字段: select 字段名1,字段名2 from 表名;
c)指定别名: select 字段名1 as 别名1,字段名2 as 别名2 from 表名;
d)添加常量列: select 常量值 as 别名 from 表名;
e)合并列: select (字段名1+字段名2+…) as 别名 from 表名;
f)去除重复: select distinct 字段名 from 表名;
g)条件查询:
逻辑条件: where 条件1 and/or 条件2;
比较条件: where 字段名 >/>=/</<=/=/<> 值
where 字段名 between 值1 and 值2;
判空条件:
null; where 字段名 is null/is not null;
空字符串: where 字段名=’’/<>’’
模糊条件: where 字段名 like 值
%: 代表任意个字符
_: 代表一个字符
h)聚合查询:
max(): 最大值
min():最小值
avg():平均值
count(): 统计数量
i)分页查询:
limit 起始行,查询行数
j)排序:
order by 字段名 asc/desc
asc: 升序
desc: 降序
h)分组查询:
group by 字段名
k)分组后筛选:
group by 字段名 having 条件;
sql语句分类:
1)数据定义语句(DDL):
create/alter/drop
2)数据操作语句(DML)
insert/update/delete/truncate
3)数据查询语句(DQL)
select/show
经过初步学习,我们可以了解到MySQL不仅功能全面,综合化,而且追求最大并发效率。当我们要满足多用户同时访问,或者是网站访问量比较大时,使用MYSQL是明智的选择。

















 2130
2130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









