




 本文详细介绍了jieba中文分词组件的三种模式:全模式、精准模式和搜索引擎模式,并提供了分词步骤,包括读取数据、分词、删除标点、统计词频和过滤日常用语,帮助读者理解和应用jieba进行文本分析。
本文详细介绍了jieba中文分词组件的三种模式:全模式、精准模式和搜索引擎模式,并提供了分词步骤,包括读取数据、分词、删除标点、统计词频和过滤日常用语,帮助读者理解和应用jieba进行文本分析。

在自然语言处理过程中,为了能更好地处理句子,往往需要把句子拆开分成一个一个的词语,以便更好地分析句子的特性,这个过程叫分词。
怎么分词?利用jieba中文分词组件。
三种jieba切词模式介绍
jieba切词有三种模式的选择,分别为全模式,精准模式,搜索引擎模式。
1.全模式:
把句子中所有的可以成词的词语都扫描处理,速度非常快,但是不能解决歧义。

2.精准模式:
试图将句子最精确地切开,适合文本分析。

3.搜索引擎模式:
在精确模式的基础上,对长词再次切分,提高召回率,适合用于引擎分词.

具体流程
Step01
1.首先导入jieba库。

2.添加词典。
比如我们不希望在精准模式下,中国科学院计算所不被切开,我们可以将其添加进词典。

接下来就可以运用上面知识点,对文章词语的词频进行提取(关键词)了。
Step02
1.首先读入我们的数据。
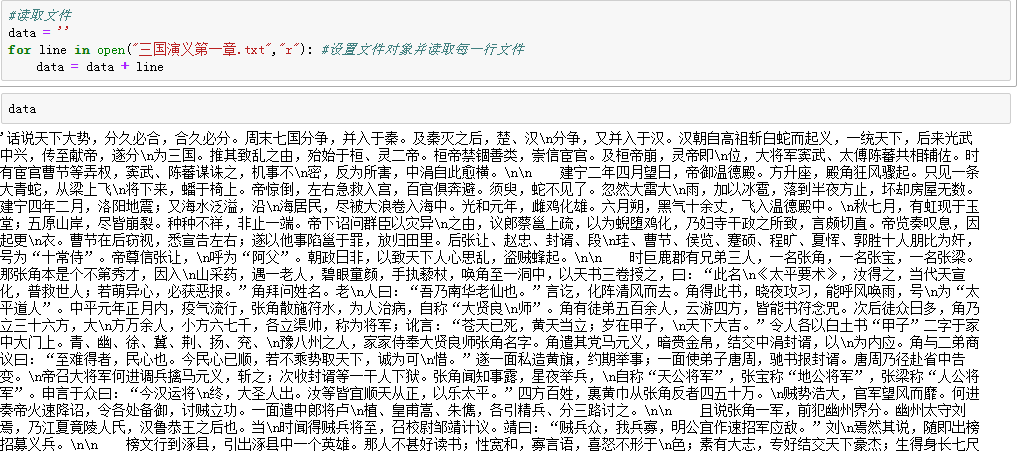
2.然后利用结巴进行切词。
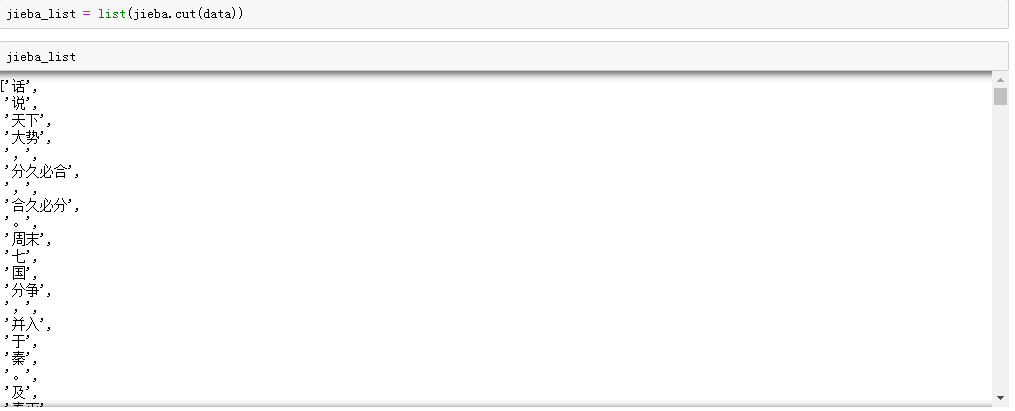
3.删除标点符号
如果你看到很多的标点符号,别慌,他们是可以被删除的。

Step03
1.删除标点符号后,就可以对词语进行词频的统计了。
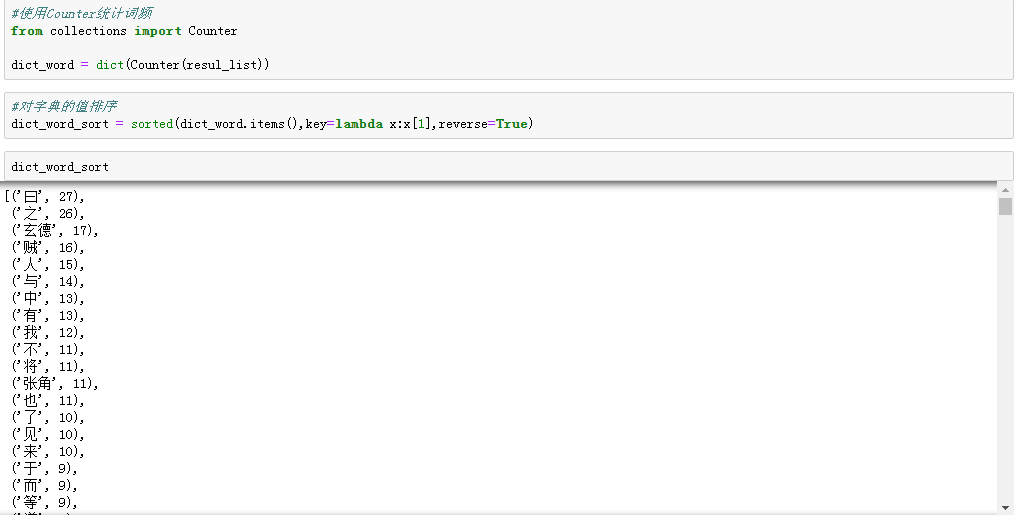
2.过滤日常用语
你会发现有很多,类似于“之,与,中,有”这类高频出现,扰乱视线的日常用语,所以我们选择使用停用词将他们过滤。
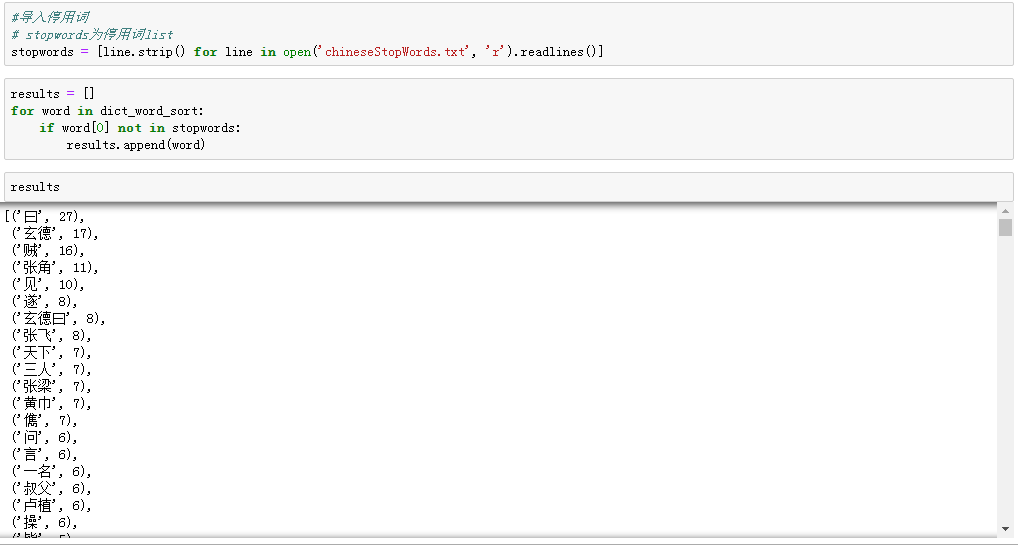
这样我们就把停用词过滤了,就能提取文章中词频比较高的一些词并对其进行分析,或者绘制词云图了。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









