



一、概念
str.lower() 全部转成小写,结果为新的字符串
str.upper()全部转成大写,结果为新的字符串
str.split(sep=None) 将字符串按照指定分隔符sep分隔,结果为列表类型
str.count(sub) 统计sub这个字符串在str中出现的次数
str.find(sub)查询是否存在,不在返回-1,在返回首次出现时的索引
如:
s = "Hello, world! Hello, world!"
index = s.find("world")
print(index) # 输出首次出现的位置(7)
str.index(sub),同上,但是不存在时报错
str.startswith(s)查询是否以子串s开头
str.endswith(s)查询是否以子串s结尾
str.replace(old,news,数字) 使用news替换字符串中所有的old字符串,结果是一个新的字符串;最后一个数字是替换次数,默认是替换全部
str.center(width,fillchar):字符串str在指定的宽度范围内居中,可以使用fillchar进行填充
str.join(iter):在iter中的每个元素拼接起来,以str为分隔符

str.strip(chars):字符串中去掉左右两侧chars中列出的字符串
str.lstrip(chars):字符串中去掉左侧chars中列出的字符串
str.rstrip(chars):字符串中去掉右侧chars中列出的字符串
格式化字符串的三种方法:
占位符:%s字符串格式型 %d十进制 %f浮点型
f-string
str.format()
二、代码练习
1、字符串创建和常见函数应用
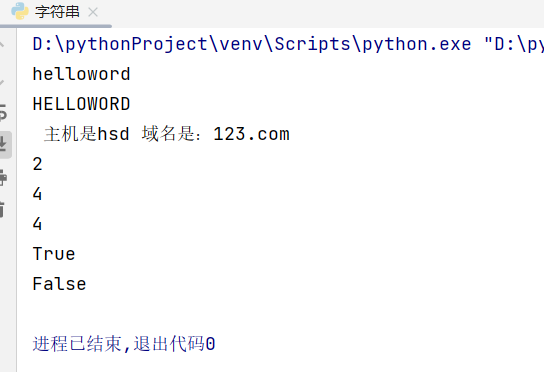
str='helloWorD'
str1=str.lower()#转小写输出
print(str1)
str2=str.upper()#转大写输出
print(str2)
str3='hsd@123.com'
lst=str3.split('@')#以@符号分隔成两个
print(' 主机是'+lst[0]+' 域名是:'+lst[1])
print(str.count('l'))
print(str.find('o'))
print(str.index('o'))
print(str.startswith('h'))#判断是否以h开头
print(str.endswith('g'))#判断是否以g结尾
运行结果:
2、字符串的格式化
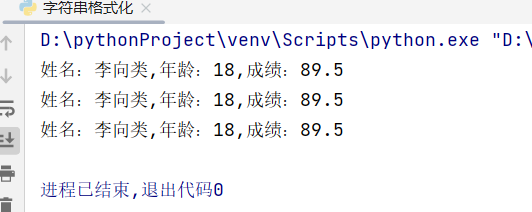
name='李向类'
age=18
score=89.5
#第一种 占位符
print('姓名:%s,年龄:%d,成绩:%.1f'%(name,age,score))
#第二种 f-string
print(f'姓名:{name},年龄:{age},成绩:{score}')
#第三种 format
print('姓名:{0},年龄:{1},成绩:{2}'.format(name,age,score))#0,1,2值format里面的索引
运行结果:
3、正则表达式re,sub,split应用
re:正则表达式库;re.sub() 替换函数。re.split()分隔函数
例如用sub实现敏感文字自动打码。
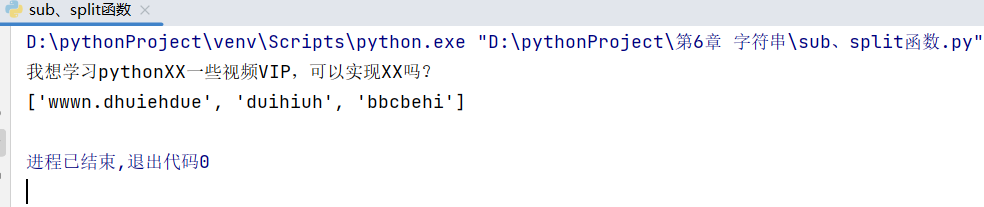
import re#正则表达式函数库
pattern='黑客|破解|反爬'
s='我想学习python破解一些视频VIP,可以实现反爬吗?'
s1=re.sub(pattern,'XX',s)#替换
print(s1)
s2='wwwn.dhuiehdue&duihiuh$bbcbehi'
pattern='[$|&]'
s3=re.split(pattern,s2)#分隔
print(s3)
运行结果:
4、正则表达式:match匹配,search搜索,findall查找函数应用
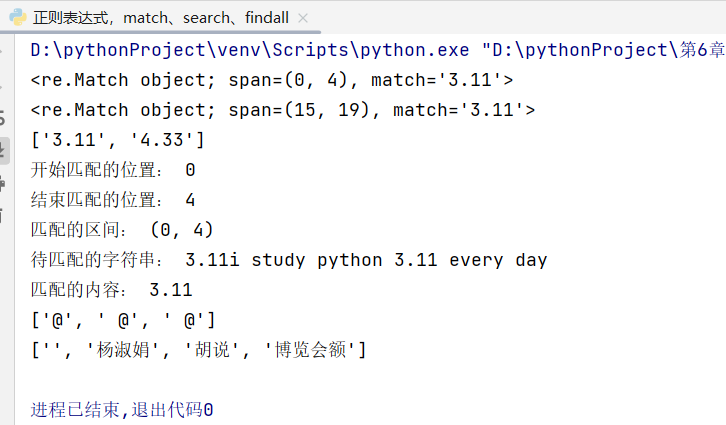
import re
#s='\d.\d+'
pattern='\d.\d+'#匹配模式
s='3.11i study python 3.11 every day'
match=re.match(pattern,s,flags=0)#匹配开始字符串
print(match)
s1='i study python 3.11 every day4.33'
match1=re.search(pattern,s1,flags=0)#搜索查找
print(match1)
lst=re.findall(pattern,s1)#查找全部
print(lst)
print('开始匹配的位置:',match.start())
print('结束匹配的位置:',match.end())
print('匹配的区间:',match.span())
print('待匹配的字符串:',match.string)
print('匹配的内容:',match.group())
import re
pattern=r'\s*@'
s='@杨淑娟 @胡说 @博览会额'
lst1=re.findall(pattern,s)
print(lst1)
lst=re.split(pattern,s)
print(lst)
运行结果

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









