




 本文介绍了一种创新的Few-Shot Segmentation方法CANet,通过Two-branch DCM模块有效利用多级特征进行密集特征比较,结合IoM进行迭代优化,以及Attention机制融合k-shot支持图像信息。研究了如何在弱标注环境下提升分割性能,特别关注了使用bounding box代替像素级标注的效果。实验结果在PASCAL-5i和COCO-20i上展示了算法的优势。
本文介绍了一种创新的Few-Shot Segmentation方法CANet,通过Two-branch DCM模块有效利用多级特征进行密集特征比较,结合IoM进行迭代优化,以及Attention机制融合k-shot支持图像信息。研究了如何在弱标注环境下提升分割性能,特别关注了使用bounding box代替像素级标注的效果。实验结果在PASCAL-5i和COCO-20i上展示了算法的优势。

Abstract
本文研究的问题:
- Few-shot Segmentation
- 致力于应对标注数据获取困难,且耗时耗力的问题和场景
- 同类别的个体外观也会有很大差异,如何挖掘这些同一类别对象的共享特征,也是一个难点。
主要工作:
本文提出了CANet(Class-Agnostic Segmentation Network),其主要贡献在于以下几点:
- 本文提出了一个新颖的Two-branch dense comparison module (DCM),能够有效的利用来自CNN的多级特征(multi-level features)来进行Dense Feature Comparison.
- 本文提出了迭代优化模块(IoM, Iterative Optimization Module),以迭代方式改进预测结果,生成fine-grained(细粒度)maps
- 采用Attention Mechanism,能够有效的融合来自k-shot setting中多个support images中的信息,优于one-shot结果。
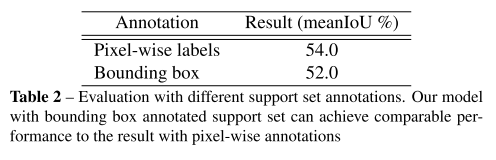
- 本文算法可以用于只有weak annotations的support set, 如:bounding box模型的性能与densely pixel-level annotations相当,进一步减少了few-shot分割的标注工作量。
代码: https://github.com/icoz69/CaNet
1. Related Work
Semantic segmentation
训练模型需要大量的带标注数据,但语义级的标注数据是昂贵的,模型一旦训练好,就不能对新的unseen类别进行分割,而本文算法可以在仅有少量标注的情况下,泛化到任意的类别。
Few-Shot Learning
FSL目标是学习可迁移知识,该知识能够被标注到只有少量标注信息的新类别数据上。本文工作可以看作是在Relation Network[37]上的扩展,用来比较像素级别的相似性。
Few-Shot Segmentation
现有方法[29], [24], [5]
[29] A. Shaban, S. Bansal, Z. Liu, I. Essa, and B. Boots. One-shot learning for semantic segmentation. In BMVC, 2017. 1, 3, 6, 7
[24] K. Rakelly, E. Shelhamer, T. Darrell, A. Efros, and S. Levine. Conditional networks for few-shot semantic segmentation. In ICLR Workshop, 2018.
[5] N. Dong and E. Xing. Few-shot semantic segmentation with prototype learning. In BMVC, 2018.
本文也是基于Two-branch架构,以往方法侧重于1-shot setting,并使用non-learnable。本文将其扩展到k-shot setting,并进行learnable fusion,以提高分割效果。
2. Task Description
One-shot & K-shot Segmentation任务
- 训练集:构建一系列Episode, 每个Episode包括support set和query set。对于k-shot learning,support set包含k对<图像,标签>,用于训练模型;query set也有标签,用于度量损失。
- 测试集:测试集包含几组episode,每个episode仍由support set和query set组成。
- 注意:训练集和测试集的类别没有重叠。
3. Method
CANet由两个模块组成:密集比较模块(DCM)和迭代优化模块(IoU)。分别对应(b)和(c)。
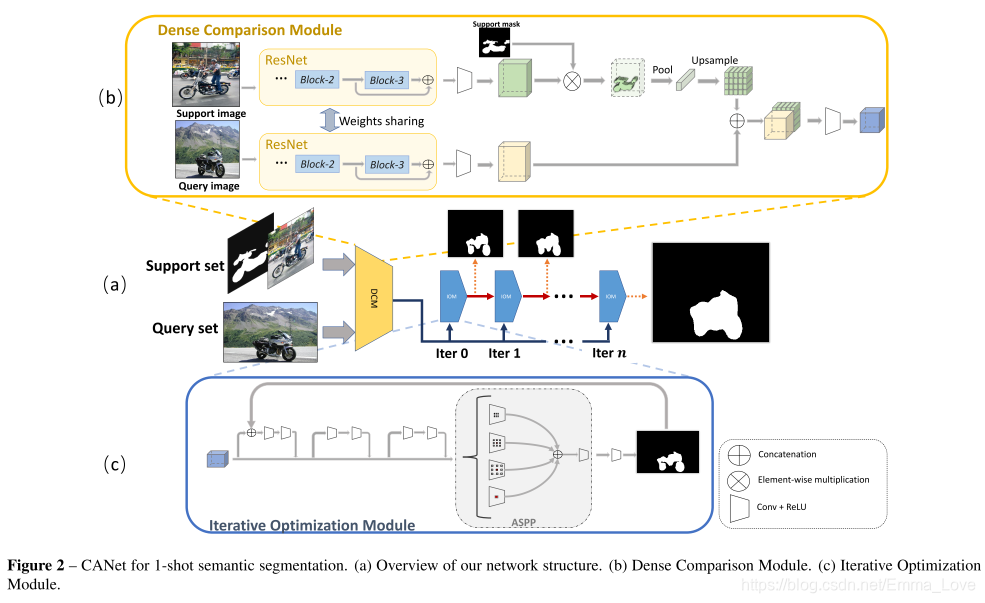
3.1 密集比较模块(Dense Comparison Module, DCM)
目的:提取Feature maps,并对query和support feature set进行比较。
如图(b)所示,由两个子模块组成,分别是Feature Extractor和Comparison Module.
Feature Extractor
由ResNet-50 pretrained on ImageNet组成,将其划分为4个block,分别对应不同层次的特征。
注意:由于浅层提取的特征比较低级,如:边缘等;高层提取的特征过于高级,与特定类别有关。因此,本文方法只利用block2和block3(中间层)的特征进行比较,期望获得一些能够被unseen classes对象共享的特征。
Comparison Module: perform feature comparison
步骤:
- 将block2和block3输出的特征拼接后,输入卷积层得到表征信息。
- Support Branch中,
- 对support mask进行bilinearly下采样,然后与support feature map进行Element-wise multiply,得到只与前景相关的特征,消除背景信息。
- 使用Global Average Pooling,得到该特征图在特定类别的特征向量。
- 然后,利用双线性插值进行上采样,使其与query feature同样大小
- 然后, 将support branch中的输出结果与query feature maps进行拼接,再输入到一个卷积块种,得到比较结果。即:query branch中的所有空间位置与来自support branch中的全局特征向量的比较结果。
3.2 迭代优化模块(Iterative Optimization Module, IOM)
目的:由于同一类别中不同对象之间的外观差异,DCM只能匹配对象的一部分结构,不足以有效的分割出query image中的对象。因此,采用IOM模块,对其进行迭代优化,得到最终的分割结果。
输入:除第一个IOM的输入只包含feature maps generated by dense comparison,后续IOM还将predicted masks from the last IOM 作为联合输入。

每个IOM的计算过程:
- 将𝑀𝑡输入到Residual Blocks当中,该残差块由2个256×3×3卷积块组成
- 然后,在最后的Residual Blocks后面接一个ASPP方法,抽取多尺度特征,然后使用256×1×1的卷积融合多尺度特征
- 最后,将其输入到卷积核大小为1×1的卷积层中,获得最终的掩码,包括:背景掩码和前景掩码。我们使用softmax函数来标准化每个位置的得分,从而输出前景和背景的confidence map。然后将confidence map输入到下一个IOM以进行优化。
- 对最后一个IOM输出的confidence map进行bilinearly上采样,得到与查询图像的相同空间大小的、根据置信度图对每个位置进行分类来实现。
3.3 Attention Mechanism for k-shot Segmentation
目的:为了应对K-Shot问题,引入Attention机制,来融合不同的support examples的对比结果,以提高最终分割效果。
实现:
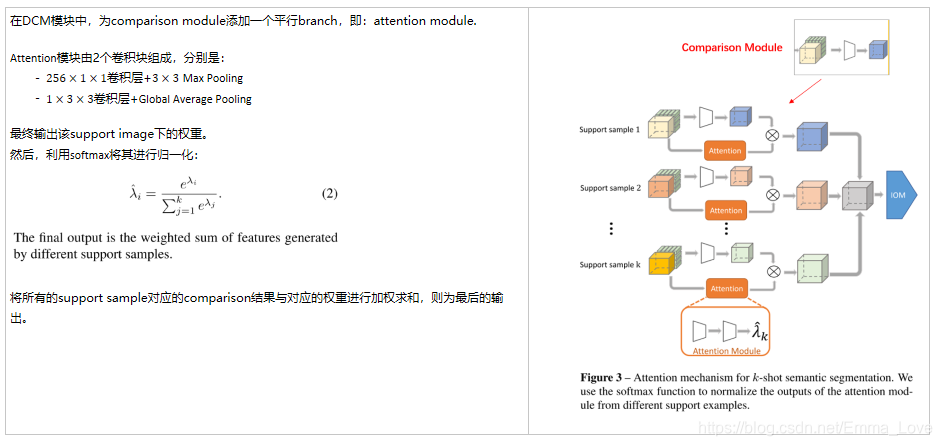
3.4 Bounding Box Annotations
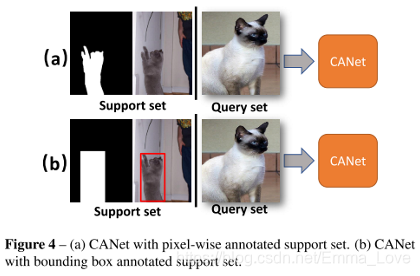
本文探索了一种基于weak annotations的support set进行学习的方式,即:使用bounding box而不是pixel-level的语义掩码作为标签。好处:减少标注的难度。
4. 实验结果
损失函数:交叉熵
数据集:PASCAL-5i和COCO-20i
评价指标:mIoU (本文更关注) 和FB-IoU
4.1 PASCAL-5i
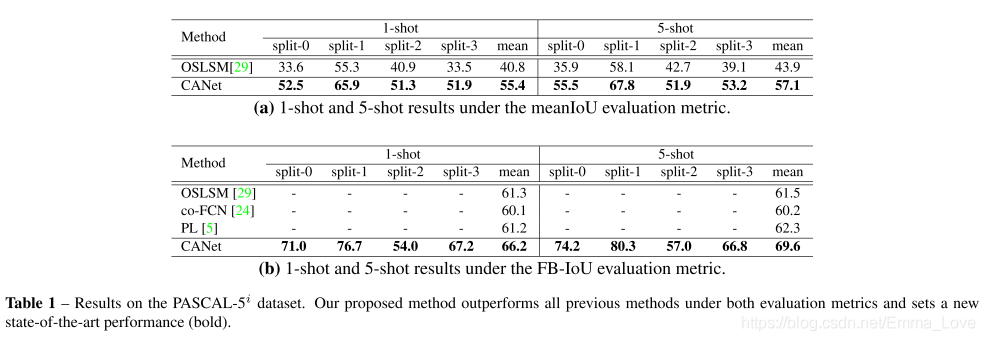
性能:Comparison to SOTA Table 1

探索Bounding Box Annotation的效果:Table 2
消融实验:

- Features for comparison:block2+block3效果最好 (Table 3)
- IOM模块的有效性:(Table 4):对比IOM和DenseCRF后处理的结果
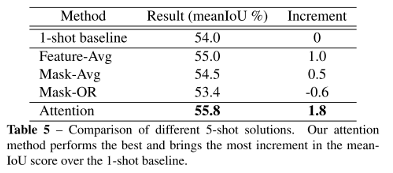
- Attention vs. Feature Fusion vs. Mask Fusion (Table 5)
- Feature-level average fusion: average the features generated by different samples
- Logic-OR fusion for mask: fuse individual predicted masks
- Average fusion for mask: fuse individual 1-shot predicted confidence map

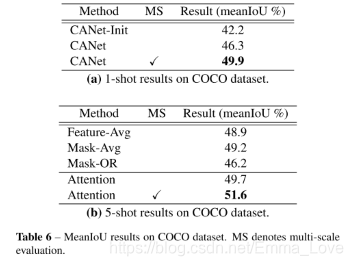
4.2 COCO
看图6

















 4443
4443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









