




简介
参考Pytorch官方的代码Adversarial Example Generation
参数设置(main.py)
# 模型选择:GPU
device = 'mps' if torch.backends.mps.is_available() else 'cpu'
# 数据集位置
dataset_path = '../../../Datasets'
batch_size = 1
shuffle = True
download = False
# 学习率
learning_rate = 0.001
# 预训练模型位置
model_path = "../../../Pretrained_models/Model/MNISTModel_9.pth"
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)),
transforms.Grayscale(),
])
# 扰动参数
epsilons = [0, .05, .1, .15, .2, .25, .3]
device:用于选择训练设备,本人是mac m1的电脑,所以使用mps训练dataset_path:指定数据集路径batch_size:用于DataLoader,判断每次抓取数据的数量shuffle:用于DataLoader,判断是否洗牌download:判断数据集是否下载learning_rate:设置学习率model_path:指定预训练模型路径transform:指定数据集转化规则,用于对数据集中输入的图像进行预处理ToTensor:转化为Tensor数据类型,同时将图片进行归一化Normalize:正则化Grayscale:转化为灰度图像
epsilons:设置扰动参数,用于测试不同扰动的对抗样本的正确率
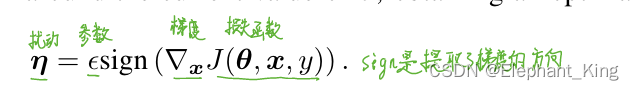
对抗样本代码主流程(main.py)
因为习惯了C++的语法,还是喜欢定义main函数,比较直观哈哈哈哈哈
主要分为三步
- 对数据的生成与预处理
if __name__ == '__main__':
# 1.预处理
train_dataset = datasets.MNIST(dataset_path, train=True, download=download, transform=transform)
val_dataset = datasets.MNIST(dataset_path, train=False, download=download, transform=transform)
train_DataLoader = DataLoader(train_dataset, batch_size=batch_size, shuffle=shuffle)
val_DataLoader = DataLoader(val_dataset, batch_size=batch_size, shuffle=shuffle)
model = torch.load(model_path).to(device)
- 数据集生成
- DataLoader 生成
- 预训练模型加载
- 开始测试
# 2.开始测试
# 记录不同扰动下的准确度
accuracies = []
# 记录样本
examples = []
# 对每个epsilon运行测试
for eps in epsilons:
# 进行对抗样本攻击
acc, ex = test(model, device, val_DataLoader, eps)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









