






 本文详细剖析了HashMap的数据结构、核心成员变量、构造方法及其工作原理,包括put和get方法的源码解读,阐述了HashMap如何通过数组加链表实现高效的数据存储和检索。
本文详细剖析了HashMap的数据结构、核心成员变量、构造方法及其工作原理,包括put和get方法的源码解读,阐述了HashMap如何通过数组加链表实现高效的数据存储和检索。
HashMap
底层是基于
数组 + 链表组成。
数据结构图
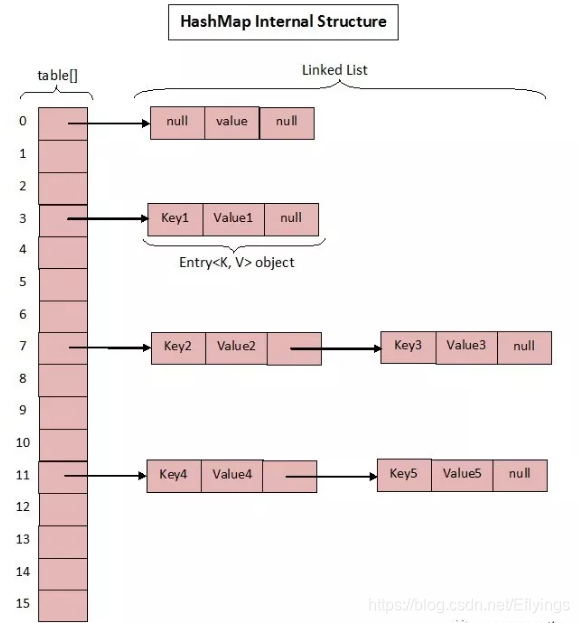
核心成员变量
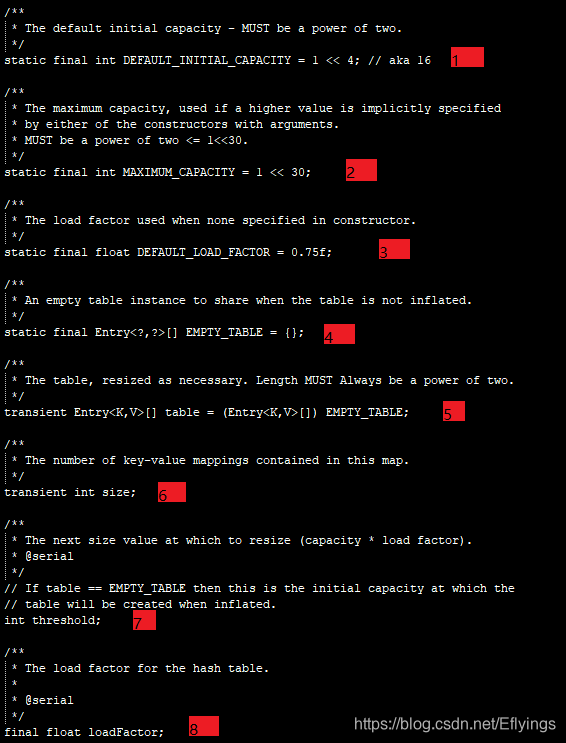
DEFAULT_INITIAL_CAPACITY:初始化桶大小,因为底层是数组,所以这是数组默认的大小。
MAXIMUM_CAPACITY:桶最大值。
DEFAULT_LOAD_FACTOR:默认的负载因子(0.75)
EMPTY_TABLE:table真正存放数据的数组。
table:Map存放数量的大小。size:桶大小,可在初始化时显式指定。
threshold:负载因子,可在初始化时显式指定。
常用构造方法
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and the default load factor (0.75).
*
* @param initialCapacity the initial capacity.
* @throws IllegalArgumentException if the initial capacity is negative.
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
HashMap的默认容量为16,负载因子为0.75。在使用Map存放数据时,当数量达到 16*0.75=12 时就需要将容量扩容,而扩容的过程中涉及到rehash、复制数据等操作,所以非常消耗性能。因此通常情况下能提前预估 HashMap 的大小最好,尽量的减少扩容带来的性能损耗。
根据代码可以看出真实存放数据的是
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
Entry<K,V>源码
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap<K,V> m) {
}
}
Entry<K,V> 是 HashMap 中的一个内部类,成员变量如下:
key 就是写入时的键。
value 就是写入时的值。
HashMap 是由数组和链表组成,所以next 就是用于实现链表结构的。
hash 存放的是当前 key 的 hashcode。
HashMap put方法源码
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
/**
* Inflates the table.
*/
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
//计算阈值
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
//初始化table数组大小
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
/**
* Retrieve object hash code and applies a supplemental hash function to the
* result hash, which defends against poor quality hash functions. This is
* critical because HashMap uses power-of-two length hash tables, that
* otherwise encounter collisions for hashCodes that do not differ
* in lower bits. Note: Null keys always map to hash 0, thus index 0.
*/
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
判断当前数组是否需要初始化,如果table为EMPTY_TABLE(即空),则调用inflateTable进行初始化。
如果 key 为空,则 put value值到键为null位置。
如果值不为空,则根据 key 计算出 hashcode。
根据hashcode值及table数组的长度计算出其所在桶的位置。
如果所在桶中有数据,则遍历所在桶的链表数据,判断里面的 hashcode、key 是否和传入 key 相等,如果相等则对值进行覆盖,并返回原来的值;如果不相等则新增一个 Entry 对象到指定位置;
如果桶是空的,说明当前位置没有数据存入;新增一个 Entry 对象写入当前位置。
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* method to resize the table if appropriate.
*
* Subclass overrides this to alter the behavior of put method.
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
/**
* Like addEntry except that this version is used when creating entries
* as part of Map construction or "pseudo-construction" (cloning,
* deserialization). This version needn't worry about resizing the table.
*
* Subclass overrides this to alter the behavior of HashMap(Map),
* clone, and readObject.
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
调用 addEntry方法新增Entry对象时需要先判断是否需要扩容((size >= threshold) && (null != table[bucketIndex]) )。
如果需要扩容,则容量扩大为原来的两倍,并将当前的key重新hash定位 。
调用createEntry方法,添加Entry对象;获取当前位置的“桶”,并将当前位置的桶传入到新建的桶中,如果当前桶有值则会将当前位置的桶作为新建桶的next桶,形成链表。
HashMap get方法源码
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
//获取key为null的value值
private V getForNullKey() {
if (size == 0) {
return null;
}
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
//获取key的hash值
int hash = (key == null) ? 0 : hash(key);
//根据hash值和table数组长度确定key所在table中的位置,获取所在位置的链表并遍历
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
首先判断key是否为空,为空则获取key为null的value值;
根据 key 计算出 hashcode,结合table数组的长度定位到具体的桶。
获取桶中的链表数据,遍历链表直到 key 及 hashcode 相等时则返回Entry<K,V>对象。
如果未取到就直接返回 null 。
注意:当 Hash 冲突严重时,在桶上形成的链表会变的越来越长,这样在查询时的效率就会越来越低;时间复杂度为
O(N)。

















 1528
1528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









