




 本文详细介绍了Redis中跳跃表(Skip List)的设计原理和实现细节,包括节点结构、头尾节点创建、随机层高生成等。跳跃表作为一种高效的数据结构,用于有序集合的底层实现,提供O(logN)的查找、插入和删除操作。在数据量较大时,相比于红黑树,跳跃表在空间换取时间方面更具优势,且实现更为简单。
本文详细介绍了Redis中跳跃表(Skip List)的设计原理和实现细节,包括节点结构、头尾节点创建、随机层高生成等。跳跃表作为一种高效的数据结构,用于有序集合的底层实现,提供O(logN)的查找、插入和删除操作。在数据量较大时,相比于红黑树,跳跃表在空间换取时间方面更具优势,且实现更为简单。
0.引用及学习链接
跳表的论文-【本地用everything搜索skiplists.pdf】
1.简介
1.1 从有序链表到分层有序链表
如果想要找到7这个元素,需要进行7次比较,时间复杂度为O(N),有序链表的插入和删除操作都需要先找到合适
的位置再修改next指针,修改操作基本不消耗时间,所以插入、删除、修改有序链表的耗时主要在查找元素上.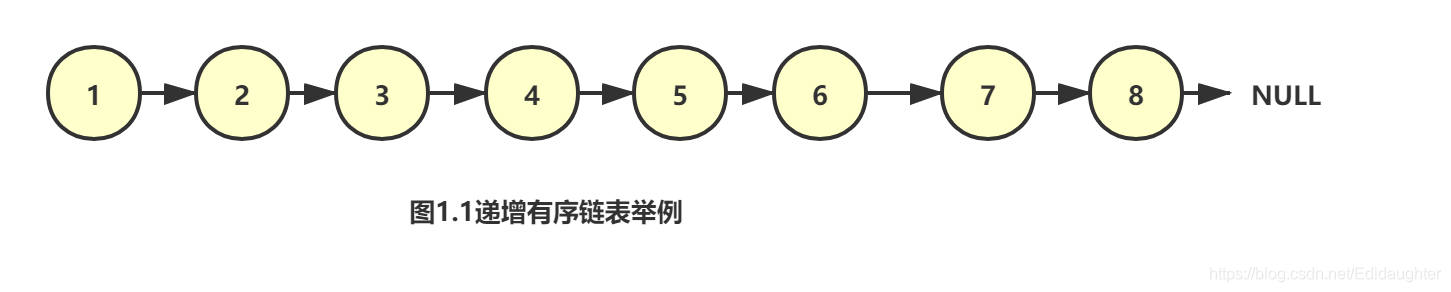
从索引层2开始比较,与1比较,与5比较,然后在索引层1中于7比较,查询到结果,
一共经历3次比较.
图1.2中的绿色箭头就是比较路径,本例中比图1.1中的方法少了4次比较.
现在的数据量很小,可能优势还不是很明显,当数据量大时,优势会很明显.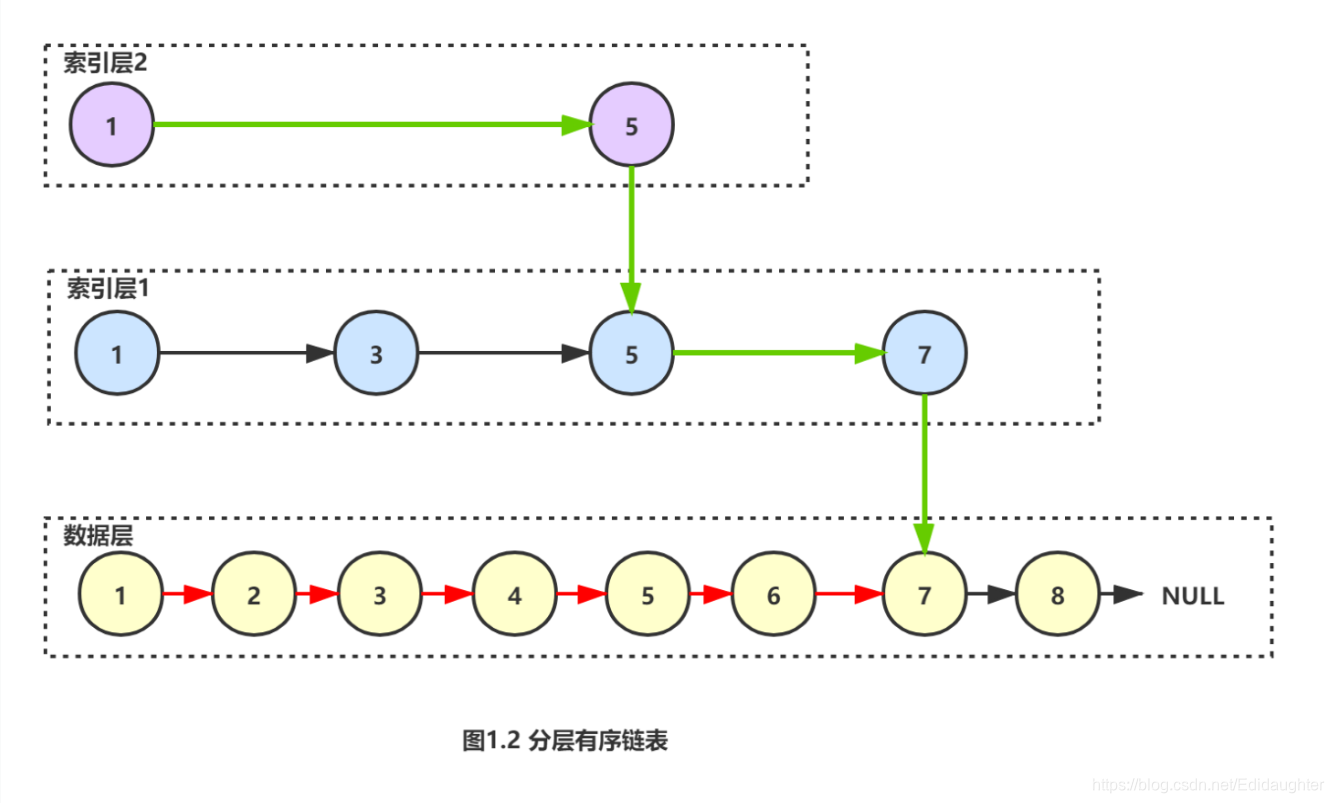
1.2 跳表思路
通过将有序集合的部分节点分层,由最上层开始依次向后查找,如果本层的next节点大于要查找的值或next节点
为NULL,则从本节点开始,降低一层继续向后查找,依次类推,如果找到则返回节点;否则返回NULL。采用该原
理查找节点,在节点数量比较多时,可以跳过一些节点,查询效率大大提升,这就是跳跃表的基本思想。
1.3 跳表的性质
2.跳表的设计与性质
受启发于分层有序列表,redis对其内部的跳表进行如下设计:
2.1 跳跃表节点(zskiplistNode)设计
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;// 用于存储字符串类型的数据
double score;// 用于存储排序的分值
/*后退指针,只能指向当前节点最底层的前一个节点,头节点和第一个节点的backward指向NULL,从后向前遍历跳跃表时使用*/
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];//为柔性数组,每个节点的数组长度不一样,在生成跳跃表节点时,随机生成一个1~32的值,值越大出现的概率越低
} zskiplistNode;
2.2 跳跃表(zskiplist)设计
typedef struct zskiplist {
/*
header:
指向跳跃表头节点。头节点是跳跃表的一个特殊节点,
它的level数组元素个数在本版本中为32.头节点在有序集合中不存储任何member和score值,
ele值为NULL, score值为0;也不计入跳跃表的总长度.
头节点在初始化时,32个元素的forward都指向NULL, span值都为0.
初始化代码为zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
tail:
指向跳跃表尾节点
*/
struct zskiplistNode *header, *tail;
unsigned long length;// 跳跃表长度,表示除头节点之外的节点总数
int level;// 跳跃表的高度
} zskiplist;2.3 举个最简单的栗子
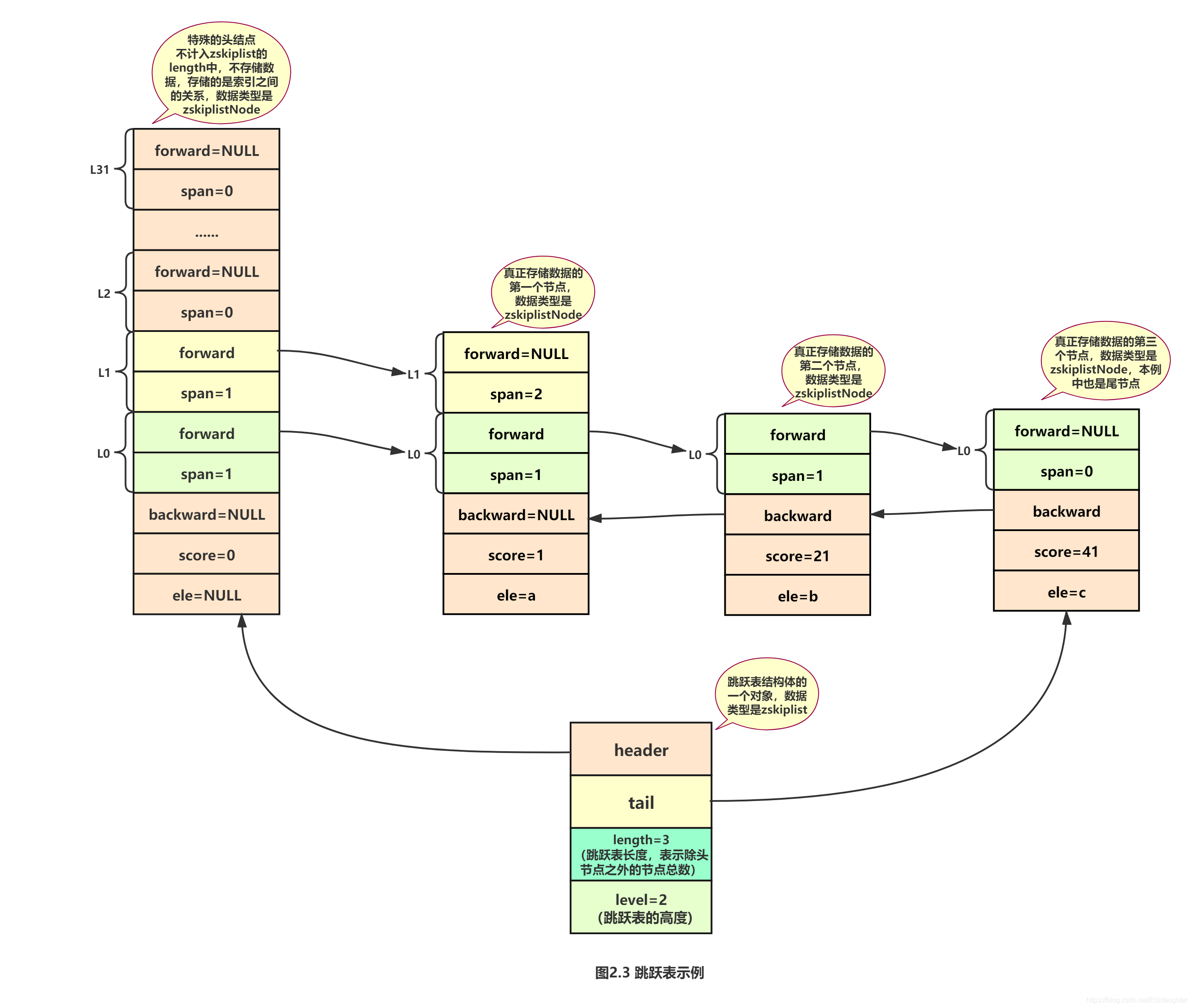
2.4 跳跃表的性质
从图2.3中我们可以看出跳跃表有如下性质.
(1)跳跃表由很多层构成;
(2)跳跃表有一个头节点header,头节点中有一个32层(redis5中是64层)的结构,每层的结构包含指向本层
的下个节点的指针,指向本层下个节点中间所跨越的节点个数为本层的跨度span;
(3)除头节点外,层数最多的节点的层高为跳跃表的高度level,图2.3中跳跃表的高度为2;
(4)每层都是一个有序链表,数据递增;
(5)除header节点外,一个元素在上层有序链表中出现,则它一定会在下层有序链表中出现;
(6)跳跃表每层最后一个节点指向NULL,表示本层有序链表的结束;
(7)跳跃表拥有一个tail指针,指向跳跃表最后一个节点;
(8)最底层的有序链表包含所有节点,最底层的节点个数为跳跃表的长度length,不包括头节点,图2.3中跳跃表的长度为3;
(9)每个节点包含一个后退指针,头节点和第一个节点指向NULL;其他节点指向最底层的前一个节点.
跳跃表每个节点维护了多个指向其他节点的指针,所以在跳跃表进行查找、插入、删除操作时可以跳过一些节
点,快速找到操作需要的节点.归根结底,跳跃表是以牺牲空间的形式来达到快速查找的目的.跳跃表与平衡树相
比,实现方式更简单,只要熟悉有序链表,就可以轻松地掌握跳跃表.3.基本操作
3.1 创建跳跃表
3.1.1 节点层高
节点层高的最小值为1,最大值是ZSKIPLIST_MAXLEVEL, Redis6.0.8中节点层高的值为32.
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^64 elements */
#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */Redis通过zslRandomLevel函数随机生成一个1~64的值,作为新建节点的高度,值越大出现的概率越低。节点层高确定之后便不会再修改。生成随机层高的代码如下。
/* Returns a random level for the new skiplist node we are going to create.
* The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL
* (both inclusive), with a powerlaw-alike distribution where higher
* levels are less likely to be returned. */
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
头结点的创建
/* Create a skiplist node with the specified number of levels.
* The SDS string 'ele' is referenced by the node after the call. */
zskiplistNode *zslCreateNode(int level, double score, sds ele) {
zskiplistNode *zn =
zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
zn->score = score;
zn->ele = ele;
return zn;
}
/* Create a new skiplist. */
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}4.跳跃表的应用
4.1 有序集合的底层数据结构是跳表或者是压缩列表
在Redis中,跳跃表主要应用于有序集合的底层实现(有序集合的另一种实现方式为压缩列表)。Redis的配置文件中关于有序集合底层实现的两个配置。
1)zset-max-ziplist-entries 128:zset采用压缩列表时,元素个数最大值。默认值为128。
2)zset-max-ziplist-value 64:zset采用压缩列表时,每个元素的字符串长度最大值。默认值为64。
zset添加元素的主要逻辑位于t_zset.c的zaddGenericCommand函数中。zset插入第一个元素时,会判断下面两种条件:
❏ zset-max-ziplist-entries的值是否等于0;
❏ zset-max-ziplist-value小于要插入元素的字符串长度。
满足任一条件Redis就会采用跳跃表作为底层实现,否则采用压缩列表作为底层实现方式.
/* Lookup the key and create the sorted set if does not exist. */
zobj = lookupKeyWrite(c->db,key);
if (zobj == NULL) {
if (xx) goto reply_to_client; /* No key + XX option: nothing to do. */
if (server.zset_max_ziplist_entries == 0 ||
server.zset_max_ziplist_value < sdslen(c->argv[scoreidx+1]->ptr))
{
zobj = createZsetObject();
} else {
zobj = createZsetZiplistObject();
}
dbAdd(c->db,key,zobj);
} else {
if (zobj->type != OBJ_ZSET) {
addReply(c,shared.wrongtypeerr);
goto cleanup;
}
}typedef struct zset {
dict *dict;// 字典成员,可以快速搜索到这个节点,O(1)
zskiplist *zsl; // O(logn)
} zset;
4.2 判断底层数据结构的命令object encoding
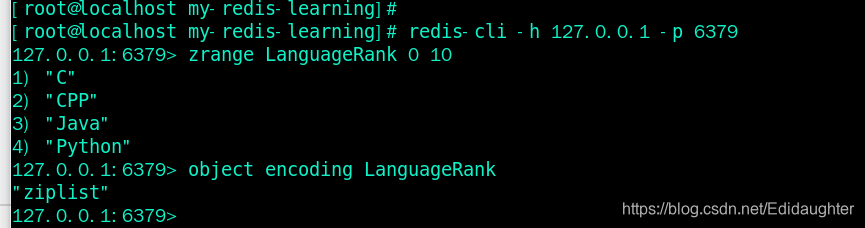


















 342
342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









