




一、消息引擎系统
通常以软件接口为主要形式,实现了松耦合的异步式数据传递语义。设计一个消息引擎系统,需着重考虑两个因素。
- 消息设计
要考虑语义清晰和结构上通用。消息主体一般都是结构化的数据,kafka消息采用了二进制方式保存, - 传输协议
目前主流协议包括了AMQP、Web Service+SOAP及微软的MSMQ,其服务于消息引擎系统实现的消息引擎泛型。
最常见的消息引擎系统是消息队列模型和发布订阅模型。
- 队列模型:提供了一种点对点式的消息传递方式,一旦消息被消费,就会从队列中移除。发送者到消费者是一对一的关系。
- 发布订阅模型:额外有了topic的概念。
二、kafka入门
kakfa本质上是一个流式处理框架,其用于构建实时数据管道和流应用程序,其中,实时数据管道获取系统和应用程序之间的数据;流应用则对流数据进行转换和反应,具备如下特点:
- 横向扩展
- 容错
- 速度快
4个问题
kafka设计之初就考虑4个方面问题
1.消息持久化
- 解耦生产者与消费者:生产者只需将消息交由kafka服务器保存即可,提升了整体吞吐量
- 消息的灵活处理:消费者可以实现对历史消息的重消费(消息重演)
2.吞吐量
吞吐量是某种处理能力的最大值,对kafka而言就是每秒能够处理的消息或每秒能处理的字节数。
kafka的数据持久化到磁盘上,本质上是先写入操作系统的页缓存中,然后由操作系统决定什么时候把页缓存重新写入磁盘中。这样有3个好处:
- 操作系统页缓存是在内存中分配的,速度快
- kafka不必和底层文件系统打交道,所有IO操作系统自行处理
- 写入采用了追加的方式(不允许修改历史信息),避免磁盘随机写入
kafka的消费者读取消息时会首先从OS的页缓存种读取,如果成功则直接把消息经页缓存发送到网络的socket上。(零拷贝数据传输)
3.负载均衡和故障转移
- 负载均衡通过智能化的分区领导选举(partition leader election)实现的
- 故障转移则通常以“会话”机制实现,每台kafka服务器启动时都会以会话的形式注册到zk上,当某台服务器轮转出问题时,zk超时失效,kakfa集群会选举新的一台服务器来替代原机器进行服务
4.伸缩性
- Kafka每台服务状态都由zk保管,将集群状态统一交由zk保管和协调,极大降低了集群维护的复杂度,横向扩展也可以尽可能达到线性扩展。
kafka实现高吞吐量和低延时的设计目标,主要靠4点:
- 大量使用操作系统页缓存,操作速度快且命中率搞
- 不直接参与物理IO操作,交给操作系统
- 追加写入,避免缓慢的无序随机写入
- 使用零拷贝技术加强网络间的数据传输效率
核心api
- Producer Api:发布一个record到topic中(可多个)
- Consumer Api:订阅topic(可多个),处理获取到的record
- Streams Api:流处理器,从topic消费输入流,并生产一个输出流到输出topic,有效地将输入流转换到输出流
- Connector Api:构建或运行可重用的生产者或消费者,将topic连接到现有的应用程序或数据系统。例如,连接到关系数据库的连接器可以捕获表的每个变更
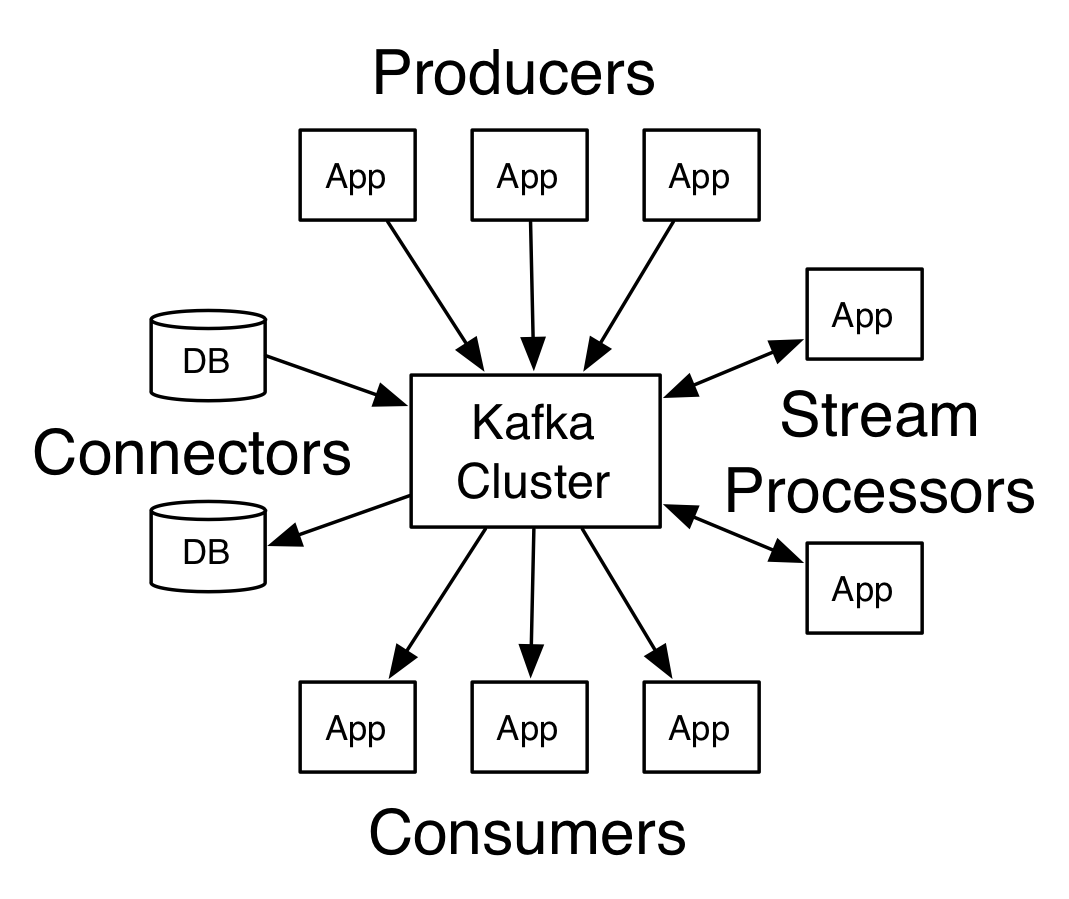
基本术语
- record
- Topic
按类分消息类别 - Producer
- Consumer
- Broker
已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker)。 消费者可以订阅一个或多个topic,并从Broker拉数据,从而消费这些已发布的消息。
Record
消息,kafka中消息格式由很多字段组成,由消息头部、key、value组成,需着重关注3个信息:
1.Key:消息键,决定消息会存储在topic下的哪个partition
2.Value:消息体,实际保存的数据
3.Timestamp:发送时间戳,用于流式处理及其他依赖时间的处理语义。
Topic和Log
Topic是发布的消息的类别名,一个topic可以有零个,一个或多个消费者订阅该主题的消息。对于每个topic,kafka集群都会有一个或多个partition log。
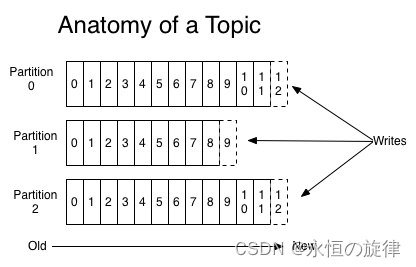
partition
每个partition都按照一定顺序,且可以持续添加。partition中每一个消息都被分配了一个序号,称为偏移量(offset)。在每个partition中的offset都是唯一的
kafka集群的消息在过期前持续存在(无论是否被消费),本质上来说,消费者持有的仅是offset,且该变量由消费者控制。当消费者消费消息的时候,offset也会线性增加。如果消费者将offset重置,可以重新读取到历史消息。同时,一个消费者的操作不会影响其它消费者对此log的处理。
partition设计目的:
1.可以处理更多消息,当消息量过大时,可以分配到多台机器上
2.可以作为并行处理单元
3.容错(leader follower)
log的不同partition会分布到集群中的不同机器上,每个partition可能会在一台或多台机器上,当不止一台机器时,针对一个partition会有一个leader和若干个follower,leader负责处理该partition的所有读写请求,follower则会复制数据,当leader宕机后,follower会推举出一个新的leader。因此,一台机器可能是部分topic的leader和部分topic的follower。该种方式也可以负载均衡
producers
生产者往某个Topic上发布消息。生产者也负责选择发布到Topic上的哪一个分区,方法有轮转或根据权重。权重算法由开发者选择
Consumers
消费模型分两种:
- 队列式
消费者从kafka服务端读取消息,每条消息仅能被一个消费者消费。 - 订阅式
消息会广播给所有订阅了该消息所属topic的消费者
每个消费者会属于一个消费者组,则一个topic上的消息会被分发给消费者组中的某一个消费者,若该topic的所有消费者都属于同一个消费者组,则变成队列式。
kakfa guarantees
- 生产者发送到特定topic的某个partition上,会按照消息的发送顺序进入partition
- 如果一个Topic配置了复制因子(replication factor)为N, 那么可以允许N-1服务器宕机而不丢失任何已经提交(committed)的消息

















 2616
2616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









