








详细介绍了BERTopic这一高性能主题建模工具,对比传统主题建模方法(如LDA、LSA)在流程复杂度、计算成本及效果上的不足,重点解析了BERTopic基于Transformer架构的模块化流程,包括嵌入模型(如Sentence Transformer)、降维模型(如UMAP)、聚类模型(如HDBSCAN)等核心组件的选择与实现。文中展示了通过TF-IDF、KeyBERTInspired及生成式AI(如GPT-3.5-turbo)优化主题表示的方法,强调其通过灵活调整组件参数提升模型适配性的优势。此外,推文还介绍了BERTopic的可视化工具(主题分布、术语重要性、相似度热力图等)及变体(分层、时间序列等模型),最后总结其通过整合多模型组件、支持参数微调及生成式优化,显著提升了主题建模的效果与可解释性。
BERTopic流程
采用传统方法进行主题建模可能颇具挑战,需自行构建数据清洗、分词、词形还原、特征构建等流程。LDA或潜在语义分析(LSA)等传统模型还存在计算成本高、结果往往欠佳的问题。
BERTopic通过嵌入模型利用Transformer架构,并整合降维、主题表示模型等组件,以构建高性能主题模型。 BERTopic还提供适用于不同数据和场景的模型变体、用于探索结果的可视化工具等。
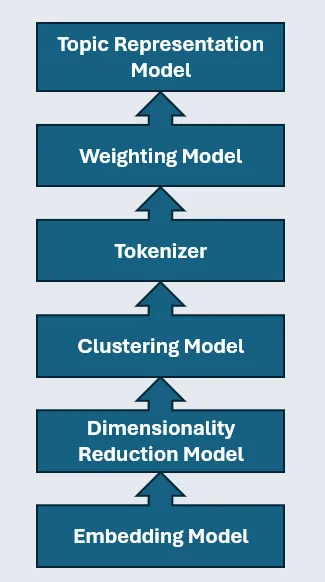
如上图所示,该流程由多个不同模型组成:
- 嵌入模型
- 降维模型
- 聚类模型
- 分词器
- 加权方案
- 表示模型(可选)
因此,我们可在每个组件中尝试不同模型,且各模型有独立参数。例如,可尝试不同嵌入模型,将降维方法从主成分分析(PCA)切换为均匀流形近似与投影(UMAP),或微调聚类模型参数。这种灵活性是巨大优势,能让主题模型适配数据与场景。
然后是导入模块的代码块:
首先,需导入必要模块。其中多数用于构建BERTopic模型的组件。
#import 数据管理相关包
import pickle
#import 主题建模相关包
from bertopic import BERTopic
from bertopic.representation import KeyBERTInspired
from bertopic.vectorizers import ClassTfidfTransformer
from sentence_transformers import SentenceTransformer
from umap.umap_ import UMAP
from hdbscan import HDBSCAN
from sklearn.feature_extraction.text import CountVectorizer
#import 数据处理与可视化相关包
import pandas as pd
import matplotlib.pyplot as plt
from scipy.cluster import hierarchy as sch
接下来是Embedding Model部分:
嵌入模型
BERTopic模型的核心组件是嵌入模型。首先,我们用Sentence Transformer初始化模型,随后可指定要使用的嵌入模型。
本例中,我使用一个相对较小的模型(约3000万参数)。虽大模型可能带来更好效果,但为强调流程速度,我选择小模型。你可通过Hugging Face的MTEB排行榜(https://huggingface.co/spaces/mteb/leaderboard),根据模型大小、性能、预期用途等对比选择嵌入模型。
#初始化嵌入模型
embedding_model = SentenceTransformer('thenlper/gte-small')
#计算嵌入向量
embeddings = embedding_model.encode(data['all_text'].tolist(), show_progress_bar=True)
运行模型后,可通过.shape函数查看生成向量的维度。如下所示,每个嵌入向量包含384个值,这些值构成文档的语义表示。
#探究向量的形状与大小
embeddings.shape
#输出: (6102, 384)
然后是Dimensionality Reduction Model:
降维模型
BERTopic模型的下一个组件是降维模型。高维数据建模难度大,因此可用降维模型在不过多损失信息的前提下,将嵌入向量表示为低维形式。
降维模型有多种类型,主成分分析(PCA)是最常用的。本例中,我们使用均匀流形近似与投影(UMAP)模型。UMAP是非线性模型,相比PCA更能处理数据中的复杂关系。
#初始化降维模型并降维
umap_model = UMAP(n_neighbors=5, min_dist=0.0, metric='cosine', random_state=42)
reduced_embeddings = umap_model.fit_transform(embeddings)
需注意,降维并非高维数据的“万能解”。降维在速度与精度间存在权衡,因为信息会损失。这些模型需精心设计与试验,以在保持速度和可扩展性的同时避免损失过多信息。
接下来是Clustering Model:
聚类模型
第三步是利用降维后的嵌入向量进行聚类。虽聚类并非主题建模的必需步骤,但我们可借助密度聚类模型分离离群点、消除数据噪声。如下,我们初始化层次密度基于噪声的空间聚类(HDBSCAN)模型并生成簇。
#初始化聚类模型并聚类
hdbscan_model = HDBSCAN(min_cluster_size=30, metric='euclidean', cluster_selection_method='eom').fit(reduced_embeddings)
clusters = hdbscan_model.labels_
基于密度的方法有几大优势:文档不会被强行归入不匹配的簇,从而分离离群点、减少数据噪声;与质心模型不同,无需指定簇数量,且簇更易定义清晰。
我的聚类算法指南:
以下代码用于可视化聚类模型结果。
#创建降维嵌入与簇的DataFrame
df = pd.DataFrame(reduced_embeddings, columns = ['x', 'y'])
df['Cluster'] = [str(c) for c in clusters]
#分离簇与离群点
to_plot = df.loc[df.Cluster != '-1', :]
outliers = df.loc[df.Cluster == '-1', :]
#绘制簇
plt.scatter(outliers.x, outliers.y, alpha = 0.05, s = 2, c = 'grey')
plt.scatter(to_plot.x, to_plot.y, alpha = 0.6, s = 2, c = to_plot.Cluster.astype(int), cmap = 'tab20b')
plt.axis('off')

我们能看到边界清晰且不重叠的簇,也能看到小簇聚合成更高层级主题,最后还有若干文档被标为灰色离群点。
然后是Creating a BERTopic Pipeline:
构建BERTopic流程
现在我们已具备构建BERTopic流程的必要组件(嵌入模型、降维模型、聚类模型)。可使用已初始化的模型,通过BERTopic函数适配数据。
#使用上述模型构建BERTopic流程
topic_model = BERTopic(
embedding_model=embedding_model, # 步骤1 - 提取嵌入向量
umap_model=umap_model, # 步骤2 - 降维
hdbscan_model=hdbscan_model, # 步骤3 - 对降维嵌入向量聚类
verbose = True).fit(data['all_text'].tolist(), embeddings)
已知我导入了关于人机交互(增强现实、虚拟现实)的论文,现在看看哪些主题与“增强现实”相关。
#与“augmented reality”最相似的主题
topic_model.find_topics("augmented reality")
#输出: ([18, 3, 16, 24, 12], [0.9532771, 0.9498462, 0.94966936, 0.9451431, 0.9417263])
从输出可见,主题18、3、16、24、12与“增强现实”高度相关。这些主题(希望)都围绕增强现实这一更广泛主题展开,但各有侧重。
为验证这点,我们探究主题表示。主题表示是一组术语,旨在恰当呈现主题的潜在内涵。例如,“蛋糕”“蜡烛”“家人”“礼物”可共同表示“生日”或“生日派对”主题。
我们用get_topic()函数探究主题18的表示。
#探究主题18
topic_model.get_topic(18)
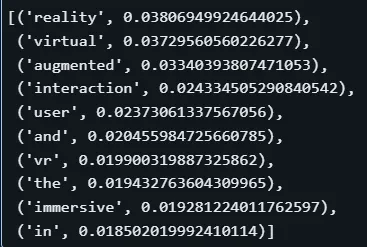
上述表示中有“reality”“virtual”“augmented”等有用术语,但整体不够实用,因包含“and”“the”等停用词。这是因为BERTopic默认用词袋模型表示主题,且该表示可能与其他增强现实相关表示重叠。
接下来,我们将优化BERTopic流程,生成更有意义的主题表示,以深入理解这些主题。
然后是Improving Topic Representations:
优化主题表示
可通过添加加权方案优化主题表示,突出重要术语、更好区分主题。
这并非替换词袋模型,而是对其改进。如下,我们添加TF-IDF模型以更好判定术语重要性,并用update_topics()函数更新流程。
#初始化分词器模型
vectorizer_model = CountVectorizer(stop_words="english")
#初始化CTF-IDF模型加权术语
ctfidf_model = ClassTfidfTransformer()
#向流程添加分词器与CTF-IDF
topic_model.update_topics(data['all_text'].tolist(), vectorizer_model=vectorizer_model, ctfidf_model=ctfidf_model)
#探究主题表示的变化
topic_model.get_topic(18)
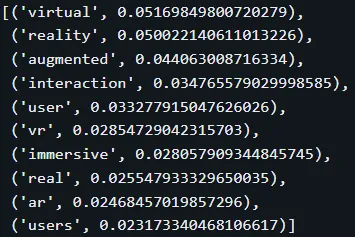
借助TF-IDF,主题表示实用性大幅提升:无意义停用词消失,出现更多描述性术语,且术语按重要性排序。
但优化不止于此。得益于AI与NLP领域的大量新进展,我们可借助多种方法微调表示。
微调有两种途径:
- 表示模型
- 生成式模型
用表示模型微调
首先,添加KeyBERTInspired模型作为表示模型。它借助BERT比较TF-IDF表示与文档的语义相似度,以更精准判定术语相关性(而非仅重要性)。
#初始化表示模型并添加到流程
representation_model = KeyBERTInspired()
topic_model.update_topics(data['all_text'].tolist(), vectorizer_model=vectorizer_model, ctfidf_model=ctfidf_model, representation_model=representation_model)
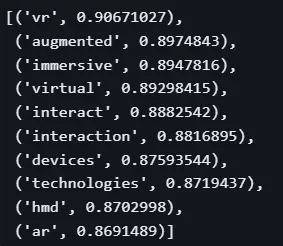
此处术语变化明显,新增术语与缩写。对比TF-IDF表示,我们对主题的理解更深入。同时注意到,分数从无上下文意义的TF-IDF权重,变为0–1间的语义相似度分数。
主题模型可视化
在转向生成式模型微调前,先探索BERTopic提供的可视化工具。可视化主题模型对理解数据与模型运作至关重要。
首先,可在二维空间可视化主题,查看主题规模与相似性。如下,可见主题众多,簇状主题构成更大主题;还有一个规模大且孤立的主题,表明关于CRISPR的研究高度相似。

放大主题簇,查看增强与虚拟现实相关主题如何分解为更高层级主题。如下,放大后可见部分主题覆盖不同领域与应用。


还可快速可视化各主题最重要或最相关的术语(取决于主题表示方法)。
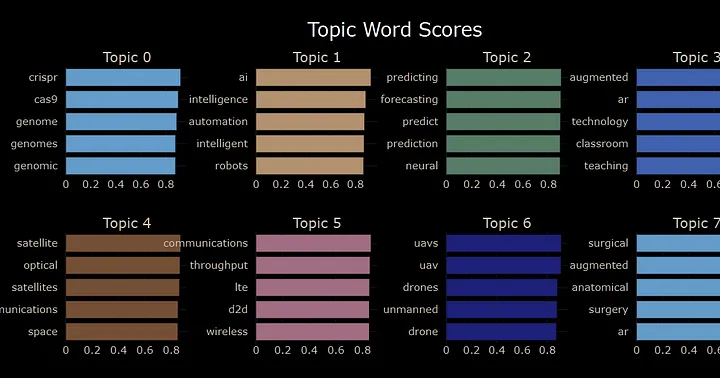
也可用热力图探索主题间相似度。

以上仅为BERTopic部分可视化功能。
借助生成式模型
微调主题表示的最后一步,可借助生成式AI生成能连贯描述主题的表示。
BERTopic提供便捷方式调用OpenAI的GPT模型与主题模型交互。首先构建提示词,向模型展示数据与当前主题表示,要求为每个主题生成短标签。
随后初始化客户端与模型,更新流程。
import openai
from bertopic.representation import OpenAI
#GPT生成主题标签的提示词
prompt = """
I have a topic that contains the following documents:
[DOCUMENTS]
The topic is described by the following key words: [KEYWORDS]
Based on the information above, extract a short topic label in the following format:
topic: <short topic label>
"""
#import GPT
client = openai.OpenAI(api_key='API KEY')
#添加GPT作为表示模型
representation_model = OpenAI(client, model = 'gpt-3.5-turbo', exponential_backoff=True, chat=True, prompt=prompt)
topic_model.update_topics(data['all_text'].tolist(), representation_model=representation_model)
现在回到增强现实主题。
#探究主题表示的变化
topic_model.get_topic(18)
#输出: [('Comparative analysis of virtual and augmented reality for immersive analytics',1)]
主题表示变为“Comparative analysis of virtual and augmented reality for immersive analytics”(沉浸式分析中虚拟与增强现实的比较分析)。主题含义更清晰,能看到文档涉及的目标、技术与领域。
以下是新主题表示的完整列表。

仅需少量代码,就能体会生成式AI对主题模型及其表示的强大支持。当然,构建模型时深入验证输出、多试验不同模型/参数/方法至关重要。
探索主题模型变体
最后,BERTopic提供多种主题模型变体,以适配不同数据与场景,包括时间序列、分层、有监督、半监督等模型。
快速探索分层主题建模的可能性。如下,用scipy创建链接函数以确定主题间距离,轻松适配数据并可视化主题层级。
#创建主题间链接
linkage_function = lambda x: sch.linkage(x, 'single', optimal_ordering=True)
hierarchical_topics = topic_model.hierarchical_topics(data['all_text'], linkage_function=linkage_function)
#可视化主题模型层级
topic_model.visualize_hierarchy(hierarchical_topics=hierarchical_topics)
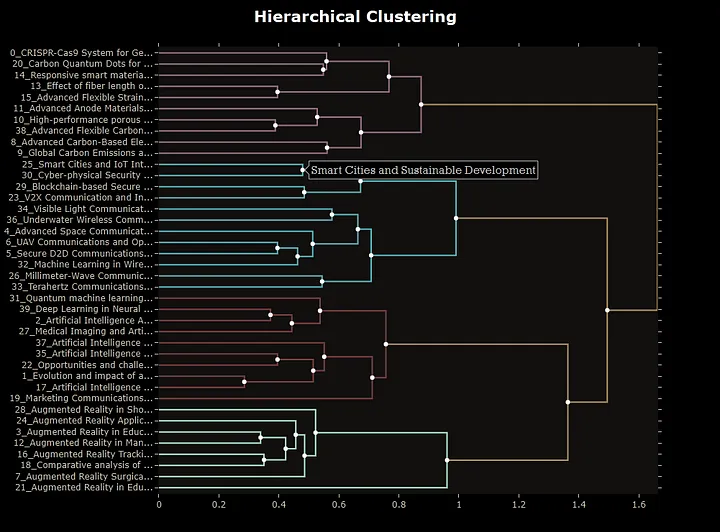
在上述可视化中,可见主题如何聚合为更宽泛的主题。例如,主题25与30合并为“Smart Cities and Sustainable Development”(智慧城市与可持续发展)。该模型支持缩放,可灵活控制主题粒度。
结论
本文展现了BERTopic在主题建模中的强大能力。BERTopic对Transformer与嵌入模型的运用,大幅超越传统方法的效果。其流程兼具强大性与模块化,整合多模型并支持插入适配数据的其他模型。这些模型可微调组合,构建高性能主题模型。
还可集成表示与生成式模型,优化主题表示、提升可解释性。BERTopic提供多种可视化工具,助力深入探索数据与验证模型。最后,BERTopic提供时间序列、分层等主题建模变体,更适配业务场景。


















 9254
9254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









