




这里简要总结java io 流相关操作,不涉及底层源码。
java 中的IO 流机制简单来说就是将数据源从一个地方输出到另外一个地方.这里主要总结3种流,字节流,字符流,缓冲流。
测试说明:
- 1M 字符文件
- 机器是 Surface pro4 4+128
ByteStream
其实ByteStream才是常规意义上的Stream, 是面向字节的,所以对于读入文件是字符来说通常非常慢。读入流有一个read方法,输出流有一个write方法,每次读/写一个字节,遇到-1停止读写。这是我的测试代码,对于1M文件的读写时间大概是 11576 ms,
package javaPlayGym;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class TestByteStream {
public static long workTimeTest(String fileName,String outFile) {
long t1 = System.currentTimeMillis();
try(
FileInputStream in = new FileInputStream(fileName);
FileOutputStream out= new FileOutputStream(outFile);
){
int c;
while ((c = in.read())!=-1) {
out.write(c);
// System.out.print((char)c);
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
};
long time = System.currentTimeMillis() - t1;
System.out.println("ByteStream work time = "+time + "ms");
return time;
}
}
CharStream
后缀以Reader/Writer结尾的都是字符流,每次也是读/写入一个字符(字节),对于字符文件非常快,1M 文件读写时间大概是196ms
测试代码
package javaPlayGym;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class TestCharStream {
public static long workTimeTest(String fileName,String outFile) {
long t1 = System.currentTimeMillis();
try(
FileReader in = new FileReader(fileName);
FileWriter out = new FileWriter(outFile);
){
int c;
while ((c = in.read())!=-1) {
out.write((char)c);
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
long time = System.currentTimeMillis() - t1;
System.out.println("FileReader work time = "+time+"ms");
return time;
}
}
Buffered 流
缓冲流有BufferedReader/Writer和Stream两种,也就是有面向字节和字符的两种缓冲流,缓冲流会带来很大的速度提升,原因是他会在内存中开一块缓冲区,当缓冲区满了再写到磁盘,或者一次读一块区域到缓冲区,满了在读,这样减少磁盘读写,学过计算机组成原理或类似课程的都知道,每次读写磁盘都是需要向操作系统请求系统调用的,这个开销很大,一次请求如果多读/写一些东西那就会减少时间了,
一下是字符缓冲的测试用时75ms
package javaPlayGym;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class TestBufferedRW {
public static long workTimeTest(String inFile,String outFile) {
long t1 = System.currentTimeMillis();
try(
BufferedReader brin = new BufferedReader(new FileReader(inFile));
BufferedWriter bw = new BufferedWriter(new FileWriter(outFile));
){
int c;
while ((c = brin.read())!=-1) {
bw.write((char)c);
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
long time = System.currentTimeMillis() - t1;
System.out.println("Buffered R/w work time = "+time +"ms" );
return time;
}
}
Scanner/Print
这个是初学者都在用的:
Scanner in = new Scanner(System.in)
但是用多了就会发现他非常慢。首先是系统输入没有包装 就是没有加一些缓冲或者改为字符流。
Scanner是用于参数化读取的,(同理Print适用于参数化写入的,类似于System.out 是输出流。)和我们平时使用的一样,有这样一些方法:
- .next: 返回一个String : 以 whiteSpace 来分割字符串,java的WhiteSpace 是定义好的一组字符,: ’ ‘,’\n’
- .nextInt() /nextDouble() 。。。 这些都是类似的,需要注意由于这些参数是基于正则表达式匹配Int和Double的,虽然更加安全,可是却带来了额外的开销,这对于某些算法竞赛选手就很吃亏了,所以许多算法竞赛选手不得不自己写输入输出外挂,但是我的测试发现,如果简单地每次读入一个字符串然后在用相应的Integer.parse 转化的化也能快不少,直接读入一行在分割就更快了。可以取代外挂的作用。下面是读入string和外挂在CF 980 C. Posterized的比较,外挂可参照笔者另外一篇blog java ACM竞赛IO优化Petr模板
版本一
直接Scanner 套 Buffer,用参数化读取public static Scanner in = new Scanner(new BufferedReader(new InputStreamReader(System.in),32678));
Time 342ms
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.util.Arrays;
import java.util.Scanner;
public class Main {
public static final int INF = 0x3f3f3f3f;
public static Scanner in = new Scanner(new BufferedReader(new InputStreamReader(System.in),32678));
public static PrintWriter out = new PrintWriter(new BufferedWriter(new OutputStreamWriter(System.out),32678));
public static void main(String[] args) {
int n = in.nextInt();
int k = in.nextInt();
int[] p = new int[n];
for(int i=0 ; i<n ; ++i)p[i] = in.nextInt();
Solution solver = new Solution(n, k, p);
solver.solve();
for(int i=0 ; i<n ; ++i)out.print(solver.ans[p[i]]+" ");
out.flush();
out.close();
}
}
class Solution{
int n,k;
int[] p;
int[] ans;
public Solution(int n, int k, int[] p) {
super();
this.n = n;
this.k = k;
this.p = p;
ans = new int[256];
Arrays.fill(ans, -1);
}
public void solve() {
ans[0] =0;
for(int i=0 ; i<n ; ++i){
int ret =0;
if(ans[p[i]]!=-1)continue;
int lower = Math.max(-1, p[i]-k);
for(ret = p[i] ; ret >lower ; --ret){
if(ans[ret] !=-1){
if(ans[ret] > lower){
ret = ans[ret];
}else ret++;
break;
}
}
ret = Math.max(ret, lower+1);
for(int j=ret ; j<=p[i] ; ++j)ans[j] = ret;
}
}
}版本二
直接读取字符串,然后在用Interger转化,用时 249ms
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.util.Arrays;
import java.util.Scanner;
public class Main {
public static final int INF = 0x3f3f3f3f;
public static Scanner in = new Scanner(new BufferedReader(new InputStreamReader(System.in),32678));
public static PrintWriter out = new PrintWriter(new BufferedWriter(new OutputStreamWriter(System.out),32678));
public static void main(String[] args) {
int n = Integer.parseInt(in.next());
int k = Integer.parseInt(in.next());
int[] p = new int[n];
for(int i=0 ; i<n ; ++i)p[i] = Integer.parseInt(in.next());// 这句转化带来的优化
Solution solver = new Solution(n, k, p);
solver.solve();
for(int i=0 ; i<n ; ++i)out.print(solver.ans[p[i]]+" ");
out.flush();
out.close();
}
}
class Solution{
int n,k;
int[] p;
int[] ans;
public Solution(int n, int k, int[] p) {
super();
this.n = n;
this.k = k;
this.p = p;
ans = new int[256];
Arrays.fill(ans, -1);
}
public void solve() {
ans[0] =0;
for(int i=0 ; i<n ; ++i){
int ret =0;
if(ans[p[i]]!=-1)continue;
int lower = Math.max(-1, p[i]-k);
for(ret = p[i] ; ret >lower ; --ret){
if(ans[ret] !=-1){
if(ans[ret] > lower){
ret = ans[ret];
}else ret++;
break;
}
}
ret = Math.max(ret, lower+1);
for(int j=ret ; j<=p[i] ; ++j)ans[j] = ret;
}
}
}版本3
外挂用时,171ms
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.util.Arrays;
import java.util.StringTokenizer;
public class Main {
public static final int INF = 0x3f3f3f3f;
public static InputReader in = new InputReader(System.in);
public static PrintWriter out = new PrintWriter(new BufferedWriter(new OutputStreamWriter(System.out), 65536));
public static void main(String[] args) {
int n = in.nextInt();
int k = in.nextInt();
int[] p = new int[n];
for(int i=0 ; i<n ; ++i)p[i] = in.nextInt();
Solution solver = new Solution(n, k, p);
solver.solve();
for(int i=0 ; i<n ; ++i)out.print(solver.ans[p[i]]+" ");
out.flush();
out.close();
}
}
class Solution{
int n,k;
int[] p;
int[] ans;
public Solution(int n, int k, int[] p) {
super();
this.n = n;
this.k = k;
this.p = p;
ans = new int[256];
Arrays.fill(ans, -1);
}
public void solve() {
ans[0] =0;
for(int i=0 ; i<n ; ++i){
int ret =0;
if(ans[p[i]]!=-1)continue;
int lower = Math.max(-1, p[i]-k);
for(ret = p[i] ; ret >lower ; --ret){
if(ans[ret] !=-1){
if(ans[ret] > lower){
ret = ans[ret];
}else ret++;
break;
}
}
ret = Math.max(ret, lower+1);
for(int j=ret ; j<=p[i] ; ++j)ans[j] = ret;
}
}
}
class InputReader{
private final static int BUF_SZ = 65536;
BufferedReader in;
StringTokenizer tokenizer;
public InputReader(InputStream in) {
super();
this.in = new BufferedReader(new InputStreamReader(in),BUF_SZ);
tokenizer = new StringTokenizer("");
}
private String next() {
while (!tokenizer.hasMoreTokens()) {
try {
tokenizer = new StringTokenizer(in.readLine());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
return tokenizer.nextToken();
}
public int nextInt() {
return Integer.parseInt(next());
}
}CF运行截图
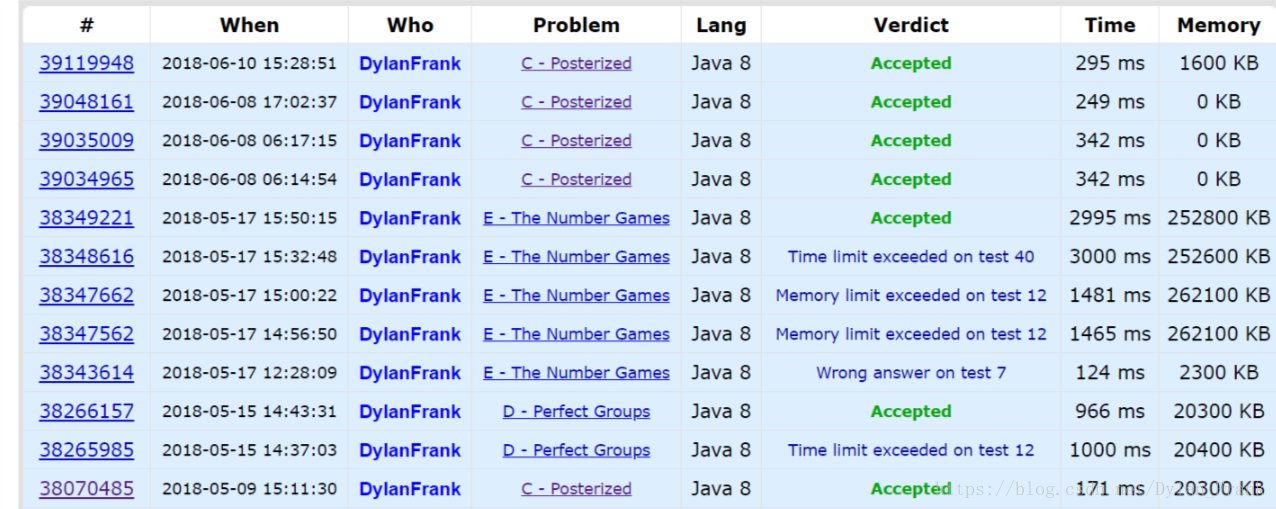
295ms 那个版本是直接读入一行的用时,看来我还得好好研究一下底层源码,我以为直接读入一行会带来优化呢 :(

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









