




 本文介绍了RNN在序列数据生成中的应用,重点讨论了GAN和VAE在图像生成和潜在空间学习中的作用。生成序列数据时,通过softmax温度进行采样策略的选择,如贪婪采样和随机采样。GAN由生成器和判别器构成,通过相互博弈生成逼真图像,而VAE则提供结构化的潜在空间,适用于图像编辑。训练GAN需要精心调整模型架构和参数,以达到生成器和判别器间的平衡。
本文介绍了RNN在序列数据生成中的应用,重点讨论了GAN和VAE在图像生成和潜在空间学习中的作用。生成序列数据时,通过softmax温度进行采样策略的选择,如贪婪采样和随机采样。GAN由生成器和判别器构成,通过相互博弈生成逼真图像,而VAE则提供结构化的潜在空间,适用于图像编辑。训练GAN需要精心调整模型架构和参数,以达到生成器和判别器间的平衡。
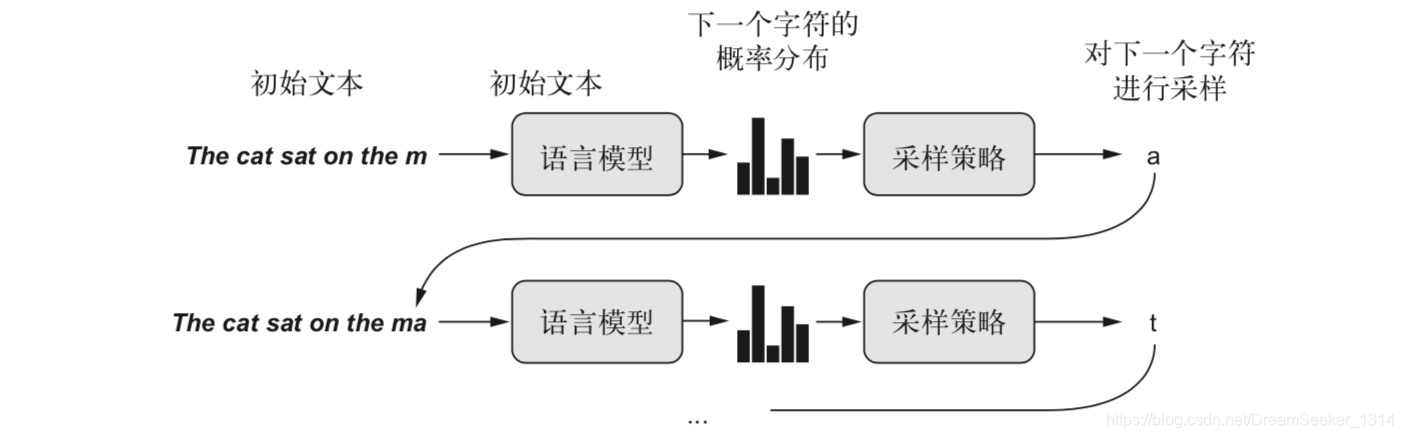
RNN已经被成功应用于音乐生成,对话生成,图像生成,语音合成和分子设计,甚至还可以用于制作电影剧本。如何生成序列数据?使用前面的标记作为输入训练一个网络(通常是RNN或CNN)来预测序列中接下来的一个或多个标记。
这个过程涉及名词:标记、潜在空间、采样、条件数据、soft Max模型等
~~~~~~~~~~~采样策略的重要性~~~~~~~~~~~~~
- 贪婪采样(greedy sampling)
始终选择可能性最大的下一个字符,缺点:重复、可预测的字符串
- 随机采样(stochastic sampling)
在采样过程中引入随机性,即从下一个字符的概率分布中进行采样。
字符均匀概率分布具有最大的熵/entropy,更小的熵可以让生成的序列觉有更加可预测的结构,而更大的熵会得到更加出人意料且更有创造性的序列。训练语言模型并从中采样即给定一个训练好的模型和一个种子文本片段,通过以下步骤完成采样:
(1) 给定目前已生成的文本,从模型中得到下一个字符的概率分布。
(2) 根据某个温度对分布进行重新加权。
(3) 根据重新加权后的分布对下一个字符进行随机采样。
(4) 将新字符添加到文本末尾。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
生成离散的序列数据的方法是: 给定前面的标记,训练一个模型来预测接下来的一个或多个标记。
对于文本来说,这种模型叫作语言模型。它可以是单词级的,也可以是字符级的。对下一个标记进行采样,需要在坚持模型的判断与引入随机性之间寻找平衡。处理这个问题的一种方法是使用 softmax
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 581
581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









