 TextInAPI在身份证识别中的高效应用与使用体验,
TextInAPI在身份证识别中的高效应用与使用体验,




TextIn API使用心得
目前,在项目开发中遇到了需要识别用户的身份证,提取出里面的关键信息。然后系统自动补齐用户的姓名、身份证号码、年龄等关键信息,这里需要保证信息的正确提取。经过网上调研发现,TextIn合合信息旗下的智能文字识别产品非差好用,调用方便,刚好契合项目需求。
1、TextIn介绍
TextIn是合合信息旗下的智能文字识别产品,提供图像处理、文字表格识别、文档内容提取等多种OCR云服务。TextIn支持多种技术实现方案,满足不同业务场景的智能识别需求,服务于全球数千家企业及上亿用户。
2、TextIn API的调用
首先登录网站https://www.textin.com,注册登录,选择自己想要使用的功能。这里我们选择卡证文字识别,可以看到其不止能够识别身份证,还能识别名片、营业执照等国内外卡证文字。点击卡证文字识别。
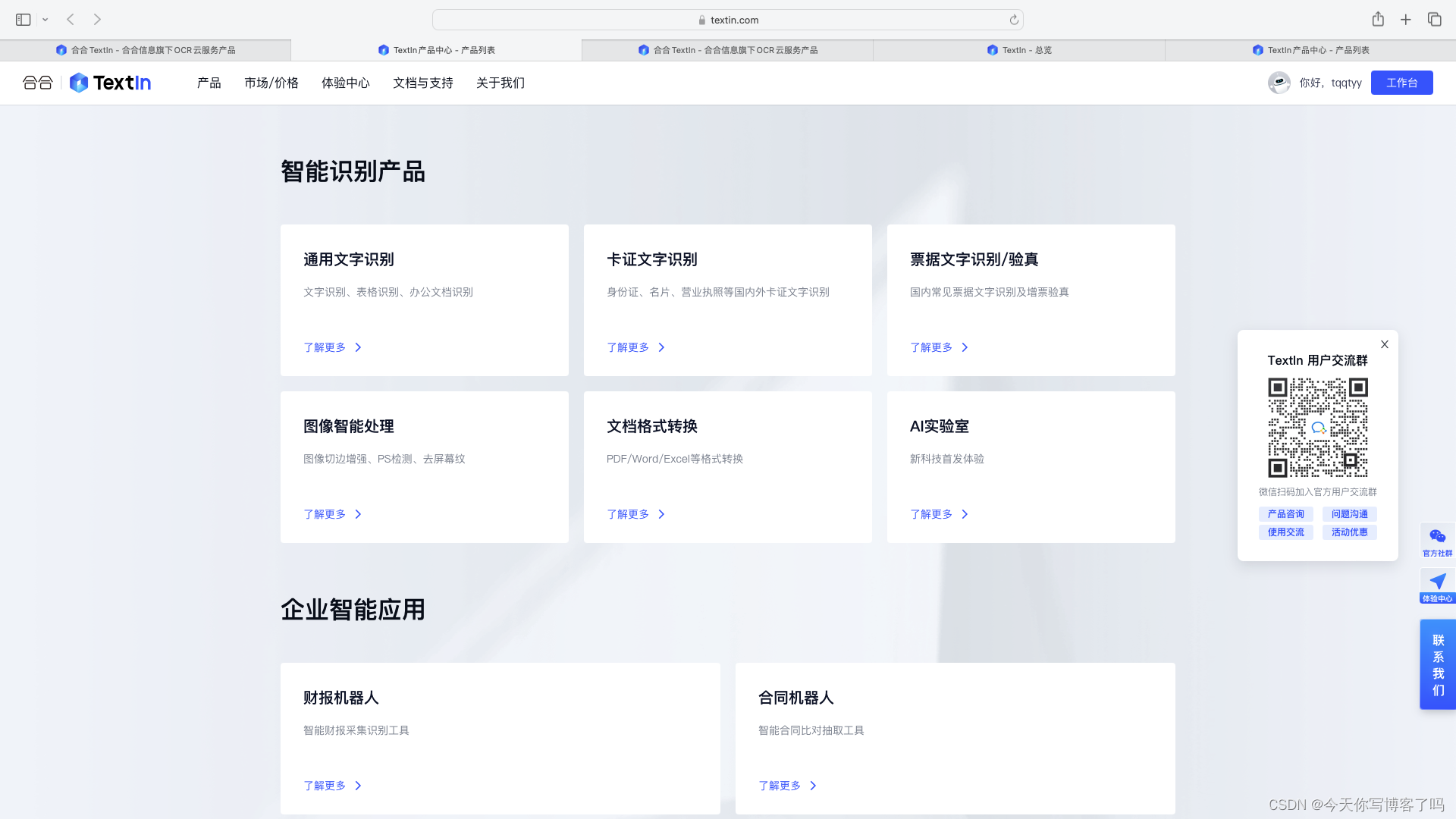
点击立即体验。
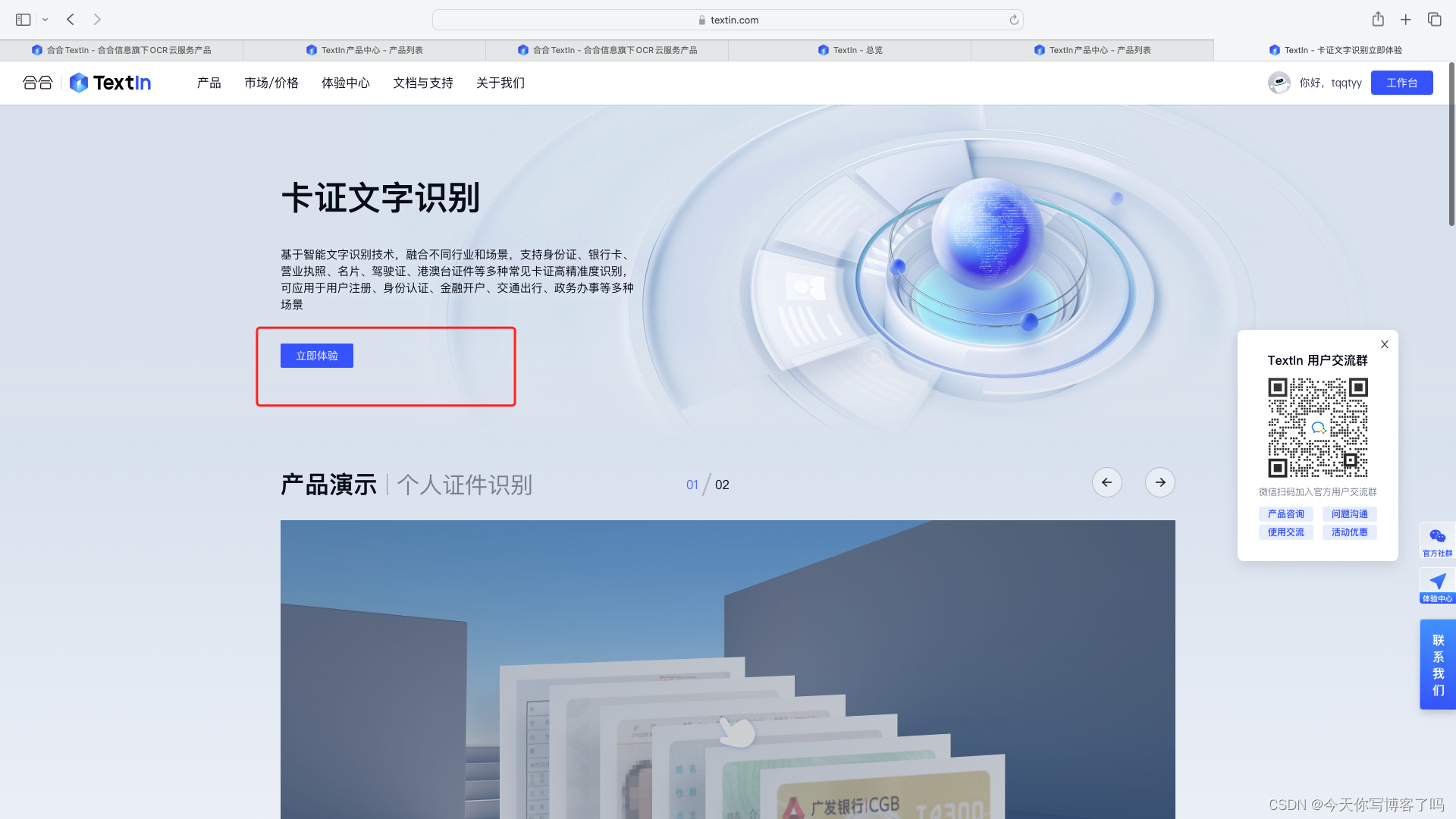
然后选择我们需要的身份证识别。
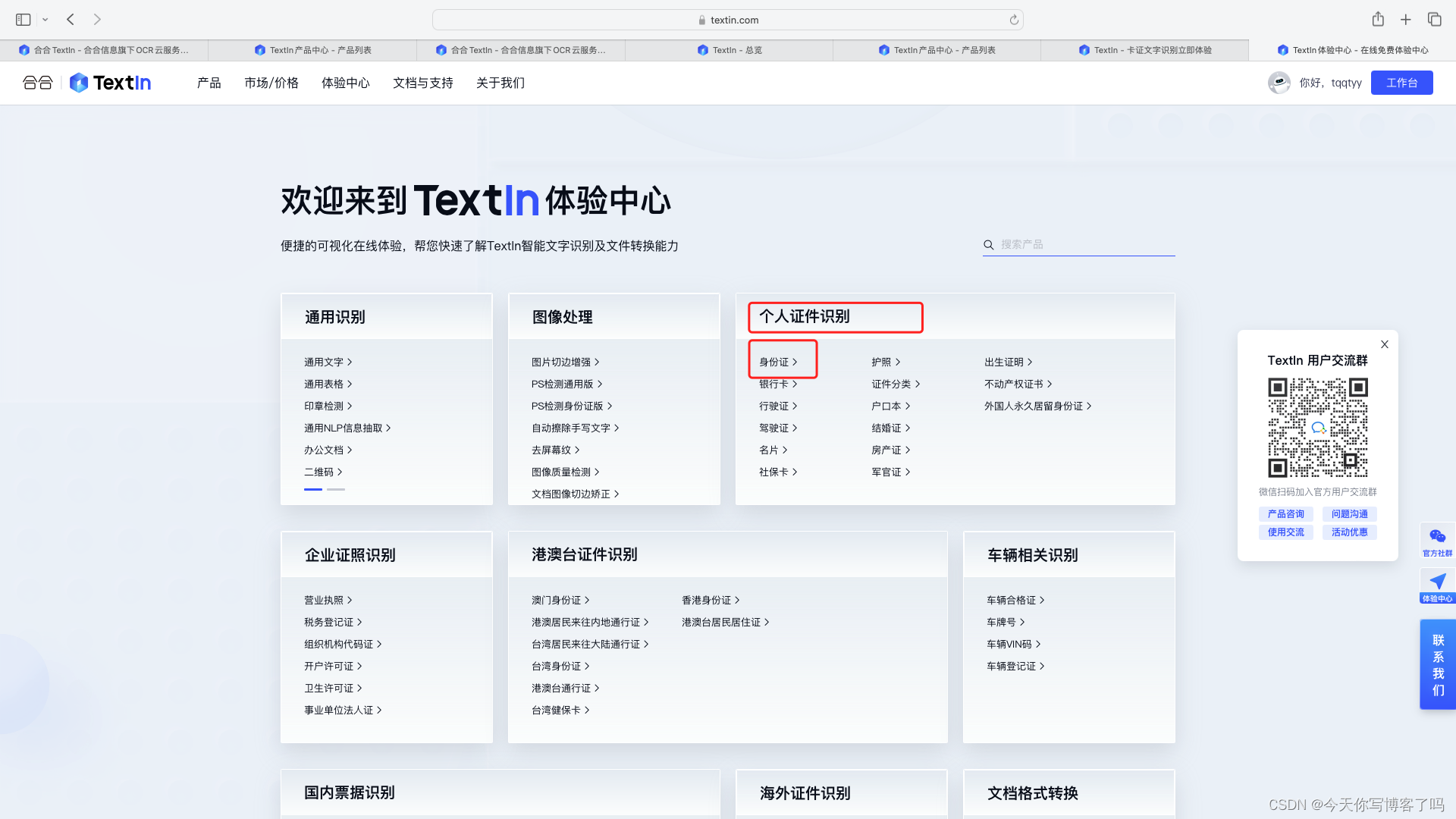
随后我们可以看到识别过后返回给的json结果数据结构。
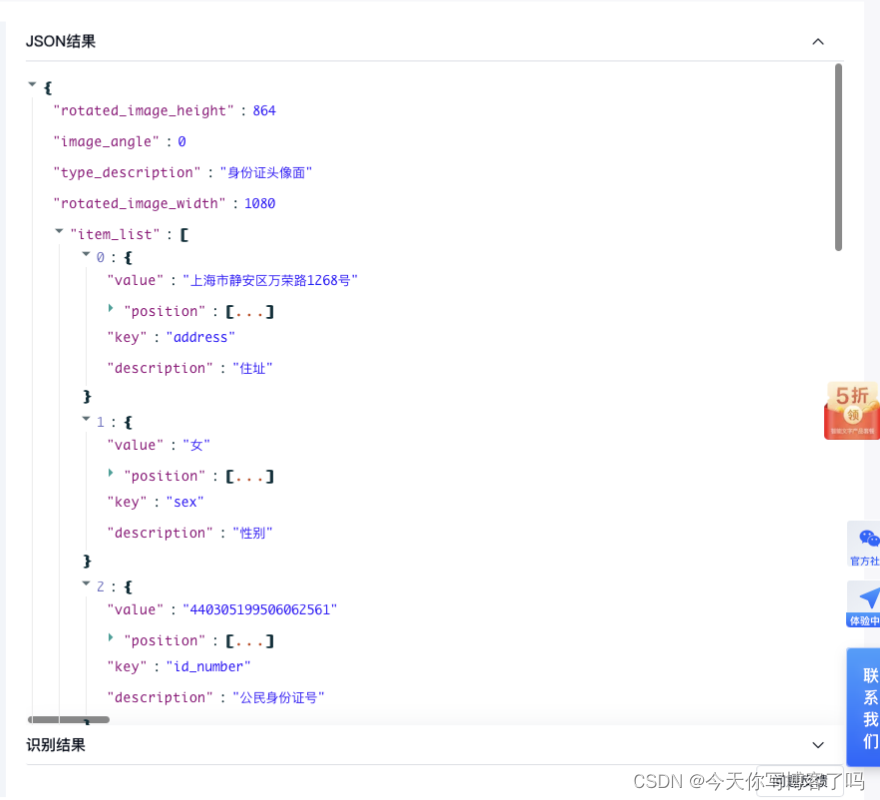
然后我们点击右上角的集成API即可查看在项目代码中的使用方法。在我们的项目中,是uniapp中调用,所以我这里选择查看node.js的实例代码。
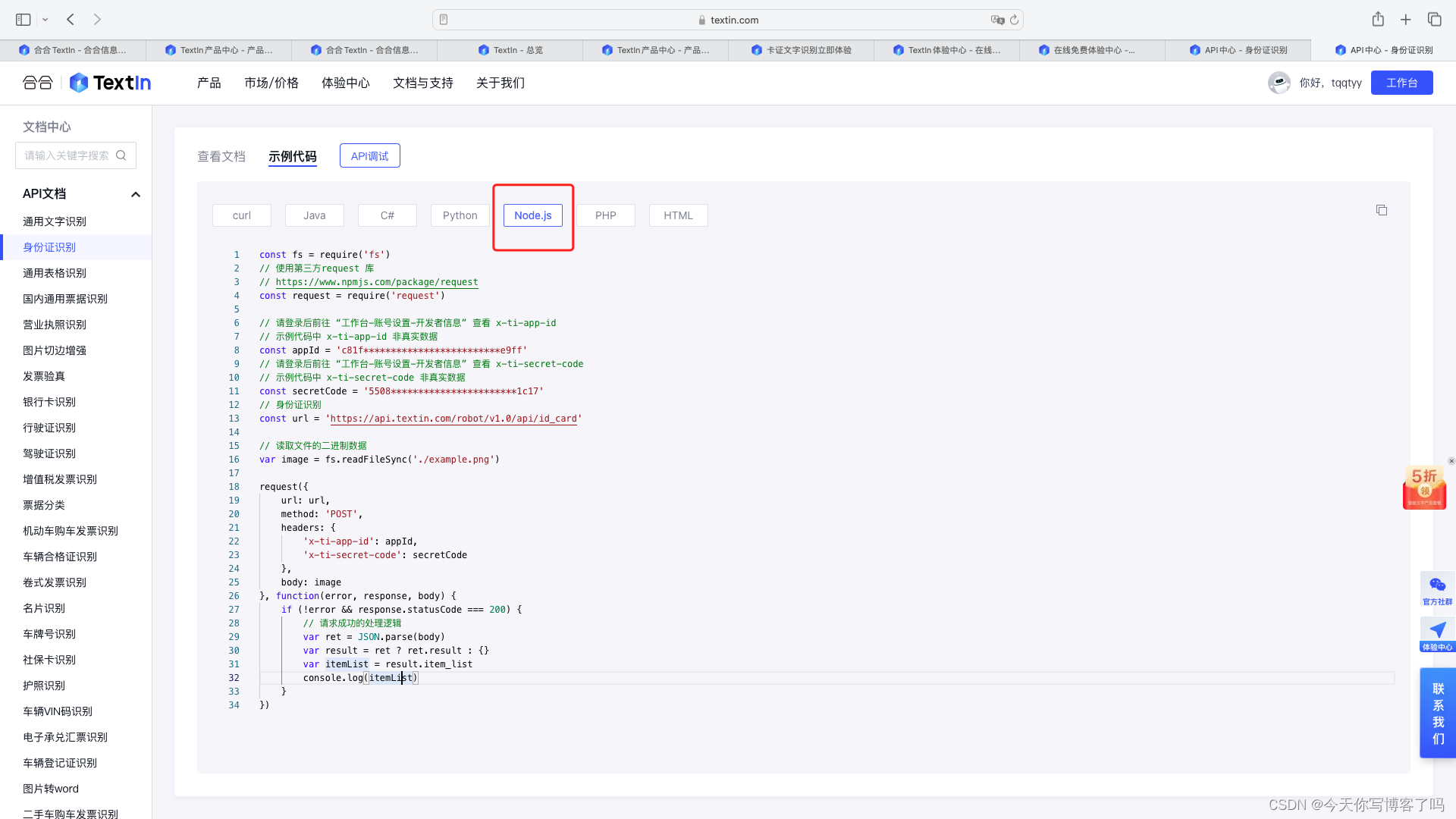
代码内容为:
const fs = require('fs')
// 使用第三方request 库
// https://www.npmjs.com/package/request
const request = require('request')
// 请登录后前往 “工作台-账号设置-开发者信息” 查看 x-ti-app-id
// 示例代码中 x-ti-app-id 非真实数据
const appId = 'c81f*************************e9ff'
// 请登录后前往 “工作台-账号设置-开发者信息” 查看 x-ti-secret-code
// 示例代码中 x-ti-secret-code 非真实数据
const secretCode = '5508***********************1c17'
// 身份证识别
const url = 'https://api.textin.com/robot/v1.0/api/id_card'
// 读取文件的二进制数据
var image = fs.readFileSync('./example.png')
request({
url: url,
method: 'POST',
headers: {
'x-ti-app-id': appId,
'x-ti-secret-code': secretCode
},
body: image
}, function(error, response, body) {
if (!error && response.statusCode === 200) {
// 请求成功的处理逻辑
var ret = JSON.parse(body)
var result = ret ? ret.result : {}
var itemList = result.item_list
console.log(itemList)
}
})
其中appId与secretCode需要自行前往控制台查看,配置好,在代码中即可调用,非差方便。后续设计的业务流程自行封装即可。在我们的项目测试中,暂未出现识别错误现象,准确率非常高!
3、使用心得
在调用TextIn API进行身份证识别时,我发现该功能非常方便实用。首先,接口文档清晰明了,参数设置简单,只需要传入待识别的身份证图片即可。其次,识别速度快,准确率高,可以满足项目对身份证信息快速提取的需求。
相比较百度、阿里等公司的api,TextIn API不仅提供了简单易用的接口,而且调用文档及其简洁易懂,在识别速度和准确率方面表现出色。无论是身份证识别、文字识别还是其他功能,TextIn API都能够帮助我们快速、准确地处理文本信息,极大地提高了我们的工作效率。

















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









