




以下是「 豆包MarsCode 体验官」优秀文章,作者谦哥。
🚀 项目地址:remotejobs.justidea.cn/
🚀 项目截图:
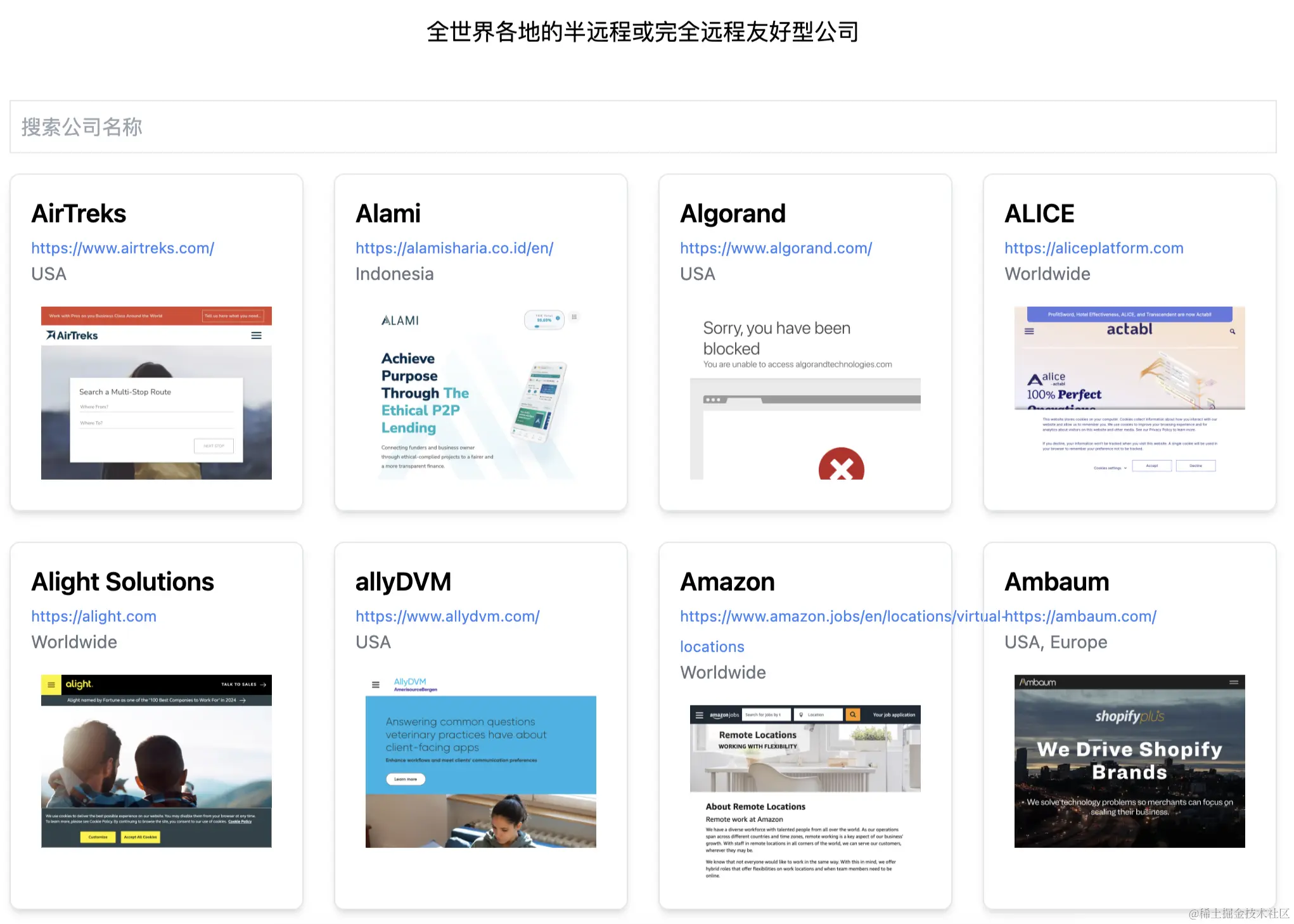
数据处理
感谢开源项目:https://github.com/remoteintech/remote-jobs
网站信息获取:把项目里 md 文件里的网站列表抓取保存到 supabase 的数据库里(这一步可以在本地完成)
import fetch from 'node-fetch';
import {
createClient } from '@supabase/supabase-js';
const SUPABASE_URL = '';
const SUPABASE_KEY = '';
const supabase = createClient(SUPABASE_URL, SUPABASE_KEY);
async function fetchData() {
const response = await fetch('https://raw.githubusercontent.com/remoteintech/remote-jobs/main/README.md');
const text = await response.text();
// 解析 README.md 内容,提取 name, website, region
const jobs = parseJobs(text);
// 将数据存储到 Supabase
for (const job of jobs) {
await supabase
.from('remote-jobs')
.insert(job);
}
}
function parseJobs(mdText) {
const lines = mdText.split('\n');
const jobs = [];
lines.forEach(line => {
// 例子:'[Bitovi](/company-profiles/bitovi.md) | https://bitovi.com/ | Worldwide'
const match = line.match(/\[([^\]]+)\]\(([^)]+)\)\s*\|\s*(https?:\/\/[^\s|]+)\s*\|\s*(.+)/);
if (match) {
const [, name, ,website, region] = match;
jobs.push({
name, website, region });
}
});
return jobs;
}
fetchData();
网站截图: 把上一步获取到的网址用 puppeteer 循环截图,最后上传到 supabase 的 storage 里
import puppeteer from 'puppeteer'
import fs from 'fs'
import {
createClient } from '@supabase/supabase-js'
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章





















 到【灌水乐园】发言
到【灌水乐园】发言








