




 本文介绍了如何在ApacheDolphinScheduler中支持Flink任务类型,包括任务创建、配置Flink环境、上传主程序包以及执行WordCount示例,帮助企业提升数据处理效率和可靠性。
本文介绍了如何在ApacheDolphinScheduler中支持Flink任务类型,包括任务创建、配置Flink环境、上传主程序包以及执行WordCount示例,帮助企业提升数据处理效率和可靠性。
随着大数据技术的快速发展,很多企业开始将Flink引入到生产环境中,以满足日益复杂的数据处理需求。而作为一款企业级的数据调度平台,Apache DolphinScheduler也跟上了时代步伐,推出了对Flink任务类型的支持。
Flink是一个开源的分布式流处理框架,具有高吞吐量、低延迟和准确性等特点,广泛应用于实时数据分析、机器学习等场景。通过DolphinScheduler的Flink任务类型,用户可以轻松地将Flink作业纳入到整个数据调度流程中,大大提高了数据处理的效率和可靠性。本文将介绍如何在DolphinScheduler中支持Flink节点,包括任务创建、设置等。
Flink节点
Flink 任务类型,用于执行 Flink 程序。对于 Flink 节点:
- 当程序类型为 Java、Scala 或 Python 时,worker 使用 Flink 命令提交任务 flink run。
- 当程序类型为 SQL 时,worker 使用sql-client.sh 提交任务。
创建任务
- 点击项目管理-项目名称-工作流定义,点击“创建工作流”按钮,进入 DAG 编辑页面;
- 拖动工具栏的 任务节点到画板中。
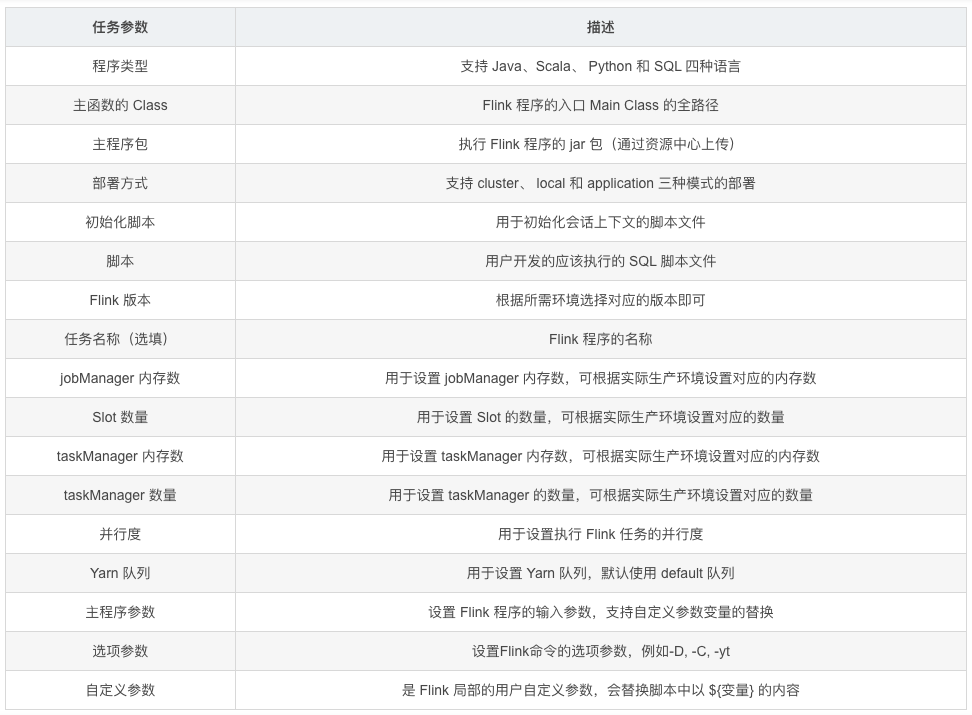
任务参数
任务样例
执行 WordCount 程序
本案例为大数据生态中常见的入门案例,常应用于 MapReduce、Flink、Spark 等计算框架。主要为统计输入的文本中,相同的单词的数量有多少。
1.在 DolphinScheduler 中配置 Flink 环境
若生产环境中要是使
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5383
5383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











