




 本文深入分析了DolphinScheduler的源码,包括核心组件如MasterSchedulerThread、MasterExecThread、MasterTaskExecThread等的工作原理,以及与Zookeeper、Quartz的集成方式。探讨了流程定义、实例化、任务执行、故障转移等关键机制。
本文深入分析了DolphinScheduler的源码,包括核心组件如MasterSchedulerThread、MasterExecThread、MasterTaskExecThread等的工作原理,以及与Zookeeper、Quartz的集成方式。探讨了流程定义、实例化、任务执行、故障转移等关键机制。
本文是基于1.2.0版本进行分析,与最新版本的实现有一些出入,还请读者辩证的看待本源码分析。具体细节可能描述的不是很准确,仅供参考。
1.源码版本
DolphinScheduler-1.2.0版本
2.技术框架
所有模块均采用比较流行的SpringBoot框架
3.架构图
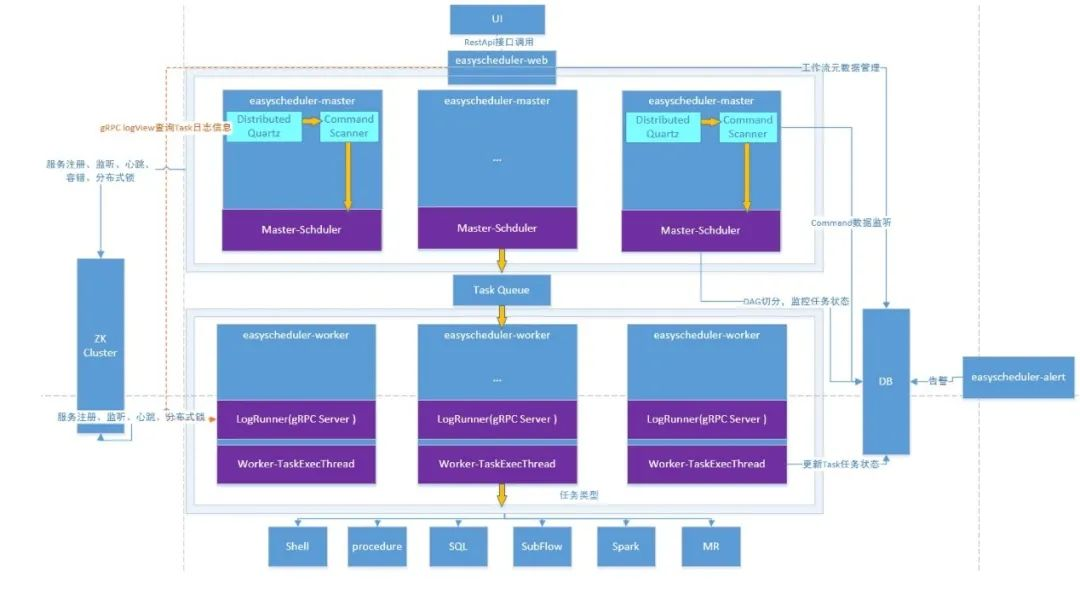
4.重要概念
4.1流程定义
在DolphinScheduler中,作业的DAG被命名为“流程定义”。
4.2流程实例
流程实例是流程定义的实例化,可以通过手动启动或定时调度生成,流程定义每运行一次,产生一个流程实例。流程实例由Master解析流程定义生成。
4.3任务实例
任务实例是流程定义中任务节点的实例化,标识着具体的任务执行状态。
4.4定时
DAG的触发频率。与DAG概念隔离,单独创建、单独管理,一个DAG可以没有与之对应的定时。
5.架构说明
5.1Quartz
内部对Quartz进行了一个封装,org.apache.dolphinscheduler.server.quartz.QuartzExecutors仅仅提供增加、删除作业的基础功能。其作业的状态等信息保存在数据库中以QRTZ_开头的表。
为了将实际作业的定义与Quartz隔离,抽象了一个ProcessScheduleJob类,用它来创建JobDetail。
该类仅仅是根据流程定义的定时等信息创建了一个CommandType.SCHEDULER类型的Command对象,然后插入了数据库,并没有的执行任务的具体逻辑。
5.2MasterSchedulerThread
架构图中有一个CommandScanner,对应到源码中就是org.apache.dolphinscheduler.server.master.runner.MasterSchedulerThread类。
这是一个扫描线程,定时扫描数据库中的 t_ds_command 表,根据不同的命令类型进行不同的业务操作。扫描的SQL如下:
SELECT command.*FROM t_ds_command command JOIN t_ds_process_definition definition ON command.process_definition_id = definition.idWHERE definition.release_state = 1 AND definition.flag = 1ORDER BY command.update_time ASCLIMIT 1
定时的默认是1秒,由Constants.SLEEP_TIME_MILLIS设置。Command的创建与执行是异步的。
MasterSchedulerThread类查询到一个Comamand后将其转化为一个ProcessInstance,交由MasterExecThread进行执行。
MasterSchedulerThread功能比较简单,就是负责衔接Quartz创建的Command,一个桥梁的作用。
5.3MasterExecThread
org.apache.dolphinscheduler.server.master.runner
.MasterExecThread负责执行ProcessInstance,功能主要是DAG任务切分、任务提交监控等其他逻辑处理。
其实DAG切割也比较简单,首先找入度为0的任务(也就是没有任务依赖),放到准备提交队列;任务执行成功后,扫描后续的任务,如果该任务的所有依赖都成功,则执行该任务;循环处理。MasterExecThread随着DAG中所有任务的执行结束而结束。
一个任务执行,会分别占用master和worker各一个线程,这一点不太好。
同样,该线程在一个逻辑处理结束后,也会休眠1秒,由Constants.SLEEP_TIME_MILLIS设置。
当然在MasterExecThread中,也没有执行具体的任务逻辑,只是创建了一个MasterTaskExecThread负责任务的“执行”。
5.4MasterTaskExecThread
org.apache.dolphinscheduler.server.master.runner.
MasterTaskExecThread由MasterExecThread负责创建。其功能主要就是负责任务的持久化,简单来说就是把TaskInstacne信息保存到数据库中,同时如果一个任务满足执行条件,也会把任务ID提交到TaskQueue中的。
这个线程会每隔1秒(Constants.SLEEP_TIME_MILLIS设置)查询作业的状态,直到作业执行完毕(不管是成功还是失败)。
这样来看,一个任务执行,会占用master2个线程。
5.5TaskQueue
架构图中Master/Worker通信的重要渠道,它把待执行的队列放到了TaskQueue,由Worker获取到之后,执行具体的业务逻辑。根据技术架构介绍,这个TaskQueue是由Zookeeper实现。由此也可以看出,Master、Worker是没有直接的物理交互的。
5.6FetchTaskThread
org.apache.dolphinscheduler.server.worker.runner.FetchTaskThread循环从TaskQueue中获取任务,并根据不同任务类型调用TaskScheduleThread对应执行器。每次循环依旧休眠1秒。
FetchTaskThread会一次性查询所有任务,检查当前是否有任务。这个设计有点不合理。
如果当前有可执行的任务,则一次性取出当前节点剩余可执行任务数量的任务ID。
根据任务ID查询创建TaskInstance,交由TaskScheduleThread具体执行。
由此可见FetchTaskThread每个Worker只有一个,TaskScheduleThread会有很多个。
5.7TaskScheduleThread
org.apache.dolphinscheduler.server.worker.runner.TaskScheduleThread负责任务的具体执行。该线程的逻辑比较清晰,就是构造获取任务相关的文件、参数等信息,创建Process类,执行对应的命令行,然后等待其执行完毕,获取标准输出、标准错误输出、返回码等信息。
5.8LoggerServer
org.apache.dolphinscheduler.server.rpc.LoggerServer跟Worker、Master属于同一级别,都是需要单独启动的进程。这就是一个RPC服务器,提供日志分片查看、刷新和下载等功能。
6.项目结构
6.1模块
dolphinscheduler-ui 前端页面模块
dolphinscheduler-server 核心模块。包括master/worker等功能
dolphinscheduler-common 公共模块。公共方法或类
dolphinscheduler-api Restful接口。前后端交互层,与master/worker交互等功能
dolphinscheduler-dao 数据操作层。实体定义、数据存储
dolphinscheduler-alert 预警模块。与预警相关的方法、功能
dolphinscheduler-rpc 日志查看。提供日志实时查看rpc功能
dolphinscheduler-dist 与编译、分发相关的模块。没有具体逻辑功能
7.源码分析方法
UI功能不分析
从与UI交互的API模块开始着手看
重点分析核心功能
非核心功能仅做了解
8.模块-dolphinscheduler-api
API接口层,主要负责处理前端UI层的请求。该服务统一提供RESTful api向外部提供请求服务。接口包括工作流的创建、定义、查询、修改、发布、下线、手工启动、停止、暂停、恢复、从该节点开始执行等等。
涉及的API太多,不宜深入研究,只研究其大致框架、功能。具体的API列表及其使用方法可查看官方文档。
8.1启动入口
org.apache.dolphinscheduler.api下面有两个类:ApiApplicationServer、CombinedApplicationServer。
从ApiApplicationServer来看就是启动一个SpringBoot应用。
CombinedApplicationServer除了启动一个SpringBoot应用之外,还启动了LoggerServer、AlertServer。
@SpringBootApplication@ConditionalOnProperty(prefix = "server", name = "is-combined-server", havingValue = "true")@ServletComponentScan@ComponentScan("org.apache.dolphinscheduler")@Import({MasterServer.class, WorkerServer.class})@EnableSwagger2public class CombinedApplicationServer extends SpringBootServletInitializer {
public static void main(String[] args) throws Exception {
ApiApplicationServer.main(args);
LoggerServer server = new LoggerServer(); server.start();
AlertServer alertServer = AlertServer.getInstance(); alertServer.start(); }}
CombinedApplicationServer与ApiApplicationServer的区别:是否内嵌LoggerServer、AlertServer。而且当server.is-combined-server为true时,会自动启动CombinedApplicationServer。
也不知道是否内嵌的意义在哪里,直接内嵌不好么?
对于SpringBoot应用,接口一般都在controller中。org.apache.dolphinscheduler.api.controller包有以下几个Controller:
AccessTokenController
ProcessInstanceController
AlertGroupController
ProjectController
BaseController
QueueController
DataAnalysisController
ResourcesController
DataSourceController
SchedulerController
ExecutorController
TaskInstanceController
LoggerController
TaskRecordController
LoginController
TenantController
MonitorController
UsersController
ProcessDefinitionController
WorkerGroupController
因为在DolphinScheduler调度中最重要的一个概念就是流程定义,所以我们从ProcessDefinitionController入手简要分析这个模块的基本功能。
8.2ProcessDefinitionController
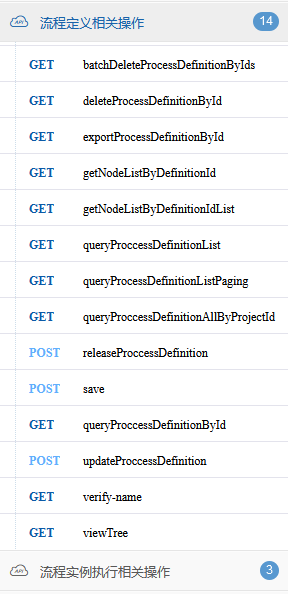
在官方文档中,可以看到org.apache.dolphinscheduler.api.controller.ProcessDefinitionController大概有14个接口。
ProcessDefinitionController中只有一个字段ProcessDefinitionService,从名称以及自身经验来看,可以知道ProcessDefinitionController会负责HTTP请求的参数解析、参数校验、返回值等等,与业务无关的逻辑;具体的业务逻辑会交给ProcessDefinitionService类处理。
由此我们可以类比分析其他所有的controller,都会有一个对应的service处理业务相关的逻辑。
public Result createProcessDefinition(@ApiIgnore @RequestAttribute(value = Constants.SESSION_USER) User loginUser, @ApiParam(name = "projectName", value = "PROJECT_NAME", required = true) @PathVariable String projectName, @RequestParam(value = "name", required = true) String name, @RequestParam(value = "processDefinitionJson", required = true) String json, @RequestParam(value = "locations", required = true) String locations, @RequestParam(value = "connects", required = true) String connects, @RequestParam(value = "description", required = false) String description) {
try { logger.info("login user {}, create process definition, project name: {}, process definition name: {}, " + "process_definition_json: {}, desc: {} locations:{}, connects:{}", loginUser.getUserName(), projectName, name, json, description, locations, connects); Map<String, Object> result = processDefinitionService.createProcessDefinition(loginUser, projectName, name, json, description, locations, connects); return returnDataList(result); } catch (Exception e) { logger.error(Status.CREATE_PROCESS_DEFINITION.getMsg(), e); return error(Status.CREATE_PROCESS_DEFINITION.getCode(), Status.CREATE_PROCESS_DEFINITION.getMsg()); }}
上面是createProcessDefinition的源码,逻辑比较清晰,就是接收、校验HTTP的参数,然后调用processDefinitionService.createProcessDefinition函数,返回结果、处理异常。
但这段代码有一个controller与service分隔不清的地方:HTTP返回的结果由谁处理。此处返回结果是由service负责的,service会创建一个Map<String, Object>类型的result字段,然后调用result.put("processDefinitionId",processDefine.getId());设置最终返回的数据。其实个人是不敢苟同这种做法的,严格来说,service只返回与业务相关的实体,HTTP具体返回什么信息应该交由controller处理。
8.3ProcessDefinitionService
org.apache.dolphinscheduler.api.service.ProcessDefinitionService承担流程定义具体的CURD逻辑,调用各种mapper、dao。
public Map<String, Object> createProcessDefinition(User loginUser, String projectName, String name, String processDefinitionJson, String desc, String locations, String connects) throws JsonProcessingException {
Map<String, Object> result = new HashMap<>(5); Project project = projectMapper.queryByName(projectName); // check project auth Map<String, Object> checkResult = projectService.checkProjectAndAuth(loginUser, project, projectName); Status resultStatus = (Status) checkResult.get(Constants.STATUS); if (resultStatus != Status.SUCCESS) { return checkResult; }
ProcessDefinition processDefine = new ProcessDefinition(); Date now = new Date();
ProcessData processData = JSONUtils.parseObject(processDefinitionJson, ProcessData.class); Map<String, Object> checkProcessJson = checkProcessNodeList(processData, processDefinitionJson); if (checkProcessJson.get(Constants.STATUS) != Status.SUCCESS) { return checkProcessJson; }
processDefine.setName(name); processDefine.setReleaseState(ReleaseState.OFFLINE); processDefine.setProjectId(project.getId()); processDefine.setUserId(loginUser.getId()); processDefine.setProcessDefinitionJson(processDefinitionJson); processDefine.setDescription(desc); processDefine.setLocations(locations); processDefine.setConnects(connects); processDefine.setTimeout(processData.getTimeout()); processDefine.setTenantId(processData.getTenantId());
//custom global params List<Property> globalParamsList = processData.getGlobalParams(); if (globalParamsList != null && globalParamsList.size() > 0) { Set<Property> globalParamsSet = new HashSet<>(globalParamsList); globalParamsList = new ArrayList<>(globalParamsSet); processDefine.setGlobalParamList(globalParamsList); } processDefine.setCreateTime(now); processDefine.setUpdateTime(now); processDefine.setFlag(Flag.YES); processDefineMapper.insert(processDefine); putMsg(result, Status.SUCCESS); result.put("processDefinitionId",processDefine.getId()); return result; }
研读上面代码我们知道createProcessDefinition大概有以下功能:
-
校验当前用户是否拥有所属项目的权限
校验流程定义JSON是否合法。例如是否有环
构造ProcessDefinition对象插入数据库
设置HTTP返回结果
因为这些都不是核心逻辑,都不再深入展开。
ProcessDefinitionService的功能非常不合理,居然还有鉴权的功能,按照我的理解,有一个校验、插入数据库的功就可以了,其他的功能都可以抛出去。
dolphinscheduler-api其他的功能都不在分析,因为到此流程定义信息已经写入到了数据库,跟API模块已经没有关系了。但需要知道ProcessDefinition对象插入到了哪张表,这样才知道如何查询、更新这个表的。这个表就是前后台逻辑交互的关键。从ProcessDefinition定义可以看出,数据最终插入了t_ds_process_definition表。
@Data@TableName("t_ds_process_definition")public class ProcessDefinition
其实也可以不用关注具体插入到了哪张表,好像只需要关系哪个地方用ProcessDefinitionMapper查询了数据就行了。
但根据之前的概念定义,我们知道每个流程定义是需要靠“定时”周期性触发的,这样的话我们可以猜测,系统并不会直接用ProcessDefinitionMapper查询流程定义,而是会根据定时关联的ProcessDefinition来调起DAG。这一点在MasterSchedulerThread的分析中已经可以看出来了。
8.4SchedulerController与SchedulerService
考虑到Controler逻辑非常简单(不合理),此处将controller和service合并分析。
同样SchedulerController几乎没有什么逻辑,全都交给了SchedulerService层。这里只分析SchedulerService.insertSchedule,简单浏览代码后,可以发现它跟createProcessDefinition逻辑差不多:
-
校验当前用户是否拥有所属项目的权限
校验流程定义JSON是否合法。例如是否有环
构造Schedule对象插入数据库
设置HTTP返回结果
当然除了上面4点还查询、更新了ProcessDefinition,主要是将Schedule和ProcessDefinition进行关联。
9.模块-dolphinscheduler-server
9.1MasterSchedulerThread
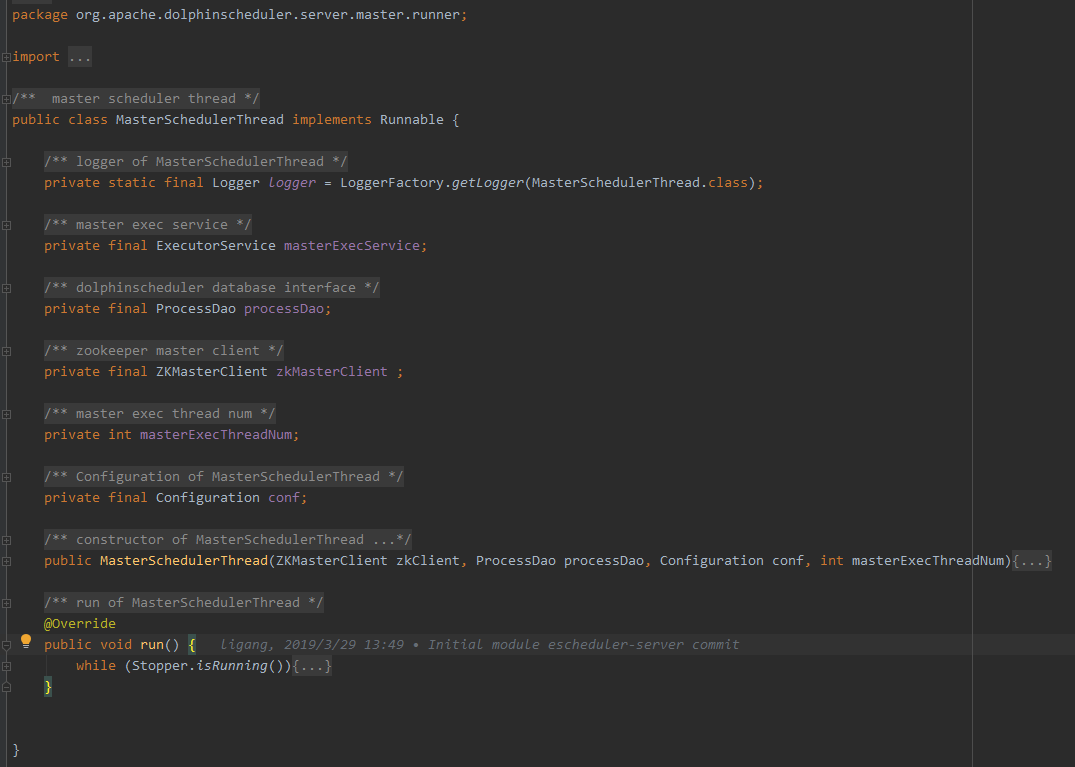
以上是MasterSchedulerThread类的概览图。
MasterSchedulerThread实现Runnable接口,很明显主要的逻辑应该在run方法内,而且根据经验以及前面的分析可以知道,这个方法内是一个“死”循环,且为了避免CPU飙升,会休眠一小段时间。
下面我们逐步展开、分析MasterSchedulerThread类
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6891
6891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











