




一、Hudi介绍
hudi就是帮助管理数据的,hive也是数仓工具,帮助管理数据,hudi不存储不分析数据,只是管理。比如它可以帮助hdfs更好的管理数据,可以对hfds中的数据进行更新删除,小文件合并,也可以实时的将数据写入(数据入湖)
1.1 Hudi与数仓的区别
数据仓库:
数据仓库的特点是本身不生产数据,也不最终消费数据。
每个企业根据自己的业务需求可以分成不同的层次。但是最基础的分层思想,理论上分为三个层:操作型数据层(ODS)、数据仓库层(DW)和数据应用层(DA)。
数据胡:
数据湖(Data Lake)和数据库、数据仓库一样,都是数据存储的设计模式,现在企业的数据仓库都会通过分层的方式将数据存储在文件夹、文件中。
数据湖是一个集中式数据存储库,用来存储大量的原始数据,使用平面架构来存储数据。
数据湖可以包括来自关系数据库的结构化数据(行和列)、半结构化数据(CSV、日志、XML、JSON)、非结构化数据(电子邮件、文档、pdf)和二进制数据(图像、音频、视频)。
数据湖中数据,用于报告、可视化、高级分析和机器学习等任务。
```请添加图片描述,源站可能有防盗链机制,建议将图片保存下来直接上传
数据质量方面可以直接将数据放到lack中,所以如果原始数据丢失了,很难去做监控和找回的操作。
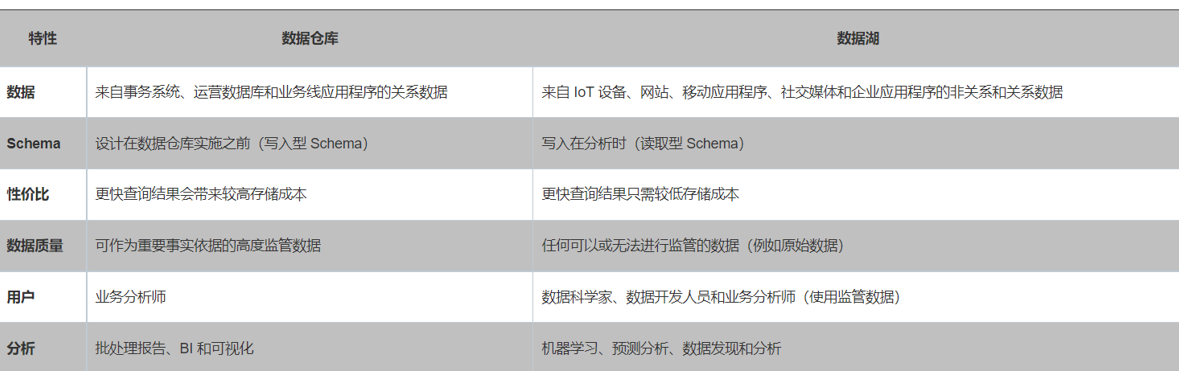
1.2 数仓和数据湖的优缺点
总结:
数据湖并不能替代数据仓库,数据仓库在高效的报表和可视化分析中仍有优势。
也有很多的半结构化数据需要做分析处理,这就体现了数据胡的优势
数据仓库:使用良好范式规范数据,但无法生成数据所需的洞察。
数据湖:新的原始数据存储和处理范式,但缺乏结构和治理,会迅速沦为“数据沼泽”。
所以数据胡很多时候不会单独使用,这就有了仓湖一体,同时吸收数仓和数据湖的优点,使数据分析师和数据科学家能在同一数据存储中对数据进行操作,并且以低成本的数据存储和提高对数据的管理和治理
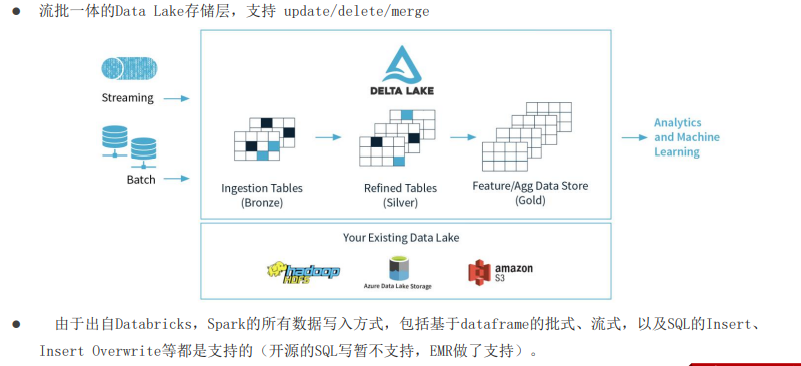
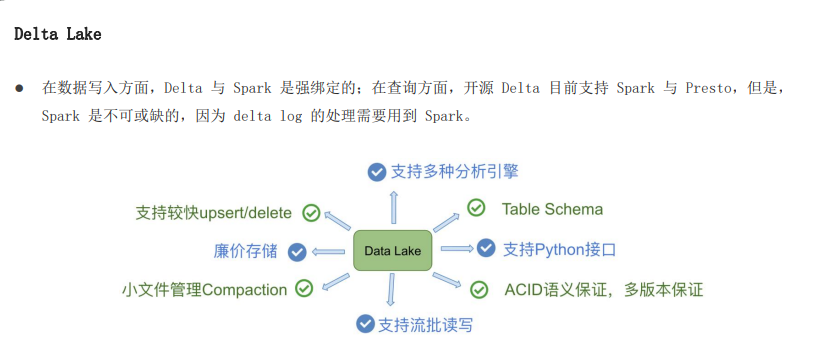
1.3 数据湖三大框架
目前流行的三大开源数据湖方案是:data lake 、apache iceberg 、apache hudi
data lake:
apache iceberg:以类似与sql的形式高性能的处理大型的开放式表

apache hudi:管理大型分析数据集在hdfs上的存储
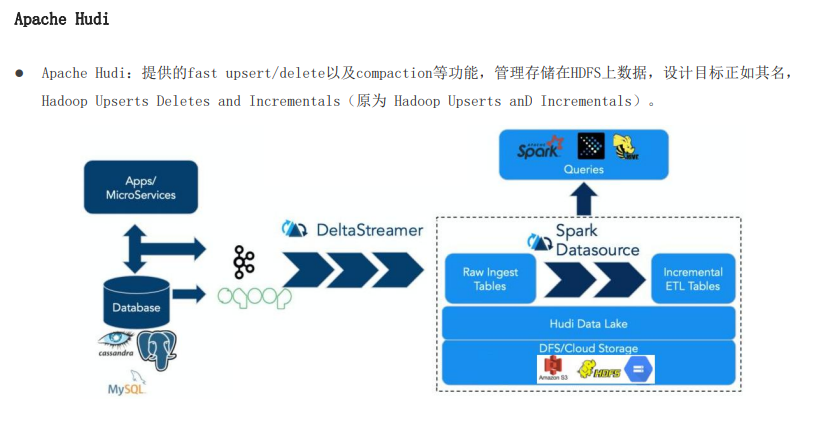
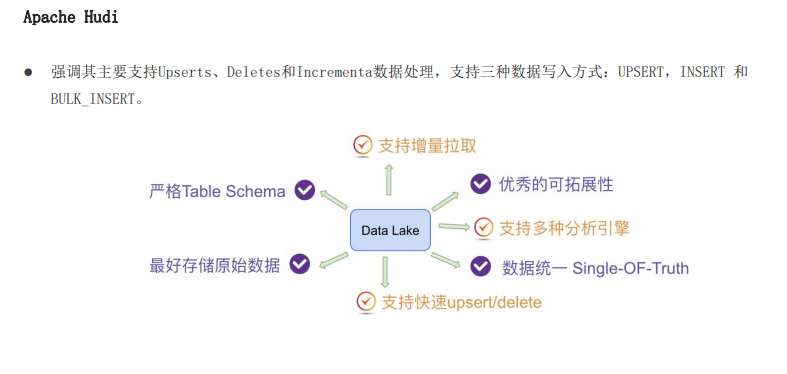
1.4 apache hudi-功能特性
hudi是一种针对分析型业务的、扫描优化的数据存储抽象,它能够是hdfs数据集在分钟级的延时内持续变更,也支持下游系统对这个数据集的增量处理
hudi功能:
1、可以将change logs通过upsert的方式合并进hudi
2、对上可以暴露成一个hive或者spark表,通过api后者命令行可以获取到增量修改的信息,继续供下游消费
3、报关修改历史,可以做世间路行或者回退
4、内部有主键到文件级的索引,默认是记录到文件的布隆过滤器
特性:
提供两种原语,不仅可以批处理,还可以在数据胡上进行流处理
update/delete记录:会记录这些擦欧总,提供写操作的事务保证,查询会处理最新提交的快照,并基于此输出结果
变更流:可从给定的时间点获取表中update/insert/deleted的所有记录的增量流,并解锁新的擦汗寻姿势(根据操作的类别)
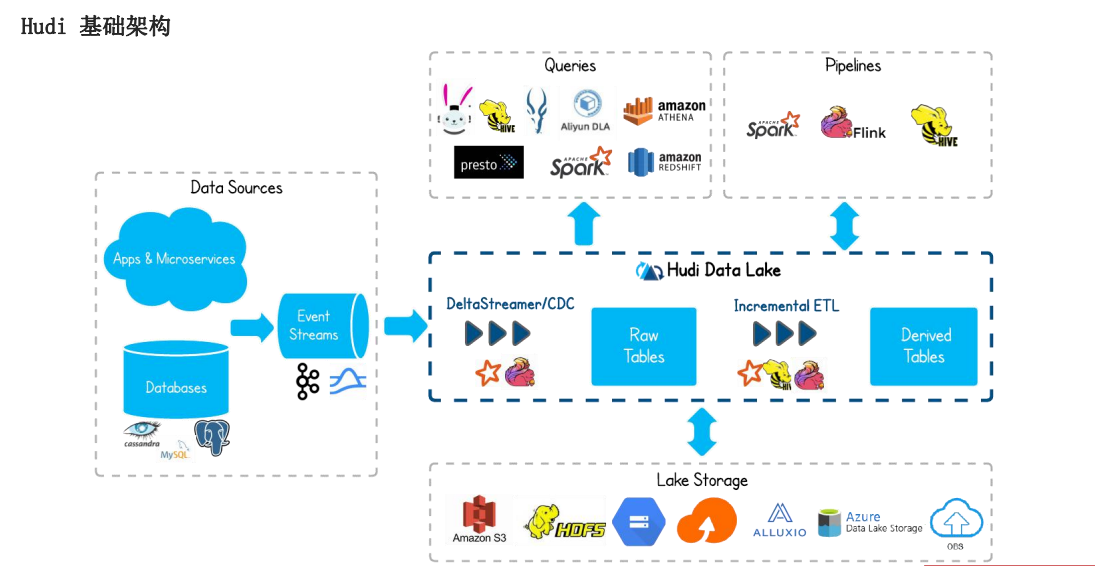
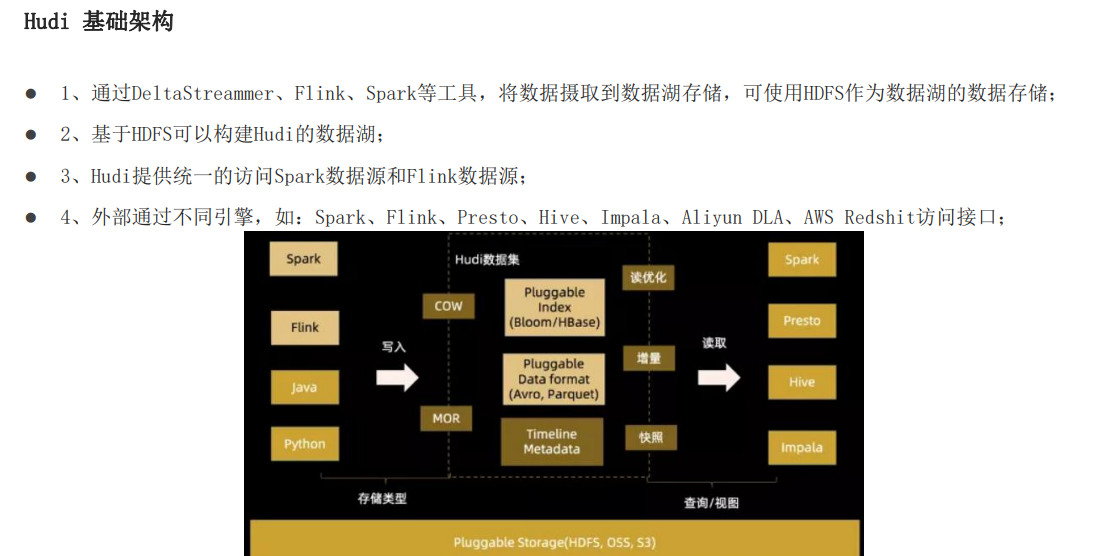
1.5 apache hudi -基础架构
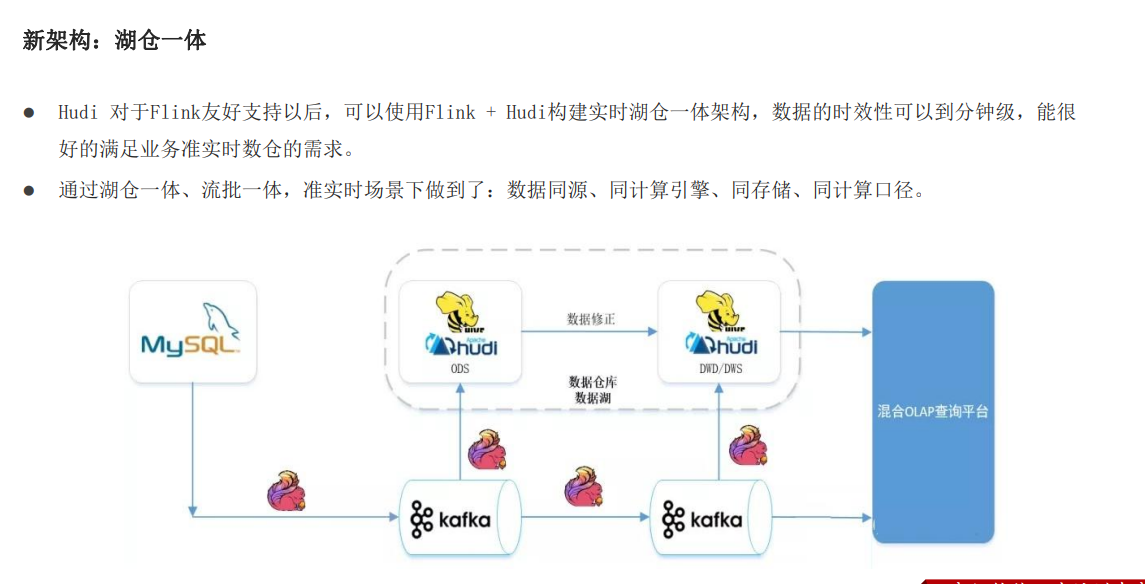
1.6 新架构-湖仓一体
1.6 hudi 快速使用-spark
1.6.1 maven安装
-因为要使用maven编译hudi源码
-在liunx中安装maven,repositort目录为m2
-下载hudi源码
-添加maven镜像
-编译 在/root目录下执行编译命令
mvn clean install -DskipTests -DskipITs -Dscala-2.12 -Dspark3
-编译成功后,有直接编译好的文件
\第1部分、Hudi 基础入门篇\2.资料、软件hudi-0.9.0-build.tar.gz
编译成功后进到hudi-cli 目录 执行hudi-cli 命令,即可打开hudi的客户端
1.6.2 安装hdfs、spark、scala
使用hdfs存储数据、使用spark进行处理数据、spark使用scala语言
所以这三个都是需要的
linux中已经安装好了这三个
1.6.3 spark-shell-hudi
案例说明:
在linux中使用spark-shell命令,以本地模式运行spark,模拟产生乘车交易数据,将其保存到hudi表中,并且从hudi表中加载数据进行查询分析。hudi表数据存储在hdfs中
//1. 开启客户端
./spark-shell --master local[2] --jars /opt/apps/hudi/hudi-jars/hudi-spark3-bundle_2.12-0.9.0.jar,/opt/apps/hudi/hudi-jars/spark-avro_2.12-3.0.1.jar,/opt/apps/hudi/hudi-jars/spark_unused-1.0.0.jar --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"
//2. 导入依赖 定义变量
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_test_1"
val basePath = "hdfs://daohe:8020/datas/hudi-warehouse/hudi_test_1"
val dataGen = new DataGenerator
//3.产生数据
val inserts = convertToStrtingList(dataGen.generateInserts(10))
//4.读取产生的数据
val df = spark.read.json(spark.sparkContext.parallelize(inserts,2))
df.printSchema()
df.select("begin_lat","driver").show(10,truncate=false)
//5.写入hudi
df.write
.mode(Overwrite)
.format("hudi")
.options(getQuickstartWriteConfigs)
.option(PRECOMBINE_FIELD_OPT_KEY,"ts")
.option(RECORDKEY_FIELD_OPT_KEY,"uuid")
.option(PARTITIONPATH_FIELD_OPT_KEY,"partitionpath")
.option(TABLE_NAME,tableName)
.save(basePath)
//6.读取写入到hudi中的数据 路径要指定到具体的文件(parquent文件,或者未合并的日志文件)
//partitionpath=americas/brazil/sao_paulo 所以写入hudi的数据分区具有三层,所以才有 /*/*/*/*
val tripsSnapshotDF = spark.read.format("hudi").load(basePath+"/*/*/*/*")
tripsSnapshotDF.printSchema()
//7.注册为视图 进行spark-sql业务查询
tripsSnapshotDF.createOrReplaceTempView("test1_view")
spark.sql("select _hoodie_commit_time,_hoodie_commit_seqno,_hoodie_partition_path,_hoodie_file_name,driver from test1_view where fare>20.0").show()
/*
只是使用spark-sql将数据以hudi的格式写到了hdfs中,但是hudi帮我们做了很多事
分区分目录、parquent列式存储、还增加了一些数据进入更新的时间记录等
--hudi在写入数据得时候自动加得一些数据,包括写入时间,写入得序列号、唯一主键、partition路径、存储到hdfs中的路径名 每条数据都会有这些记录
hudi中的schema 原数据的schema
|-- _hoodie_commit_time: string
|-- _hoodie_commit_seqno: string
|-- _hoodie_record_key: string
|-- _hoodie_partition_path: string
|-- _hoodie_file_name: string
|-- begin_lat: double |-- begin_lat: double
|-- begin_lon: double |-- begin_lon: double
..... .....
总结:感觉没有使用hudi做什么,还是写spark代码,更多的是直接写sparkSql代码,但是最终写到hdfs中的数据,经过了hudi进行管理,hudi是通过分区表的形式管理数据,加了三级分区、转为列式存储、每条数据都记录了写入时间、写入的路径、数据所在的路径、唯一主键、分区路径、可以根据唯一主键进行更新删除hdfs中的某条数据等。从而是hdfs中的数据,更加方便管理
*/
二、Huid中的基本概念
2.0 hudi数据的文件保存形式
.hoodie 文件 和 分区的数据文件:
1、
.hoodie 文件:由于CRUD的零散性,每一次的操作都会生成一个文件,这些小文件越来越多后,会严重影响HDFS的性能,Hudi设计了一套文件合并机制。 .hoodie文件夹中存放了对应的文件合并操作相关的日志文件。
Hudi把随着时间流逝,对表的一系列CRUD操作叫做Timeline,Timeline中某一次的操作,叫做Instant。
-l- Instant Action,记录本次操作是一次数据提交(COMMITS),还是文件合并(COMPACTION),或者是文件清理(CLEANS);
-2- Instant Time,本次操作发生的时间;
-3- State,操作的状态,发起(REQUESTED),进行中(INFLIGHT),还是已完成(COMPLETED)
2、分区数据文件
其中包含一个metadata元数据文件和数据文件parquet列式存储。
Hudi为了实现数据的CRUD,需要能够唯一标识一条记录,Hudi将把数据集中的唯一字段(record key ) + 数据所在分区 (partitionPath) 联合起来当做数据的唯一键。
2.1、三大基本概念
通过三部分来管理数据:时间轴、文件形式存数据、索引
时间轴 timeline
所有的表中维护了一个包含在不同的即时(Instant)时间对数据集操作(比如新增、修改或删除)的时间轴(Timeline)
每次对hudi表的数据集操作时,都会绑定一个操作的时间,并将这个时间放到时间轴上
-1-可以查询某个时间之前的数据,也可以查询某个时间之后的数据,在hdfs中提高了查询效率
-2-可以查询某次更新之前的数据,(通过时间点,查询更新时间点之前的数据)
-3-如果采用数据中携带的时间作为分区,那么即使是延迟数据也会到相应的分区,比如10:20分进来了一个9点的数据,那么这个数据一方面会进到9点的分区中,另一方面查询commit10点之后的数据,这条数据也会被消费到
文件管理
数据存储在分布式文件系统hdfs中,通过指定的hdfs路径进行存储,以表的名称
--可以指定分区字段 option(PARTITIONPATH_FIELD.key(), "partitionpath")
--在每个分区中,基本文件组成文件组,每个文件有唯一的文件id,每个文件又包含在某个即时时间的提交/压缩生成的基本列文件(.parquet)以及一组日志文件(.log),更新操作会先写到日志中,之后进行合并
--Hudi 的 base file (parquet 文件) 在 footer 的 meta 去记录了 record key 组成的 布隆过滤器,用于在查询中快速定位
索引
Hudi通过索引机制提供高效的Upsert操作(update insert)
-1-该机制会将一个RecordKey+PartitionPath组合的方式
作为唯一标识映射到一个文件ID,而且这个唯一标识和文件组/文件ID之间的映射自记录被写入 文件组开始就不会再改变。
-2-全局索引:在全表的所有分区范围下强制要求键保持唯一,即确保对给定的键有且只有一个对应的记录。
-3-非全局索引:仅在表的某一个分区内强制要求键保持唯一,它依靠写入器为同一个记录的更删提供一致的分区路径。
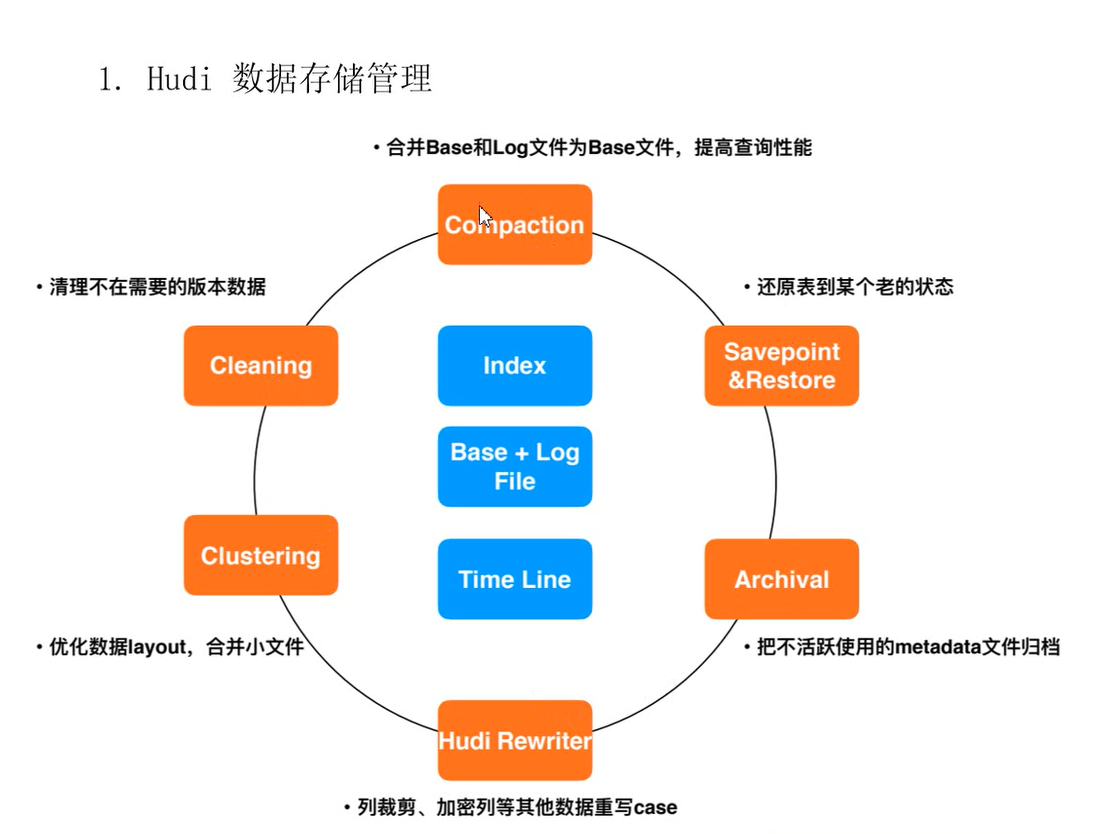
2.2 两种表的类型
COW 表
copy on right
在写入数据的时候,先从上次的数据副本copy一份,然后将拷贝的与最新的做合并,合并后作为最新的数据副本。
支持:快照查询 和 增量查询
优缺点:写入时要进行旧副本的复制,然后合并,所以写入成本高;
但每次都会合并成最新的数据副本,所以读的成本低
适合场景:写少读多。尤其适合一次性写入,多次查询的场景
MOR
merger on read
读取时合并
新插入的数据存储在log 中,定期再将delta log合并进行parquet数据文件。当要读取的时候,会将日志中的数据与基本文件中的数据合并,返回最新的数据。
支持:快照查询 增量查询 读优化查询
优缺点:写入快,但是读取慢,读的时候要进行文件的合并
适合场景:写多读少
2.3 三种数据计算模型
-1-批处理:
延迟高:小时级、天级
数据完整
成本低:固定时间执行,其他时间不执行
-2-流处理:
延迟低,甚至毫秒级别
数据不完整,延迟数据到达,则不会计算
成本高:时刻运行
-3-增量模型
批+流=结合两者的特点,比批更加实时,比流更加经济
Upsert:这个主要是解决批式模型中,数据不能插入、更新的问题,有了这个特性,可以往 Hive 中写入增量数据,而不是每次进行完全的覆盖。
Incremental Query:增量查询,减少计算的原始数据量。只计算增量数据
2.4 三种查询类型
快照查询:
查询完整的数据;
对于cow表-先进性动态数据合并,然后查询基本文件;对于rom表-查询基本文件和日志文件
增量查询:
需要给定一个时间,然后查询这个时间之后的数据
读优化查询:
rom表支持,cow表不支持
只查询基本文件,不查询日志文件,所以如果有些数据还没有进行合并,则是查询不到的
两种表对应的三种查询结果:
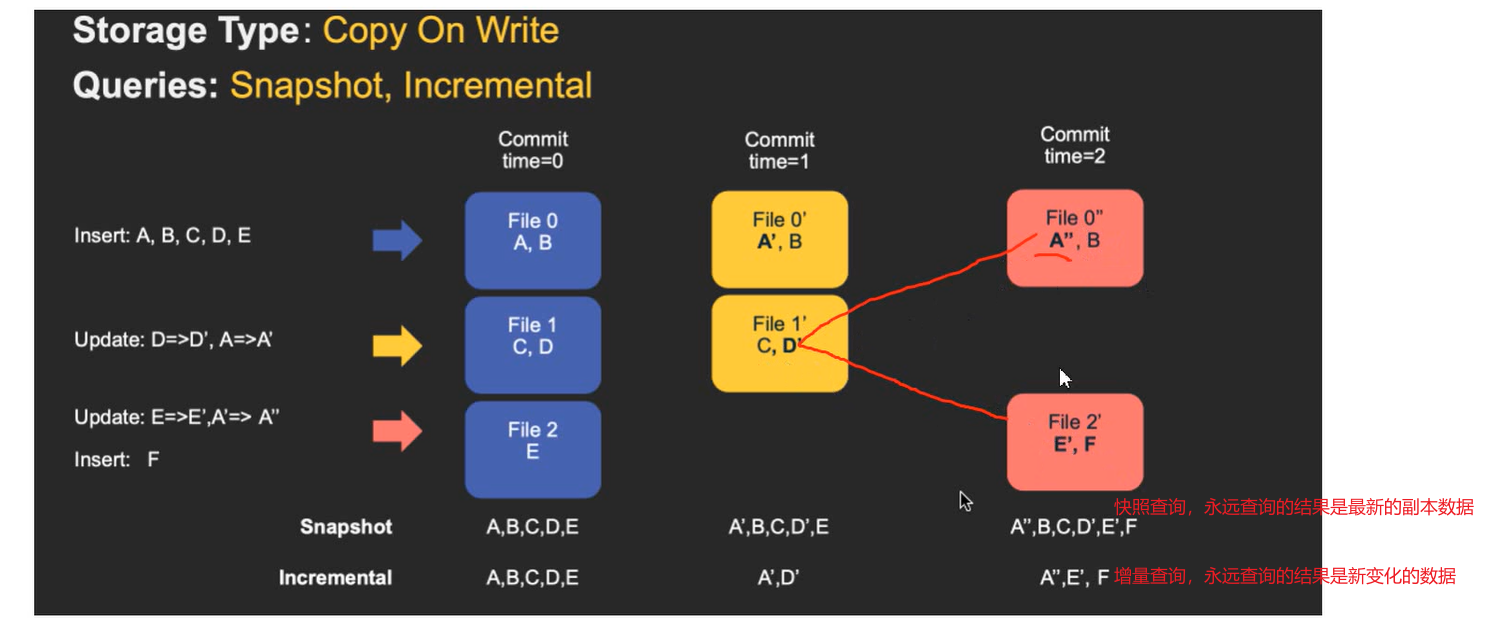

2.5 COW 与ROM 表的异同

2.6 数据写操作的流程
在Hudi数据湖框架中支持三种方式写入数据:UPSERT(插入更新)、INSERT(插入)和BULK INSERT(写排序)
在写入hudi的时候可通过参数:write.option 来进行选择不同的模式
2.6.1 upset操作


2.6.2 insert操作
对于COW表:
-1- 去重,如果这批数据中有重复的,则至写入一次
-2- 不会创建索引
-3- 如果有小的基本文件,则直接合并进去,如果没有可用的基本文件,则会创建基本文件
对于ROM表:
-1- 去重
-2- 不会创建索引
-3- 如果能找到对应的日志,并且有小的基本文件,则尝试追加到日志文件中,或者写到最新的日志文件中;如果找不到日志文件,则会创建新的基本文件写进去
2.6.3 bulk_insert
用于快速导入快照数据到hudi。 相当于直接将数据批量写道hudi中。
基本特性
bulk_insert可以减少数据序列化以及合并操作,于此同时,该数据写入方式会跳过数据去重,所以用户需要保证数据的唯一性。
bulk_insert在批量写入模式中是更加有效率的。默认情况下,批量执行模式按照分区路径对输入记录进行排序,并将这些记录写入Hudi,该方式可以避免频繁切换文件句柄导致的写性能下降。
三、Hudi----spark
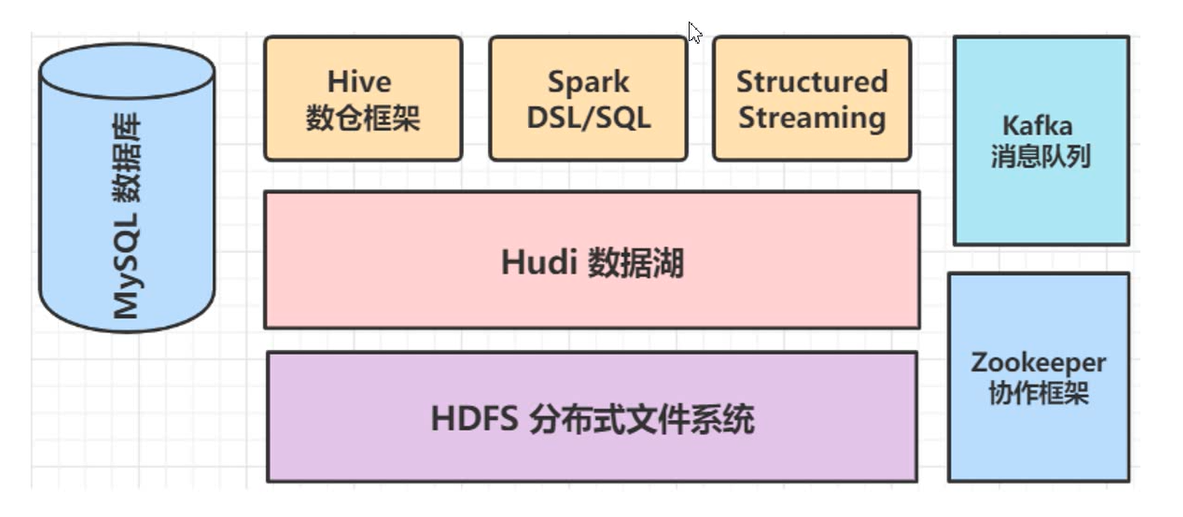
3.0 spark实现hudi的CRUD
创建maven项目:
--maven中导入依赖
--将/opt/apps/hadoop-3.1.1/etc/hadoop 下的配置文件core-site.xml 和 hdfs-site.xml放到项目中的resource目录中,或者在工程中导入相应依赖。因为hudi数据是存储在hdfs中
--使用scala语言编写spark代码 进行对hdfs中的数据进行增删改查
整体来讲:通过hudi管理了hdfs中的数据,采用hudi的方式写到hdfs中,会自动创建分区、转为parquet列式存储,并且记录每条数据的提交时间、提交序列、分区路径等
然后可以对hdfs中的数据进行增删改查功能,并且可以根据数据写入时间等其他的索引来进行增删改查。
而在此之前,是没办法保证对hdfs中的数据进行精确的增删改查的。
案例:
package com.wwt.hudi.spark
import org.apache.hudi.QuickstartUtils.DataGenerator
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import scala.collection.JavaConverters.asScalaBufferConverter
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConverters._
/*
Author: Tao.W
D a te: 2022/4/25
Description:
* Hudi 数据湖框架,基于Spark计算引擎,对数据进行CRUD操作,使用官方模拟生成出租车出行数据
* 任务一:模拟数据,插入Hudi表,采用COW模式
* 任务二:快照方式查询(Snapshot Query)数据,采用DSL方式
* 任务三:更新(Update)数据
* 任务四:增量查询(Incremental Query)数据,采用SQL方式
* 任务五:删除(Delete)数据
*/
object HudiSparkDemo {
def main(args: Array[String]): Unit = {
// 创建SparkSession实例对象,设置属性
val spark: SparkSession = {
SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")//开启两个线程以本地启动
// 设置序列化方式:Kryo
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
}
spark.sparkContext.setLogLevel("ERROR")
val tableName = "tbl_trips_cow2"
val tablePath = "/data/hudi-warehouse/hudi_trips_cow2"
//任务1:模拟数据 插入hudi表 采用 cow模式
// insertData(spark,tableName,tablePath)
// 任务二:快照方式查询(Snapshot Query)数据,采用DSL方式
//queryData(spark, tablePath)
//queryDataByTime(spark, tablePath)
// 任务三:更新(Update)数据,第1步、模拟产生数据,第2步、模拟产生数据,针对第1步数据字段值更新,第3步、将数据更新到Hudi表中
val dataGen: DataGenerator = new DataGenerator()
// insertData(spark, tableName, tablePath,dataGen)
//println("插入数据结束-----------------开始使用相同的datagen更新数据采用追加的方式")
//updateData(spark, tableName, tableName, dataGen)
// 任务四:增量查询(Incremental Query)数据,采用SQL方式
// incrementalQueryData(spark, tablePath)
// 任务五:删除(Delete)数据
deleteData(spark, tableName, tablePath)
//应用结束,关闭资源
spark.stop()
}
}
插入:
/**
* 插入:模拟产生数据,插入Hudi表,表的类型COW
*/
def insertData(spark: SparkSession, table: String, path: String): Unit = {
import spark.implicits._
//[1] 模拟乘车数据
import org.apache.hudi.QuickstartUtils._
val dataGen: DataGenerator = new DataGenerator()
val inserts = convertToStringList(dataGen.generateInserts(100))
import scala.collection.JavaConverters._
val insertDF: DataFrame = spark.read.json(
spark.sparkContext.parallelize(inserts.asScala, 2).toDS()
)
//[2] 插入数据到Hudi表
insertDF.write
.mode(SaveMode.Append) //Append, Overwrite, ErrorIfExists, Ignore有这四种写入模式,解释在源码中有注解
.format("hudi") //spark直接支持hudi模式的写入
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi 表的属性值设置
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), table)
.save(path)
}
查询
/**
* 查询:采用Snapshot Query快照方式查询表的数据
*/
def queryData(spark: SparkSession, path: String): Unit = {
import spark.implicits._
//将数据从hudi表中读出来 就是这么简单
val tripsDF: DataFrame = spark.read.format("hudi").load(path)
// 从查出的结果中查询费用大于20,小于50的乘车数据 df语句就是这种类sql语句
tripsDF
.filter($"fare" >= 20 && $"fare" <= 50)
.select($"driver", $"rider", $"fare", $"begin_lat", $"begin_lon", $"partitionpath", $"_hoodie_commit_time")
.orderBy($"fare".desc, $"_hoodie_commit_time".desc)
.show(50, truncate = false)
}
def queryDataByTime(spark: SparkSession, path: String): Unit = {
import org.apache.spark.sql.functions._
// 方式一:指定字符串,时间格式 yyyyMMddHHssmm
val df1 = spark.read
.format("hudi")
.option("as.of.instant", "20220425215801") //年月日时分秒 按照数据的提交时间进行过滤,过滤出这个提交时间之前的数据
.load(path)
.sort(col("_hoodie_commit_time").desc) //按提交时间降序排列
// df1.printSchema()
// df1.show(numRows = 5, truncate = false)
df1.show()
println("*************************************************")
// 方式二:指定字符串 时间格式 yyyy-MM-dd HH:ss:mm
val df2 = spark.read
.format("hudi")
.option("as.of.instant", "2023-04-25 21:58:08") //两种日期格式 这种和上面那种
.load(path)
.sort(col("_hoodie_commit_time").desc)
// df2.printSchema()
df2.show(numRows = 5, truncate = false)
}
增量查询
/**
* 增量查询:根据提交时间,设置增量查询的开始时间 设置查询模式为增量查询 ,,查出的数据是开始时间之后的增量数据
*/
def incrementalQueryData(spark: SparkSession, path: String): Unit = {
import spark.implicits._
// 第1步、加载Hudi表数据,获取commit time时间,作为增量查询数据阈值
import org.apache.hudi.DataSourceReadOptions._
spark.read
.format("hudi")
.load(path)
.createOrReplaceTempView("view_temp_hudi_trips") //注册成临时表
val commits: Array[String] = spark
.sql(
"""
|select
| distinct(_hoodie_commit_time) as commitTime
|from
| view_temp_hudi_trips
|order by
| commitTime DESC
|""".stripMargin
)
.map(row => row.getString(0))
.take(50)
val beginTime = commits(commits.length - 1) // commit time we are interested in
println(s"beginTime = ${beginTime}")
// 第2步、设置Hudi数据CommitTime时间阈值,进行增量数据查询
val tripsIncrementalDF = spark.read
.format("hudi")
// 设置查询数据模式为:incremental,增量读取
.option(QUERY_TYPE.key(), QUERY_TYPE_INCREMENTAL_OPT_VAL)
// 设置增量读取数据时开始时间
.option(BEGIN_INSTANTTIME.key(), beginTime)
.load(path)
// 第3步、将增量查询数据注册为临时视图,查询费用大于20数据
tripsIncrementalDF.createOrReplaceTempView("hudi_trips_incremental")
spark
.sql(
"""
|select
| `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts
|from
| hudi_trips_incremental
|where
| fare > 20.0
|""".stripMargin
)
.show(10, truncate = false)
}
更新
/**
* 更新:模拟产生Hudi表中更新数据,将其更新到Hudi表中
* 将相同的数据进行写入:SaveMode.Overwrite 覆盖 或者 SaveMode.Append 追加
*/
def insertData(spark: SparkSession, table: String, path: String, dataGen: DataGenerator): Unit = {
import spark.implicits._
//方式一:覆盖
import org.apache.hudi.QuickstartUtils._
val inserts = convertToStringList(dataGen.generateInserts(100))
import scala.collection.JavaConverters._
val insertDF: DataFrame = spark.read.json(
spark.sparkContext.parallelize(inserts.asScala, 2).toDS()
)
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
insertDF.write
.mode(SaveMode.Overwrite)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi 表的属性值设置
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), table)
.save(path)
}
//方式二 追加
def updateData(spark: SparkSession, table: String, path: String, dataGen: DataGenerator): Unit = {
import spark.implicits._
import org.apache.hudi.QuickstartUtils._
val updates = convertToStringList(dataGen.generateUpdates(100))
import scala.collection.JavaConverters._
val updateDF: DataFrame = spark.read.json(
spark.sparkContext.parallelize(updates.asScala, 2).toDS()
)
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
updateDF.write
.mode(SaveMode.Append)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi 表的属性值设置
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), table)
.save(path)
}
删除
/**
* 删除:删除Hudi表数据,依据主键UUID进行删除,如果是分区表,指定分区路径
* 产生两条一样的数据 写到hudi表中,但写入的时候设置操作模式为 delete
* 从hudi表中加载两条数据,然后将这两条数据以delete的方式 写到hudi表中--从而实现删除
*
*/
def deleteData(spark: SparkSession, table: String, path: String): Unit = {
import spark.implicits._
// 第1步、加载Hudi表数据,获取条目数
val tripsDF: DataFrame = spark.read.format("hudi").load(path)
println(s"Raw Count = ${tripsDF.count()}")
// 第2步、模拟要删除的数据,从Hudi中加载数据,获取几条数据,转换为要删除数据集合
val dataframe = tripsDF.limit(2).select($"uuid", $"partitionpath")
val dataGenerator = new DataGenerator()
val deletes = dataGenerator.generateDeletes(dataframe.collectAsList())
import scala.collection.JavaConverters._
val deleteDF = spark.read.json(spark.sparkContext.parallelize(deletes.asScala, 2))
// 第3步、保存数据到Hudi表中,设置操作类型:DELETE
deleteDF.write
.mode(SaveMode.Append)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// 设置数据操作类型为delete,默认值为upsert
.option(OPERATION.key(), "delete") //设置操作模式为delete
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), table)
.save(path)
// 第4步、再次加载Hudi表数据,统计条目数,查看是否减少2条数据
val hudiDF: DataFrame = spark.read.format("hudi").load(path)
println(s"Delete After Count = ${hudiDF.count()}")
}
案例
滴滴运营数据分析:
业务需求说明
开发工具类
数据ETL保存
指标查询分析
集成hive查询
3.1、示例:滴滴运营数据
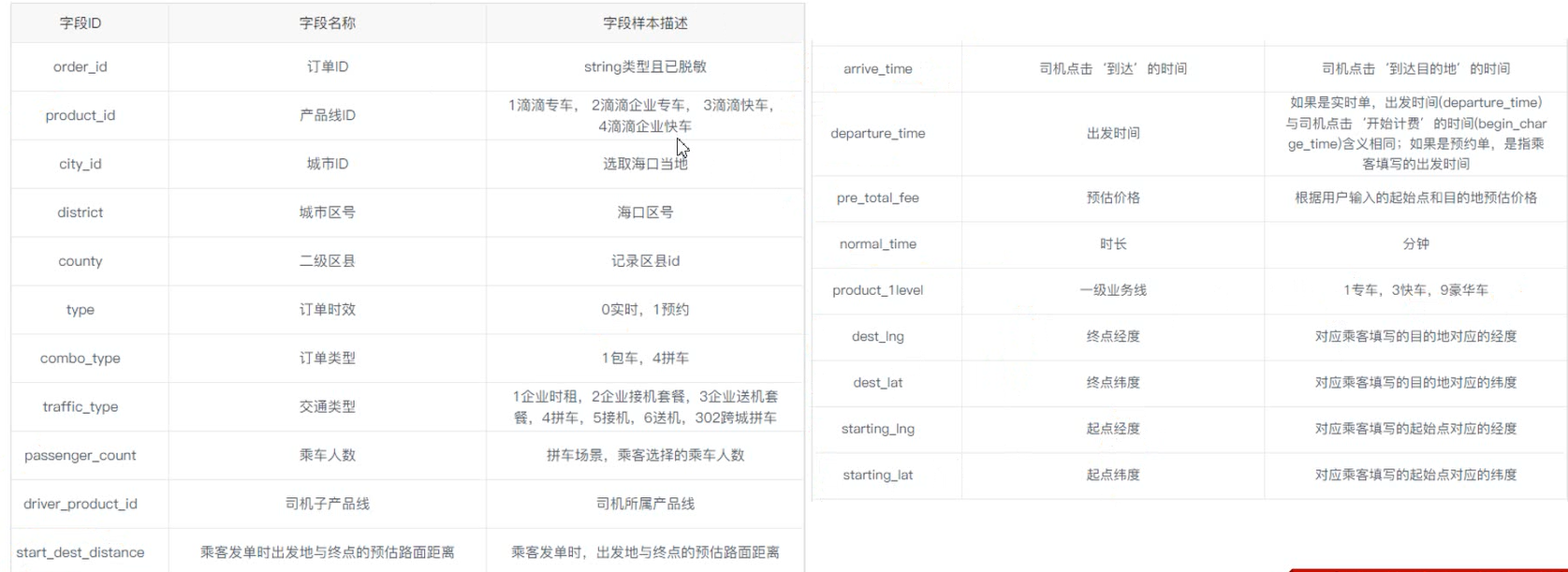
需要做的业务分析:

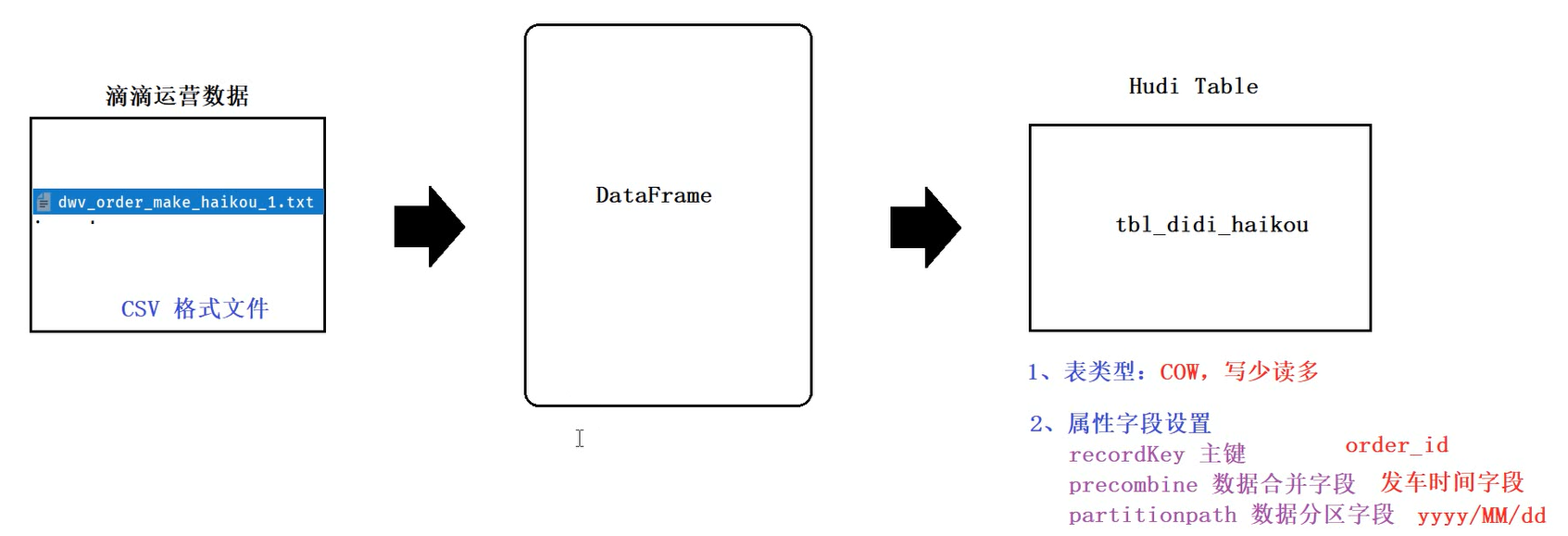
3.1.1 创建项目
-1-在hudi-wwt项目中创建新model:hudi-spark
-2-将hadoop中的conf目录下的 core-site.xml 与 hdfs-site.xml 配置文件放到resources目录中
-3-在idea中连接linux虚拟机,以及连接hive、mysql 都可以的
3.3.2 读取文件 写入hudi
/*使用sparkSql操作数据,先读取csv文件,然后将其保存到hudi表中
-1- 构建sparkSession对象
-2-加载本地csv文件
-3-数据进行ETL处理
-4-保存数据到hudi表中
保存到hudi表的数据:需要设置表的主键、合并字段、分区字段、表的hdfs存储路径
根据主键建索引,根据合并字段进行自动小文件合并,根据分区字段进行分区
由于将hadoop的核心配置文件放到了idea中,所以可以将数据存到hdfs中
-5-批量写入,关闭资源
**/
//-1-
def readCSVFile(spark: SparkSession, datasPath: String): DataFrame = {
spark.read
.option("sep","\\t") //设置分隔符
.option("header","true")//首行为表的列名
.option("inferSchema","true")//自动推断字段类型
.csv(datasPath)
}
//-2-
def processData(didiDF: DataFrame): DataFrame = {
didiDF
//添加字段 将年月日合并到一起用‘/’分割作为三级分区字段 用‘-’分割则为一级分区目录
.withColumn("partitionPath",concat_ws("-",col("year"),col("month"),col("day")))
.drop("year","month","day")
//将发车时间作为 数据的合并字段 司机同一个发车时间点只能有一个订单
.withColumn("ts",unix_timestamp(col("departure_time"),"yyyy-MM-dd HH:mm:ss"))
}
//-3-
def saveToHudi(etlDF: DataFrame, hudiTableName: String, hudiTablePath: String) = {
import org.apache.hudi.config.HoodieWriteConfig._
etlDF
.write
.mode(SaveMode.Overwrite)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi 表的属性值设置
.option(RECORDKEY_FIELD.key(), "order_id") //表的主键
.option(PRECOMBINE_FIELD.key(), "ts") //合并字段
.option(PARTITIONPATH_FIELD.key(), "partitionPath") //分区字段
.option(TBL_NAME.key(), hudiTableName) //hudi表名
.save(hudiTablePath) //数据存储的路径
}
3.3.3 读取hudi 进行指标统计
对应代码:E:\work2\hudi-wwt\hudi-spark\src\main\scala\cn\hudi\DidiAnalysisSpark
包含一些自定义函数 和常用函数 可以写一写
package com.didi
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.functions._
import org.apache.spark.sql.{DataFrame, Row, SparkSession, functions}
import org.apache.spark.storage.StorageLevel
import java.util.{Calendar, Date}
/*
Author: Tao.W
D a te: 2022/5/2
Description: 加载hudi表中的数据 进行业务分析
*/
object DidiAnalysisSpark {
val hudiTablePath: String = "/hudi-warehouse/tbl_didi_haikou"
def main(args: Array[String]): Unit = {
val spark = SparkUtils.createSparkSession(this.getClass, partitions = 8)
//加载hudi表中的数据
val hudiDF: DataFrame = readFromHudi(spark, hudiTablePath)
hudiDF.show(100, truncate = false)
//由于数据呗一次读取,多次使用,所以建议使用缓存
hudiDF.persist(StorageLevel.MEMORY_AND_DISK)
//指标一:订单类型统计
reportProduct(hudiDF)
// //指标二:订单时效类型分析
// reportType(hudiDF)
//指标三:交通类型分析
// reportTraffic(hudiDF)
//指标四:订单价格区间分析
// reportPrice(hudiDF)
//指标五:订单距离区间分析
// reportDistance(hudiDF)
//指标六:订单日期分析
// reportWeek(hudiDF)
hudiDF.unpersist() //释放缓存
spark.stop()
}
//订单类型分析:product_id
def reportProduct(hudiDF: DataFrame) = {
//按照product_id聚合即可
val reportDF: DataFrame = hudiDF.groupBy("product_id").count() //count是求行数
reportDF.show()
//自定义udf函数,转换名称
val to_name: UserDefinedFunction = udf(
(productId: Int) => {
productId match {
case 1 => "滴滴专车"
case 2 => "滴滴企业专车"
case 3 => "滴滴快车"
case 4 => "滴滴企业快车"
}
}
)
val resDF = reportDF.select(
to_name(col("product_id")).as("order_type")
, col("count").as("product_total")
)
resDF.printSchema()
resDF.show(20, truncate = false)
}
def reportType(hudiDF: DataFrame) = {
val reportDF = hudiDF.groupBy("type").count()
val to_name = udf(
(ordertype: Int) => {
ordertype match {
case 0 => "实时单"
case 1 => "预约单"
}
}
)
val resDF = reportDF.select(
to_name(col("type")).as("order_type")
, col("count").as("orderType_total")
)
resDF.printSchema()
resDF.show(10, truncate = false)
}
def reportTraffic(hudiDF: DataFrame) = {
val reportDF = hudiDF.groupBy("traffic_type").count()
val to_name = udf(
(traffic_type: Int) => {
traffic_type match {
case 0 => "普通散客"
case 1 => "企业时租"
case 2 => "企业接机套餐"
case 3 => "企业送机套餐"
case 4 => "拼车"
case 5 => "接机"
case 6 => "送机"
case 302 => "跨城拼车"
case _ => "未知"
}
}
)
val resDF = reportDF.select(
to_name(col("traffic_type"))
, col("count").as("traffic_type_total")
)
resDF.printSchema()
resDF.show(10, truncate = false)
}
//订单价格区间统计
def reportPrice(hudiDF: DataFrame) = {
import org.apache.spark.sql.functions._
val resDF = hudiDF.agg(
sum(
when(col("pre_total_fee").between(0, 15), 1).otherwise(0)
).as("0-15"),
sum(
when(col("pre_total_fee").between(16, 30), 1).otherwise(0)
).as("16-30"),
sum(
when(col("pre_total_fee").between(31, 50), 1).otherwise(0)
).as("31-50"),
sum(
when(col("pre_total_fee").between(51, 100), 1).otherwise(0)
).as("51-100"),
sum(
when(col("pre_total_fee").gt(101), 1).otherwise(0)
).as("100+")
)
resDF.printSchema()
resDF.show(10, truncate = false)
}
def reportDistance(hudiDF: DataFrame) = {
val resDF = hudiDF.agg(
sum(
when(col("start_dest_distance").between(0, 10000), 1).otherwise(0)
).as("0-10km"),
sum(
when(col("start_dest_distance").between(10001, 20000), 1).otherwise(0)
).as("10-20km"),
sum(
when(col("start_dest_distance").between(20001, 30000), 1).otherwise(0)
).as("20-30km"),
sum(
when(col("start_dest_distance").between(30001, 50000), 1).otherwise(0)
).as("30-50km"),
sum(
when(col("start_dest_distance").gt(50001), 1).otherwise(0)
).as("50km+")
)
resDF.printSchema()
resDF.show(10, truncate = false)
}
//统计周一到周日的每日订单数量
def reportWeek(hudiDF: DataFrame) = {
//自定义udf函数,将日期转为星期
val to_week: UserDefinedFunction = udf(
(dateStr: String) => {
val format: FastDateFormat = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss")
val calendar: Calendar = Calendar.getInstance();
val date: Date = format.parse(dateStr)
calendar.setTime(date)
val dayWeek = calendar.get(Calendar.DAY_OF_WEEK) match {
case 1 => "星期日"
case 2 => "星期一"
case 3 => "星期二"
case 4 => "星期三"
case 5 => "星期四"
case 6 => "星期五"
case 7 => "星期六"
}
// 返回星期即可
dayWeek
}
)
val resDF = hudiDF
.select(to_week(col("departure_time")).as("week"))
.groupBy("week")
.count()
.select(col("week"), col("count").as("total"))
resDF.printSchema()
resDF.show(10, truncate = false)
}
def readFromHudi(spark: SparkSession, hudiTablePath: String): DataFrame = {
val didiDF: DataFrame = spark.read.format("hudi").load(hudiTablePath)
// 选择需要的字段
didiDF.select("product_id",
"type",
"traffic_type",
"pre_total_fee",
"start_dest_distance",
"departure_time")
}
}
3.2 结构化数据流式写入hudi
3.2.1 流程说明
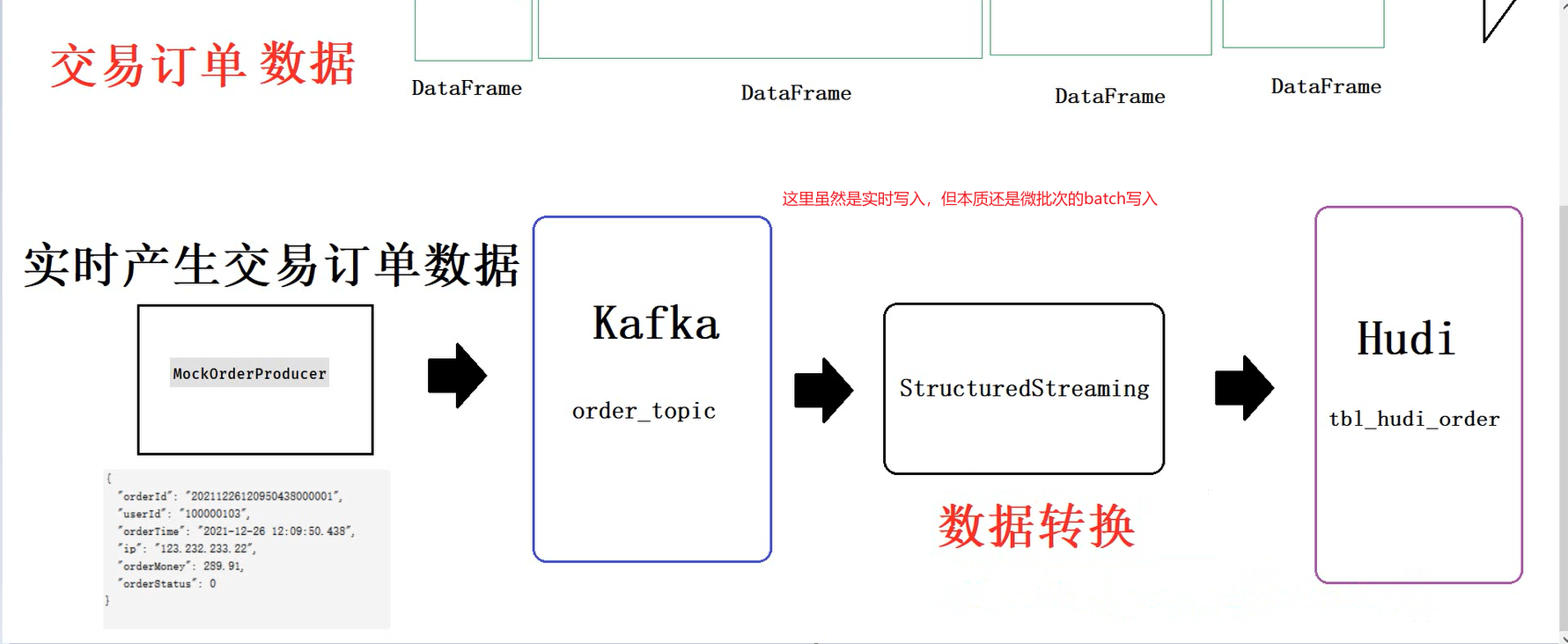
模拟数据-->实时写入kafka-->使用sparkStream实时从kafka中不断的读数据-->对数据进行处理-->以微批次的形式不断的将数据写入hudi
3.2.2 代码开发
object HudiStructureDemo {
//从kafka中消费数据
def readFromKafka(spark: SparkSession, topicName: String): DataFrame = {
spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "linux01:9092,linux02:9092,linux03:9092")
.option("subscribe", topicName)
.option("startingOffsets", "latest")
.option("maxOffsetsPerTrigger", 100000)
.option("failOnDataLoss", "false")
.load()
}
//对数据进行ETL
def proces(kafkaStreamDF: DataFrame): DataFrame = {
kafkaStreamDF
//选择kafka中读过来的字段
.selectExpr(
"CAST(key as STRING) order_id",
"CAST(value as STRING) as message",
"topic","partition","offset","timestamp"
)
//解析message数据
.withColumn("user_id",get_json_object(col("message"),"$.userId"))
.withColumn("order_time",get_json_object(col("message"),"$.orderTime"))
.withColumn("ip",get_json_object(col("message"),"$.ip"))
.withColumn("order_money",get_json_object(col("message"),"$.orderMoney"))
.withColumn("order_status",get_json_object(col("message"),"$.orderStatus"))
//删除message字段
.drop(col("message"))
//转换订单日期时间格式为long类型,转为hudi表的合并字段
.withColumn("ts",to_timestamp(col("order_time"),"yyyy-MM-dd HH:mm:ss.SSS"))
//订单日期时间提取作为hudi分区字段:yyyy-MM-dd
.withColumn("day",substring(col("order_time"),0,10))
}
//流式写入hudi
def saveToHudi(streamDF: DataFrame) = {
//流式写入hudi 使用流式写入,写入的时候是微批次写入 每一批次都是一次写入hudi
streamDF.writeStream
.outputMode(OutputMode.Append())
.queryName("query-hudi-streaming")
.foreachBatch((batchDF:Dataset[Row],batchId:Long)=>{
println(s"============BatchId:${batchId} start=========")
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.keygen.constant.KeyGeneratorOptions._
//每一批次都是这样写入
batchDF.write
.mode(SaveMode.Append)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi 表的属性值设置
.option(RECORDKEY_FIELD.key(), "order_id")
.option(PRECOMBINE_FIELD.key(), "ts")
.option(PARTITIONPATH_FIELD.key(), "day")
.option(TBL_NAME.key(), "tbl_hudi_order")
.option(TABLE_TYPE.key(), "MERGE_ON_READ")//设置hudi表模式为MOR
// 分区值对应目录格式,与Hive分区策略一致 day=2021-01-01
.option(HIVE_STYLE_PARTITIONING_ENABLE.key(), "true")
.save("/hudi-warehouse/tbl_hudi_order")
})
//设置检查点,方便程序出错时数据恢复
.option("checkpointLocation", "/datas/hudi-spark/struct-ckpt-1001")
.start()
}
def main(args: Array[String]): Unit = {
//-1- 构建sparkSession对象
val spark = SparkUtils.createSparkSession(this.getClass)
//-2-从kafka中实时消费数据
val kafkaStreamDF:DataFrame=readFromKafka(spark,"order-topic")
//-3-提取数据,转换数据类型,数据ETL
val streamDF:DataFrame = proces(kafkaStreamDF)
//-4-保存数据到hudi表中,MOR表类型
saveToHudi(streamDF)
//-5-流式应用启动后等待终止
spark.streams.active.foreach(query=>println(s"Query:${query.name} is Running................"))
spark.streams.awaitAnyTermination()
}
}
3.3 hudi—spark_Sql
hudi0.9版本才开始支持,并且对spark的版本有一定要求,尽量是3.1版本之后的
结合spark_Sql,说白了,就是可以通过spark-sql直接操作hudi表数据,包括DDL与DDM语句
---1-指定hudi的jar包开启spark-sql命令行
..bin/spark-sql --master local[2] --jars /root/hudi-jars/hudi-spark3-bundle_2.12-0.9.0.jar /root/hudi-jars/spark-avro_2.12-3.0.1.jar --conf 'spark.serialozer=org.apache.spark.serializer.KryoSerializer' --conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
hudi默认增删改的并行度为1500,这里在运行的时候修改并行度为1
set hoodie.upset.shuffle.parallelism =1;
set hoodie.insert.shuffle.parallelism =1;
set hoodie.delete.shuffle.parallelism =1;
设置不同步hudi表元数据
set hoodie.datasource.meta.sync.enable =false;
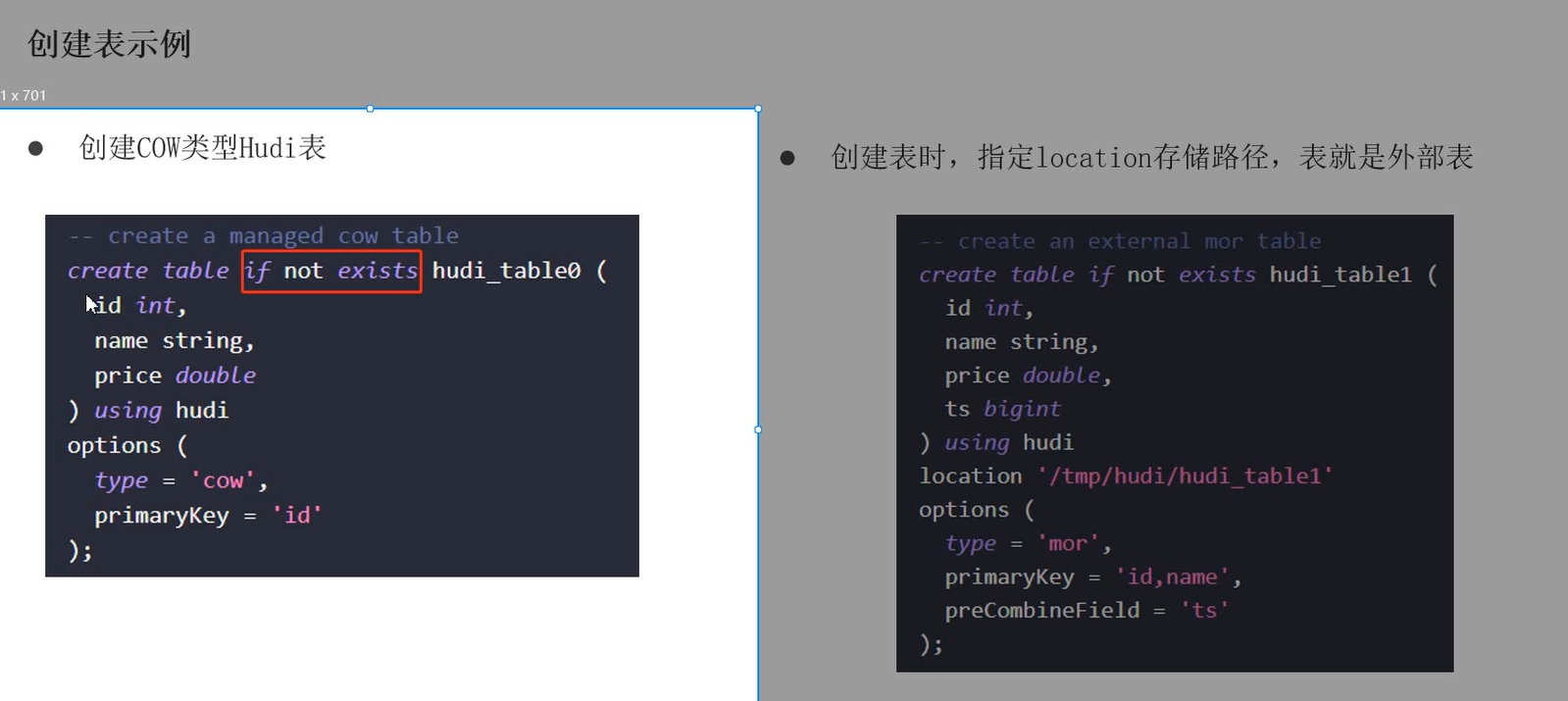
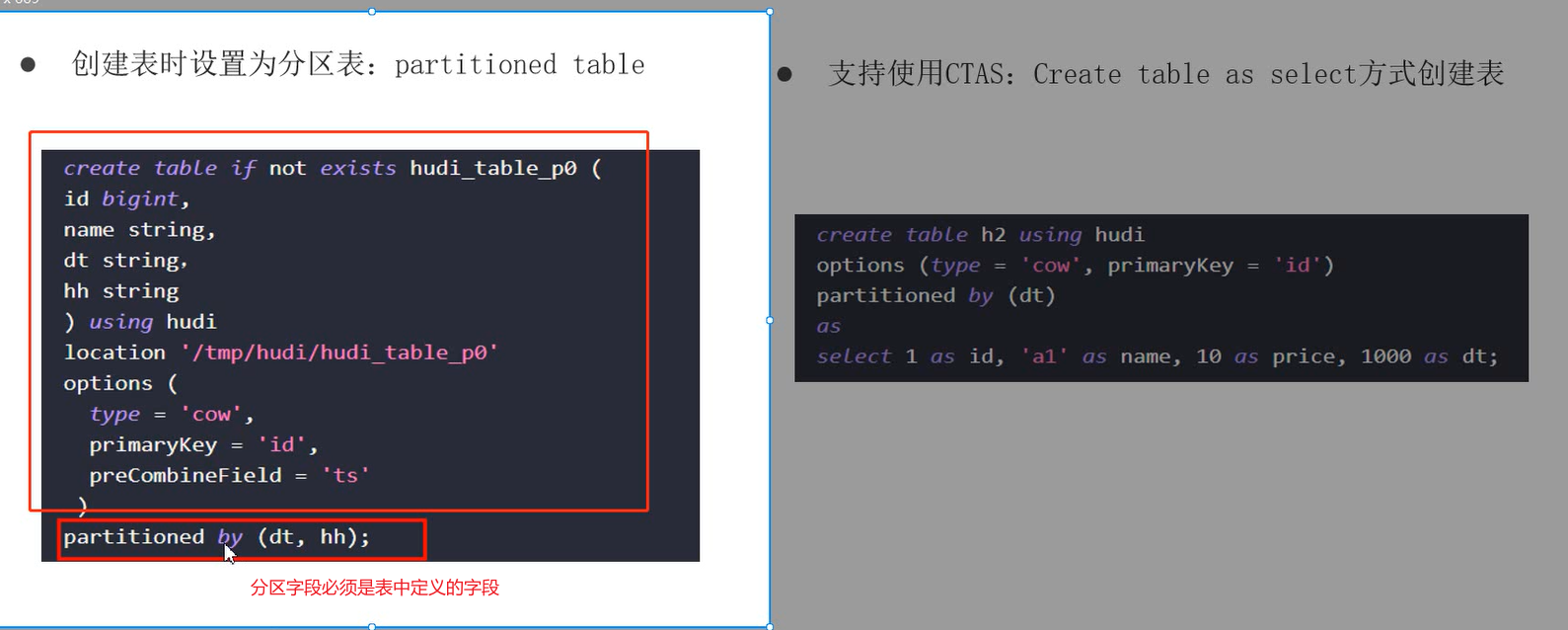
使用spark-sql命令行创建hudi表:
create table test_hudi_table2(
id int,
name string,
price double,
ts long,
dt string
)using hudi --注意创建hudi表
partitioned by (dt) --设置分区字段,该字段必须是表中定义的字段
options(primaryKey='id',type='mor',preCombineField='ts')--设置主键、表类型、合并字段
location 'hdfs://linux01:8020/hudi-warehouse/test_hudi_table2' --指定全路径
--向表中插入数据
insert into default.test_hudi_table2 select 1 as id,'hudi' as name,10 as price,1000 as ts,'2021-01-01' as dt;
-- 查询数据:
select * from test_hudi;
可以增删改查
四、Hudi—Hive
很简单-就是一个jar包
将/root/hudi-0.9.0/packaging/hudi-hadoop-mr-bundle/target下的hudi-hadoop-mr-bundle-0.9.0.jar拷贝到$HIVE_HOME/lib下
然后再hive中创建一个外部表,将其映射到hudi表;然后给外部表手动添加分区,这样就可以了。
就完成了 hive表与hudi表的映射,可以直接在hive中进行数据的分析操作了。
//注意表的输入输出要使用hudi的format,然后路径指到hudi表的路径,这样一来,这个表的数据在hudi中是一个表,在hive中也对应这一个表,而这两个表的数据都对应着hdfs中的同一份数据。也就是完成了hudi表与hive表的映射
//案例:
//在hive中建表
create external table if not exists tbl_hudi_didi(
order_id bigint ,
product_id int ,
city_id int ,
district int ,
county int ,
type int ,
combo_type int ,
traffic_type int ,
passenger_count int ,
driver_product_id int ,
start_dest_distance int ,
arrive_time string ,
departure_time string ,
pre_total_fee double ,
normal_time string ,
bubble_trace_id string ,
product_1level int ,
dest_lng double ,
dest_lat double ,
starting_lng double ,
starting_lat double ,
partitionpath string ,
ts bigint
)
PARTITIONED BY (data_str string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION '/hudi-warehouse/tbl_didi_haikou' ;
//注意输入输出要使用hudi的format,然后路径指到hudi表的路径,这样依赖,这个表的数据在hudi中是一个表,在hive中也对应这一个表,而这两个表的数据都对应着hdfs中的同一份数据。也就是完成了hudi表与hive表的映射
//手动添加分区:
ALTER TABLE hudi_hivedb.tb1_hudi_didi ADD IF NOT EXISTS PARTITION (data_str='2017-5-22') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-22' ;
ALTER TABLE hudi_hivedb.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (data_str='2017-5-23') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-23' ;
ALTER TABLE hudi_hivedb.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (data_str='2017-5-24') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-24' ;
//查询数据
select * from tbl_hudi_didi where data_str='2017-5-22' limit 10;
// 开始统计指标
set hive.exec.mode.local.auto=true; --设置为本地运行
// 指标一:订单类型统计
WITH tmp AS (
SELECT product_id, COUNT(1) AS total FROM hudi_hivedb.tbl_hudi_didi GROUP BY product_id
)
SELECT
CASE product_id
WHEN 1 THEN "滴滴专车"
WHEN 2 THEN "滴滴企业专车"
WHEN 3 THEN "滴滴快车"
WHEN 4 THEN "滴滴企业快车"
END AS order_type,
total
FROM tmp ;
五、Hudi支持的MergeInto语法
可以针对主键相关的条件,进行增删改查操作,而且是对hudi表进行操作,
比如插入的数据若主键不存在则插入,存在则更新,存在并且满足其他字段条件则删除…
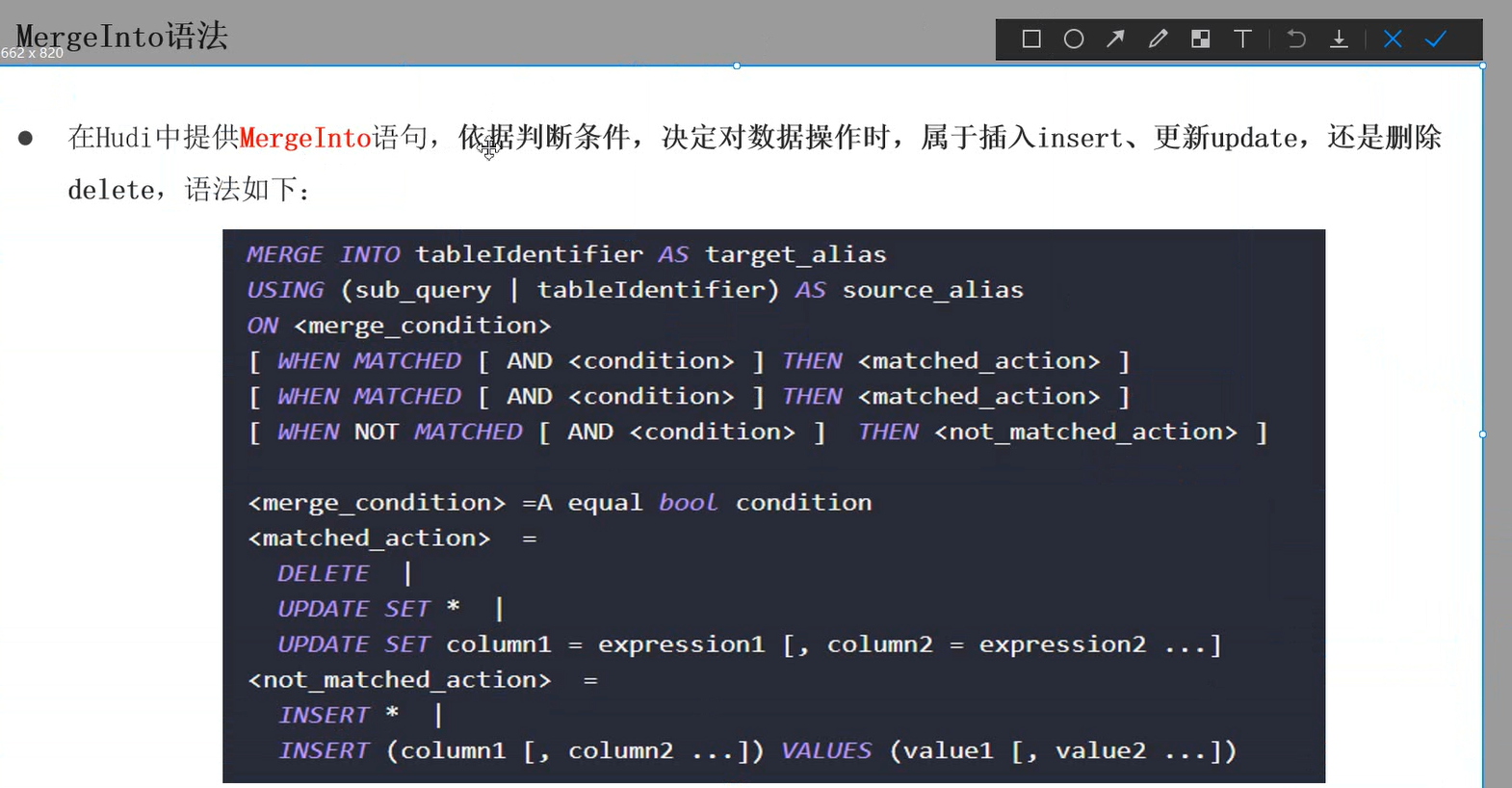
插入
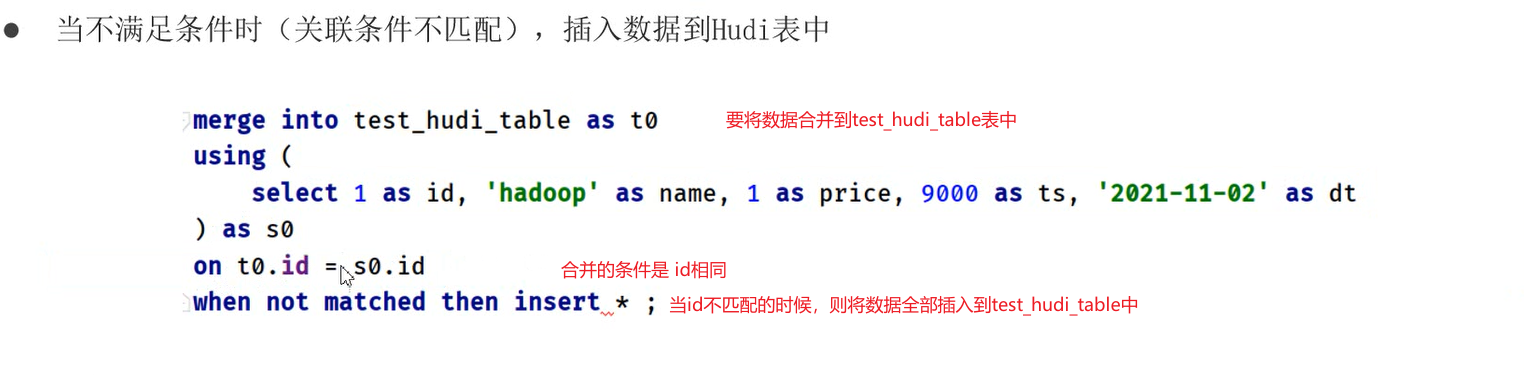
更新

删除

总结
1、hudi与spark集成时其他大数据框架的安装部署
2、以滴滴运营数据为被禁,使用spark操作数据,写入hudi表和从hudi表中读取数据进行分析
3、hive与hudi集成,通过表的映射,直接编写hive-sql进行分析hudi表的数据
4、结构化流实时将数据写入hudi
5、hudi0.9版本支持spark-sql,可以直接通过spark-sql命令行的方式操作hudi表数据
6、在集成的时候,如果出现java.lang.NoSuchMethodError 那基本上是版本冲突的我呢提,集成的jar包不对
六、huid—Flink
6.1 集成
Flink集成Hudi时,本质将集成jar包:hudi-flink-bundle_2.12-0.9.0.jar,放入Flink 应用CLASSPATH下即可。
Flink SQL Connector支持Hudi作为Source和Sink时,两种方式将jar包放入CLASSPATH路径:
方式一:运行Flink SQL Client命令行时,通过参数【-j xx.jar】指定jar包
方式二:将jar包直接放入Flink软件安装包lib目录下【$FLINK_HOME/lib】
6.2 sql-client
6.2.1 启动sql-client
启动flink-sql客户端:
start-dfs.sh
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
/opt/apps/flink-1.12.2/bin/start-cluster.sh
/opt/apps/flink-1.12.2/bin/sql-client.sh embedded shell
6.2.2 flink-sql对hudi进行CRUD
set execution.result-mode=tableau;
建表语句:
drop table if exists flink_test1;
create table flink_test1(
uuid varchar(20),
name varchar(10),
age int,
ts timestamp(3),
`partition` varchar(20)
)
partitioned by (`partition`)
with(
'connector' = 'hudi',
'path'='hdfs://linux01/hudi-warehouse/flink_test1',
'write.tasks'='1',
'compaction.tasks'='1',
'table.type'='MERGE_ON_READ'
);
插入数据:
insert into flink_test1 values('id02','w2',10,TIMESTAMP '2021-01-01 00:00:02','par2'),('id03','w3',10,TIMESTAMP '2021-01-01 00:00:03','par3'),('id04','w4',10,TIMESTAMP '2021-01-01 00:00:04','par4');
更新:
使用插入语句:将id01的age改为20 只能又一个字段改变时,才是更新,否则为插入
insert into flink_test1 values('id02','w1',30,TIMESTAMP '2021-01-01 00:00:01','par1');
查看hdfs中的数据:由于是MOR类型,所以只有日志文件,暂时并未合并为parquent文件
6.2.3 flink-sql 流式查询
流式查询:
3. 创建表,采用Streaming方式读取数据,映射到上面创建t1 表 路径与flink_test1一致
'read.streaming.enabled' = 'true', 开启流式查询
'read.streaming.start-commit' = '20210508202020', 查询的表的数据提交时间在这个时间之后的数据
'read.streaming.check-interval' = '4' 每间隔4秒进行一次检查
建表:
CREATE TABLE flink_test2(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://linux01:8020/hudi-warehouse/flink_test1',
'table.type' = 'MERGE_ON_READ',
'read.tasks' = '1',
'read.streaming.enabled' = 'true',
'read.streaming.start-commit' = '20220507202020',
'read.streaming.check-interval' = '4'
);
这时候进行: select * from flink_test2; 会查询hudi-flink-test1这个hudi表对应的数据,而且流式查询,会一直运行,每间隔4秒进行一次数据更新
4. 重新开启终端,创建t1表,关联Hudi中表hudi-flink-test1,插入数据
CREATE TABLE t1(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://linux01:8020/hudi-warehouse/flink_test1',
'write.tasks' = '1',
'compaction.tasks' = '1',
'table.type' = 'MERGE_ON_READ'
);
insert into t1 values ('id9','test',27,TIMESTAMP '1970-01-01 00:00:01','par5');
insert into t1 values ('id10','test',27,TIMESTAMP '1970-01-01 00:00:01','par5');
此时在流式表中,会一直查询出最新的表
-----+-----+---+--------------------+----------+
uuid |name |ge | ts |partition |
-----+-----+---+--------------------+----------+
id01 | w1 |20 |2021-01-01T00:00:01 | par1 |
id02 | w2 |10 |2021-01-01T00:00:02 | par2 |
id03 | w3 |10 |2021-01-01T00:00:03 | par3 |
id04 | w4 |10 |2021-01-01T00:00:04 | par4 |
id9 |test |27 |1970-01-01T00:00:01 | par5 |
id10 |test |27 |1970-01-01T00:00:01 | par5 |
光标会一直闪烁....
--总结:
-1-使用flink-sql创建hudi表,指定表在hdfs中的路径,指定表的类型为hudi
-2-在flink-sql客户端,向这个hudi表中插入数据
-3-更新数据,使用的也是insert的方式
-4-创建任何一个hudi模式的表,只要路径是一致的,并且表的字段类型都一致,那么新的表所对应的数据都是对应的hdfs中的hudi表的数据,也就是说,数据是存在hdfs中的,只要创建的表类型一致,路径一致,那么表的数据也就一致
-5-创建流式查询,创建一个流式hudi表,路径指向已经存在的hudi表数据,然后进行查询这个流式表,便可以进行流式查询,不断的向这个hudi表路径插入数据,流式表的查询结果数据就会不断的更新。
6.2.4 flink-sql 实时读kafka
flink-sql 实时将kafka中的数据 入湖
指定连接jar包,将flink-sql与kafka建立连接
./sql-client.sh embedded -j /opt/data/flink-sql-connector-kafka_2.12-1.12.2.jar shell
--开启hdfs、zookeeper、kafka、flink-cluster、flink-sql-client
开启flink-cluster需要将 hudi与flink集成的jar包放到flink的lib目录下,要版本对应上
开启flink-sql-client的时候,如果想与kafka集成,就要在开启的时候,指定连接的jar包
--kafka不断产生数据
--新建hudi表,模式为kafka,
CREATE TABLE flink_kafka (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'flink-topic',
'properties.bootstrap.servers' = 'linunx01:9092,linux02:9092,linux03:9092',
'properties.group.id' = 'test-group-10001',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv'
);
--查询这个表,就会发现这是个流式表,可以一直查询从kafka中消费的数据
select * from flink_kafka;
6.3 idea中写入hudi
实时读kafka数据入湖
import lombok.extern.slf4j.Slf4j;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import static org.apache.flink.table.api.Expressions.$;
/*
Author: Tao.W
D a te: 2022/5/18
Description: 目前flink与hudi的结合只支持 flink-sql的方式
流式 读kafka数据 写入 hudi
1.创建kafka表 ,读取kafka数据
2.对kafka-source-table 进行etl 注册试图
3.创建hudi表
4.通过flink-sql方式,将数据insert into 到hudi中
*/
@Slf4j
public class FlinkHudi {
public static void main(String[] args) {
//增量的将数据 流式的 从kafka消费 经过ETL 最后写入hudi
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.enableCheckpointing(5000);
EnvironmentSettings setting = EnvironmentSettings.newInstance().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, setting);
//使用flink-sql 消费kafka
tableEnv.executeSql("CREATE TABLE order_kafka_source (\n" +
" orderId STRING,\n" +
" userId STRING,\n" +
" orderTime STRING,\n" +
" ip STRING,\n" +
" orderMoney DOUBLE,\n" +
" orderStatus INT\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'order-topic',\n" +
" 'properties.bootstrap.servers' = 'linux01:9092,linux02:9092,linux03:9092',\n" +
" 'properties.group.id' = 'gid-1002',\n" +
" 'scan.startup.mode' = 'earliest-offset',\n" +
" 'format' = 'json',\n" +
" 'json.fail-on-missing-field' = 'false',\n" +
" 'json.ignore-parse-errors' = 'true'\n" +
")");
Table etlTabl = tableEnv
.from("order_kafka_source")
.addColumns($("orderTime").substring(0, 10).as("partition_day"))
.addColumns($("orderId").substring(0, 17).as("ts"));
//创建视图
tableEnv.createTemporaryView("view_order",etlTabl);
//tableEnv.executeSql("select * from view_order ").print(); 执行这个的话 就会触发action算子,然后一直停留在这不向下执行
log.info("读取kafka数据成功------------------");
// //创建输出表 关联到hudi
tableEnv.executeSql("CREATE TABLE order_hudi_sink (\n" +
" orderId STRING PRIMARY KEY NOT ENFORCED,\n" +
" userId STRING,\n" +
" orderTime STRING,\n" +
" ip STRING,\n" +
" orderMoney DOUBLE,\n" +
" orderStatus INT,\n" +
" ts STRING,\n" +
" partition_day STRING\n" +
")\n" +
"PARTITIONED BY (partition_day)\n" +
"WITH (\n" +
" 'connector' = 'hudi',\n" +
" 'path' = '/hudi-warehouse/order_hudi_sink',\n" + //设置数据的保存路径
" 'table.type' = 'MERGE_ON_READ',\n" +
" 'write.operation' = 'upsert',\n" + //方式是update 增量写入
" 'hoodie.datasource.write.recordkey.field'= 'orderId',\n" +
" 'write.precombine.field' = 'ts',\n" +
" 'write.tasks'= '1'\n" +
")");
//通过子查询的方式 将数据写入到输出表
tableEnv.executeSql("insert into order_hudi_sink select orderId,userId,orderTime,ip,orderMoney,orderStatus,ts,partition_day from view_order");
}
}
读hudi中的数据
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/*
Author: Tao.W
D a te: 2022/7/19
Description:
*/
public class FlinkSourceHudi {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.enableCheckpointing(5000);
EnvironmentSettings setting = EnvironmentSettings.newInstance().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, setting);
tableEnv.executeSql("CREATE TABLE order_hudi_sink (\n" +
" orderId STRING PRIMARY KEY NOT ENFORCED,\n" +
" userId STRING,\n" +
" orderTime STRING,\n" +
" ip STRING,\n" +
" orderMoney DOUBLE,\n" +
" orderStatus INT,\n" +
" ts STRING,\n" +
" partition_day STRING\n" +
")\n" +
"PARTITIONED BY (partition_day)\n" +
"WITH (\n" +
" 'connector' = 'hudi',\n" +
" 'path' = '/hudi-warehouse/order_hudi_sink',\n" + //设置数据的保存路径
" 'table.type' = 'MERGE_ON_READ',\n" +
" 'hoodie.datasource.write.recordkey.field'= 'orderId',\n" +
" 'write.precombine.field' = 'ts',\n" +
" 'write.tasks'= '1'\n" +
")");
// tableEnv.executeSql("CREATE TABLE order_hudi_sink_2 (\n" +
// " orderId STRING PRIMARY KEY NOT ENFORCED,\n" +
// " userId STRING,\n" +
// " orderTime STRING,\n" +
// " ip STRING,\n" +
// " orderMoney DOUBLE,\n" +
// " orderStatus INT,\n" +
// " ts STRING,\n" +
// " partition_day STRING\n" +
// ")\n" +
// "PARTITIONED BY (partition_day)\n" +
// "WITH (\n" +
// " 'connector' = 'hudi',\n" +
// " 'path' = '/hudi-warehouse/order_hudi_sink',\n" +
// " 'table.type' = 'MERGE_ON_READ',\n" +
// " 'read.streaming.enable'='true',\n"+
// " 'read.streaming.check-interval'='4'\n"+
// ")");
tableEnv.executeSql("select * from order_hudi_sink limit 100").print();
}
}
6.4 flink-cdc-hudi
6.4.1 CDC介绍
CDC 全称是Change data Capture,即变更数据捕获,主要面向数据库的变更,是数据库领域非常常见的技术,主要用于捕获数据库的一些变更,然后可以把变更数据发送到下游
对于CDC,业界主要有两种类型:
一是基于查询的,客户端会通过SQL方式查询源库表变更数据,然后对外发送。
二是基于日志的,这也是业界广泛使用的一种方式,一般是通过binlog方式,变更的记录会写入binlog,解析binlog后会写入消息系统,或直接基于Flink CDC进行处理
典型CDC入湖的链路:
(1)链路是大部分公司采取的链路,前面CDC的数据先通过CDC工具导入Kafka或者Pulsar,再通过Flink或者是Spark流式消费写到Hudi里。
(2)链路是通过Flink CDC直联到MySQL上游数据源,直接写到下游Hudi表
6.4.2 Flink-cdc-hudi-hive
业务需求:
MySQL数据库创建表,实时添加数据,通过Flink CDC将数据写入Hudi表,并且Hudi与Hive集成,自动在Hive中创建表与添加分区信息,最后Hive终端Beeline查询分析数据。
Hudi 表与Hive表,自动关联集成,需要重新编译Hudi源码,指定Hive版本及编译时包含Hive依赖jar包
6.4.3 环境准备
修改Hudi集成flink和Hive编译依赖版本配置,重新编译
原因:现在版本Hudi,在编译的时候本身默认已经集成的flink-SQL-connector-hive的包,会和Flink lib包下的flink-SQLconnector-hive冲突。所以,编译的过程中只修改hive编译版本。
文件:hudi-0.9.0/packaging/hudi-flink-bundle/pom.xml
编译Hudi源码
mvn clean install -DskipTests -Drat.skip=true -Dscala-2.12 -Dspark3 -Pflink-bundle-shade-hive2
编译完成后:
将hudi-0.9.0/packing/hudi-flink-bundle/target/hudi-flink-bundle_2.12-0.9.0.jar 和
flink-sql-connector-mysql-cdc-1.3.0.jar(flink cdc编译后的jar包) 放到flink下的lib目录中
将hudi-0.9.0/packing/hudi-hadoop-mr-bundle/target/hudi-hadoop-mr-bundle-0.0.9.jar放到hive的lib目录中

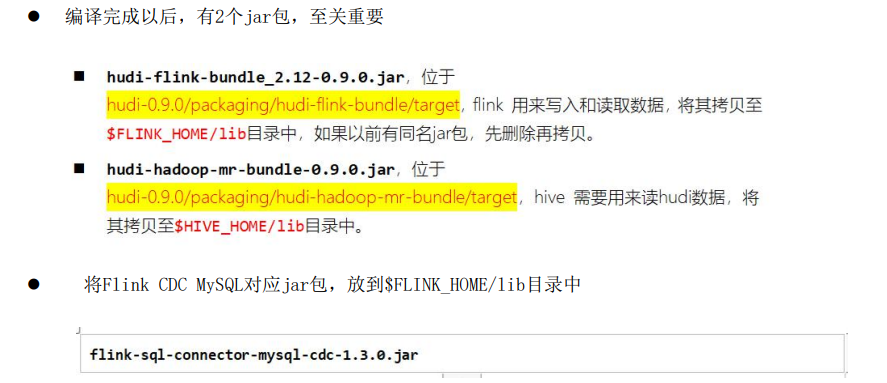
flink-sql-connector-mysql-cdc-1.3.0 :是通过编译flink-cdc源码得到的
6.4.4 开发步骤
6.4.4.1 mysql日志准备
1.开启 mysql日志服务
vi /etc/my.cnf
在【mysqld】下面添加如下内容:
server-id=2
log-bin=mysql-bin
binlog_format=row
expire_logs_days=15
binlog_row_image=full
2.重启MySQL Server
service mysqld restart
3.验证日志是否开启
登录mysql
show master logs;
4.建表
create table hudiDB.tbl_users(id bigint auto_increment primary key,name varchar(20),birthday timestamp default current_timestamp not null,ts timestamp default current_timestamp not null);
6.4.4.2 启动各种服务
启动hdfs
启动mysql
启动 hive: hive --service metastore & // hiveserver2 &
启动flink集群:
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
/start-cluster.sh
启动flink-sql客户端:
/opt/apps/flink-1.12.2/bin/sql-client.sh embedded -j /opt/apps/flink-1.12.2/lib/hudi-flink-bundle_2.12-0.9.0.jar shell
设置属性:
set execution.result-mode=tableau;
set execution.checkpointing.interval=3sec;
6.4.4.2 创建cdc表
-- flink-sql client 创建输入表关联mysql表 采用mysql-cdc关联
create table users_source_mysql(
`id` bigint primary key,
`name` string,
`birthday` timestamp(3),
`ts` timestamp(3)
)with(
'connector' = 'mysql-cdc',
'hostname'='linux01',
'port'= '3306',
'username'='root',
'password' = '*****',
'server-time-zone'='Asia/Shanghai',
'debezium.snapshot.mode'='initial',
'database-name'='hudiDB',
'table-name'='tbl_users'
);
查询cdc表:
select * from users_source_mysql;
向mysql中 hudiDB.tbl_users插入数据:
insert into tbl_users (name) values ('zhangsan');
此时可以看到users_source_mysql 表中的数据又增加,说明 cdc成功
- 创建视图
在flink-sql中创建视图(增加日期一列,作为后面hudi表的分区):
create view view_users_source as select *,DATE_FORMAT(birthday,'yyyyMMdd') as part from users_source_mysql;
查询试图:
select * from view_users_source;
3.创建hudi表 实时写入hudi
-- 创建hudi表 自动同步到hive中,分区也是同步
create table users_sink_hudi_hive(
`id` bigint ,
`name` string,
`birthday` timestamp(3),
`ts` timestamp(3),
part varchar(20),
primary key(id) not enforced
)
partitioned by (part)
with(
'connector'='hudi',
'path' = 'hdfs://linux01:8082/hudi-warehouse/users_sink_hudi_hive',
'table.type'='MERGE_ON_READ',
'hoodie.datasource.write.recordkey.field'= 'id',
'write.precombine.field' = 'ts',
'write.tasks'= '1',
'write.rate.limit'='2000', -- 每次写2000条数据
'compaction.tasks'='1', -- 压缩的task为1
'compaction.async.enabled'='true', -- 开启异步
'compaction.trigger.strategy'='num_commits', -- 根据提交的次数来触发合并
'compaction.delta_commits'='1',
'changelog.enabled'='true', -- 开启捕获日志
'read.streaming.enabled'='true', -- 流式读
'read.streaming.check-interval'='3', -- 每隔3秒读一次
'hive_sync.enable'='true', -- 开启自动hive同步
'hive_sync.mode'='hms', -- 同步方式为同步hive的metastore
'hive_sync.metastore.uris'='thrift://linux01:9083', -- metastore的地址
'hive_sync.jdbc_url'='jdbc:hive2://linux01;10000', -- hive的jdbc地址hiveserver2
'hive_sync.table'='users_sink_hudi_hive', -- 同步到hive中的表名
'hive_sync.db'='default', -- 同步到hive的库名
'hive_sync.username'='root',
'hive_sync.password'='*****',
'hive_sync.support_timestamp'='true' -- 是否支持时间戳(支持)
);
-- 数据写入hudi
insert into users_sink_hudi_hive select id,name,birthday,ts,part from view_users_source;
-- 查询hudi数据
select * from users_sink_hudi_hive;
- hive中查询
-- hive 表查询
启动 beeline
set hive.exec.mode.local.auto=true;
set hive.input.format=org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat;
set hive.mapred.mode=nonstrict;
select name, ts from users_sink_hudi_hive_ro where part ='20211125';
#自动同步到hive中后,会在hive中产生两张表:
1. users_sink_hudi_hive_ro,ro 表全称 read oprimized table,对于 MOR 表同步的 xxx_ro 表,只暴露压缩后的 parquet。类似读优化查询,只查压缩后的数据,日志中的数据暂不查询其查询方式和COW表类似。设置完 hiveInputFormat 之后 和普通的 Hive 表一样查询即可;
2. users_sink_hudi_hive_rt,rt表示增量视图,主要针对增量查询的rt表;ro表只能查parquet文件数据, rt表 parquet文件数据和log文件数据都可查
七、hudi客户端
./hudi-cli.sh
connect --path hdfs://linux01:8020/hudi-warehouse/tbl_hudi_order
查看Hudi commit信息
commits show --sortBy "CommitTime"
查看Hudi compactions 计划
compactions show all


















 306
306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









