




Spark
一、Spark介绍
1.1 简介、特点
1) 开发语言:scala,同时兼顾java,有时会用到pathon
2)Spark是一种快速、通用、可扩展的大数据分析引擎
3)特点:
快速高效
简洁易用
可以运行在各种资源调度框架和读写多种数据源
通用性高
多种部署方案
丰富的数据源支持
1.2 面试题MR与spark的最大区别
1.MR只能做离线计算。如果实现复杂计算逻辑,一个MR搞不定,就需要将多个MR按照先后顺序连成一串,一个MR计算完成后会将计算结果写入到HDFS中,下一个MR将上一个MR的输出作为输入,这样就要频繁读写HDFS,网络IO和磁盘IO会成为性能瓶颈。从而导致效率低下。
2.既可以做离线计算,有可以做实时计算,提供了抽象的数据集(RDD、Dataset、DataFrame、DStream)有高度封装的API,算子丰富,并且使用了更先进的DAG有向无环图调度思想,可以对执行计划优化后在执行,并且可以数据可以cache到内存中进行复用。
注意:MR和Spark在Shuffle时数据都落本地磁盘
1.3 部署spark
上传、解压、配置、分发
配置文件:
/conf/spark-env.sh -->配置jdk和master节点
export JAVA_HOME=/usr/local/jdk1.8.0_251/
export SPARK_MASTER_HOST=node-1.51doit.com
export SPARK_WORKER_CORES =4 #指定worker可用的逻辑核数
export SPARK_WORKER_MEMORY=2g #指定worker可用的内存大小
/conf/workers
-->配置worker节点机器
linux01
linux02
也可配置高可用,用zookeeper来管理集群,详情见详细文档
启动:已经配置了环境变量
start-spark-all.sh
stop-spark-all.sh
启动客户端:
spark shell是spark中的交互式命令行客户端,可以在spark shell中使用scala编写spark程序,启动后默认已经创建了SparkContext,别名为sc
在bin目录下启动spark-shell
/bigdata/spark-3.0.0-bin-hadoop3.2/bin/spark-shell --master spark://linux01:7077
--executor-memory 1g --total-executor-cores 3
页面访问端口:linux01:8080
二、 spark架构体系
2.1 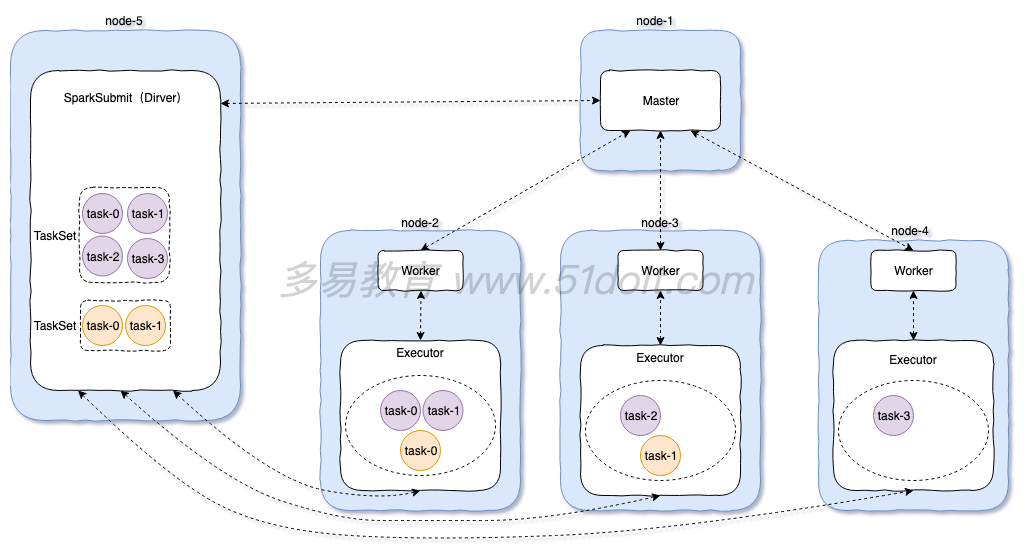
standalone模式流程:
1)先启动Master,再启动Worker,worker启动后向master注册,master定期检查worker(心跳机 制)
2)开启一个线程提交任务:spark-submit,向master提交任务,然后master选择相应的worker进行接收任务。然后worker向Driver端反向注册,拉取任务。然后再worker的executor中执行任务逻辑
3)最后将计算结果发送到Driver端
2.2 standalone cluster 模式
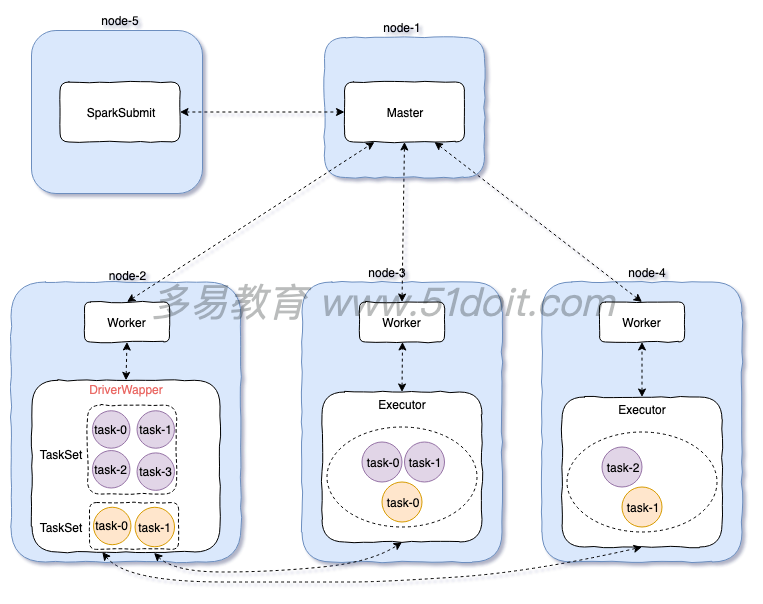
cluster模式:
1)先启动Master,再启动Worker,worker启动后向master注册,master定期检查worker(心跳机 制)
2)开启一个线程sparkSubmit提交任务,向master提交任务
3)master会在worker中开启一个DriverWapper,然后将任务交给DriverWapper。这里DriverWapper就相当于Driver,而client模式Driver是运行在sparkSubmit进程中
4)然后其他的Worker向DriverWapper进行拉取任务,然后在自己的executor中执行
注意:
提交任务的jar包必须在DriverWapper所在的机器上,但是master会随机选择一个worker开启DriverWapper,你也不知道在哪台机器上,所以:
**使用cluster模式,应该将jar包上传到hdfs中
2.3 spark On YARN cluster 模式
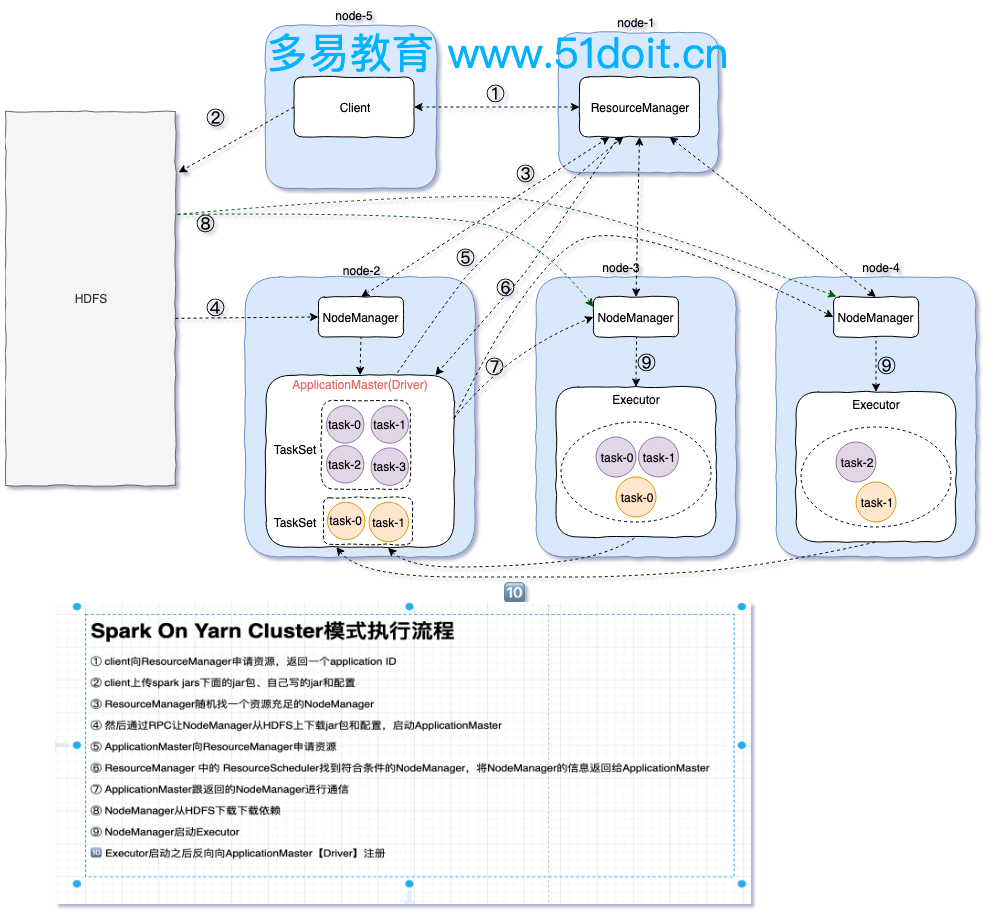
spark On Yarn是生产环境中常使用的一种模式:
1)需要开启hdfs和yarn,(更改hadoop的一些配置,具体的在文档中可见)
不需要开启spark,会将spark的一些配置文件打成jar包
**Linux同步时间命令:(同时发给所有机器:使用send to all sension)
命令:date -s "2021-08-08 09:35:50"
2)以命令的方式运行spark On Yarn
/opt/apps/spark-3.1.2-bin-hadoop3.2/bin/spark-submit
--master yarn
--deploy-mode cluster
--executor-memory 1g
--executor-cores 2 --并行度为2
--num-executors 3 --有三台机器来接收并执行task
--class com.doit.day1.WorkCount
/opt/data/spark_project-1.0-SNAPSHOT-shaded.jar
hdfs://linux01:8020/data/words
hdfs://linux01:8020/out1234
3)spark on yarn cluster 流程
1:client向ResourceManager提交任务,申请资源,ResourceManager返回ApplicationId
2:client向Hdfs上传spark jars下面的jar包,上传自己写的jar包和一些配置文件
3:ResourceManager找一个资源充足的NodeManager向Hdfs下载jar包和配置文件,并启动 ApplicationMaster
(在ApplicationMaster里会启动Driver,而client模式是在客户端的一个进程中启动Driver)
4:Applicationmaster向ResourceManager请求资源,ResourceManager返回可以执行task的节点
5:Applicationmaster与该节点进行交互,该节点从Hdfs上下载jar包和依赖,并启动Executor
6:Executor启动后向ApplicationMaster(Driver)注册
7:ApplicationMaster(Driver)构建DAG切分Satge,将Task序列化发到Executor,然后Executor
执行Task,并将结果返回到Driver端
Yarn-cluster和Yarn-client区别就是:
* Yarn-cluster的driver是在集群节点中随机选取启动ApplicationMaster,然后Driver是运行在 ApplicationMaster中。
* 而Yarn-client中的Driver是运行在提交任务的客户端的一个进程中,节点上启动的是 ExecutorLuacher类似ApplicationMaster,他只具有ApplicationMaster的部分功能,后面的 executor节点也不会向ExecutorLuacher注册,而是向Driver注册,并将结果返回到Drive
2.4 spark On YARN client 模式
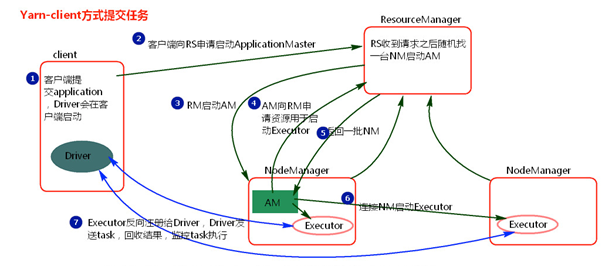
① 客户端提交一个Application,在客户端启动一个Driver进程。
② Driver进程会向ResourceManager发送请求,启动ApplicationMaster的资源。
③ ResourceManager收到请求,随机选择一台NodeManager,然后该NodeManager到HDFS下载jar包和配置,接着启动ApplicationMaster【ExecutorLuacher】。这里的NodeManager相当于Standalone中的Worker节点。
④ ApplicationMaster启动后,会向ResourceManager请求一批container资源,用于启动Executor.
⑤ ResourceManager会找到一批符合条件NodeManager返回给ApplicationMaster,用于启动Executor。
⑥ ApplicationMaster会向NodeManager发送请求,NodeManager到HDFS下载jar包和配置,然后启动Executor。
⑦ Executor启动后,会反向注册给Driver,Driver发送task到Executor,执行情况和结果返回给Driver端
三、编写spark程序
3.1 案例:work-count
def main(args: Array[String]): Unit = {
//创建sparkContext 用sparkContext来创建RDD
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
val lines = sc.textFile(args(0))
//调用RDD的Transformation(s)方法
val words = lines.flatMap(_.split("\\s"))
val wordAndOne = words.map((_, 1))
val reducer = wordAndOne.reduceByKey(_ + _)
val sorted = reducer.sortBy(_._2, false)
sorted.saveAsTextFile(args(1))
sc.stop()
}
val conf = new SparkConf()
val sc = new SparkContext(conf)
val res = sc.textFile('hdfs://linux1:8082/opt/words').flatMap(_.split('//s+')).map((_,1)).reduceByKey(_+_).sortByKey(_._2)
res.saveAsTextFile(path)
sc.stop
然后打包上传到linxu中;
在spark的bin目录下,执行命令spark-submit:
--在bin目录下执行spark-submit进行提交任务
./spark-submit --master spark://linux01:7077 --executor-memory 1g --total-executor-cores 4
--class com.doit.demo1.WordCount ---类的路径名
/opt/data/spark15-1.0-SNAPSHOT.jar ---虚拟机中jar包的路径
hdfs://linux01:8020/data/words ---arg(0) 参数,文件的输入路径,在hdfs上
hdfs:// linux01:8020/out111 --- arg(1) 参数,文件的输出路径,在hdfs上
四、RDD
RDD中并不装真正要计算的数据,而装的是描述信息,描述以后从哪里读取数据,调用了用什么方法,传入了什么函数,以及依赖关系等。
RDD是什么?
1.RDD是弹性分布式数据集,分布式的即意味着分区,意味着分布式计算
2.RDD有多个分区,分区是spark计算的最小执行单元
3.在触发对数据的计算之前,spark只存储对数据处理的逻辑,并不会调用数据,而数据与处理
逻辑之家的映射关系便处于RDD中
4.RDD之间存在着依赖,有宽依赖和窄依赖之分,宽依赖会经理shuffle,窄依赖不会
4.1 RDD的特点
有一系列连续的分区
有一个函数作用在每个输入切片上: 每一个分区都会生成一个Task,对该分区的数据进行计算,这个函数就是具体的计算逻辑
RDD和RDD之间存在一些依赖关系:RDD调用Transformation后会生成一个新的RDD,子RDD会记录父RDD的依赖关系,包括宽依赖(有shuffle)和窄依赖(没有shuffle)
(可选的)K-V的RDD在Shuffle会有分区器,默认使用HashPartitioner
(可选的)如果从HDFS中读取数据,会有一个最优位置:spark在调度任务之前会读取NameNode的元数据信息,获取数据的位置,移动计算而不是移动数据,这样可以提高计算效率。
4.2 RDD的算子分类
Transformation:即转换算子,调用转换算子会生成一个新的RDD,Transformation是Lazy的,不会触发job执行。每次使用转换算子都回生成新的RDD,同时新的RDD会记得之前的RDD,即所谓RDD和RDD之间存在一些依赖关系。
Action:行动算子,调用行动算子会触发job执行,本质上是调用了sc.runJob方法,该方法从最后一个RDD,根据其依赖关系,从后往前,划分Stage,生成TaskSet。
4.3 RDD的创建
一定要使用SparkContext才能创建RDD
1)通过并行化方式,将Driver端的集合转成RDD
val rdd1: RDD[Int] = sc.parallelize(Array(1,2,3,4,5,6,7,8))
或者
val rdd1: RDD[Int] = sc.makeRDD(Array(1,2,3,4,5,6,7,8))
2)从HDFS指定的目录据创建RDD
val lines: RDD[String] = sc.textFile("hdfs://node-1.51doit.cn:9000/log")
3)也可以从linux本地读取文件,但是需要每台机器上都有这个文件,不太推荐使用
4.4 分区规则
注意,使用上面两种方式创建RDD都可以指定分区的数量
创建RDD的时候,使用textFile的形式读文件,分区规则:
1)求目录下所有文件的总大小totalSize
2)将总大小除2,也可以传参数除其他数avgSize
3)若某个文件(块)小于avgSize则使用一个分区
4)若某个文件大于avgSize的1.1倍,则将这个文件拆分成两个区,拆分后若余下的数据还是大于avgSize的1.1倍,则再次进行分区
5)当文件很大的时候,平均文件大小超过了128M,则会按照128M作为再次拆分的依据
创建RDD的时候,若使用makeRDD(parallelize)的形式,分区规则:
1)当不指定分区数的时候,默认最大核数就是分区数
2)若指定分区数,则按照分区数来进行分区
五、TransFormation 算子
5.1 不产生shuffle
map filter flatMap mapPartitions mapPartitionsWitnIndex
keys values mapValues flatMapValues union
5.1.0 MapPartitionsRDD
对于TransFormation 算子中不产生shuffle的算子底层使用的都是MapPartitionsRDD,这时一个类
new MapPartitionsRDD[返回值的数据类型,传入的数据类型](rdd,(TaskContext,分区编号,iter迭代器)=>函数)
例如:
new MapPartitionsRDD[Double, Int](rdd1, (_, _, iter) => iter.map(_ * 10.0))
5.1.1 map
map
用法:对集合中的数据逐一操作,常用的用法map((_,1)) 还有对元组数据的map操作
val arr = Array(1,2,3,3,4,5,6,78)
val rdd = sc.makeRDD(arr)
val res = rdd.map(_ * 10)
底层:MapPartitionsRDD
val rdd1 = sc.parallelize(Array(1,2,4,5,6,7,7,89))
val res =
new MapPartitionsRDD[Double, Int](rdd1, (_, _, iter) => iter.map(_ * 10.0))
5.1.2 filter
filter
用法:过滤
val arr = Array(1,2,3,3,4,5,6,78)
val rdd = sc.makeRDD(arr)
val res = rdd.map(e => e%2==1)
底层:MapPartitionsRDD
val rdd1 = sc.parallelize(Array(1,2,4,5,6,7,7,89))
val res =
new MapPartitionsRDD[Double, Int](rdd1, (_, _, iter) => iter.filter(_ %2 ==1))
5.1.3 flatMap
flatMap
用法:先map再压平
val arr = Array("hello java","hello scala","hello sql","hello hdfs","hello hadoop")
val rdd1 = sc.parallelize(arr)
val rdd2 = rdd1.flatMap(_.split(" "))
底层:MapPartitionsRDD
val arr = Array("hello java","hello scala","hello sql","hello hdfs","hello hadoop")
val rdd1 = sc.parallelize(arr)
//若想将函数传进去,必须要变成iterator
val f = (x:String)=>x.split(" ").toIterator
val rdd2 = new MapPartitionsRDD[String, String](rdd1, (_, _, iter) => iter.flatMap(f))
5.1.4 mapPartition
mapPartition
用法:map操作,但是在区内进行map操作,每个分区返回一个迭代器,对迭代器进行操作
mapPartition()可以传参数为true或者false,默认是true,这个布尔值是判断是否保留原来 的分区器
底层:MapPartitionsRDD
map与mapPartition的区别:
mapPartition:作用跟map一样
区别是:
1)mapPartition是分区进行map操作,每个区分配一个迭代器进行map操作,而map是对所有数据进行map操作
2)如果在映射的过程中需要频繁创建额外的对象,使用mapPartitions要比map高效的多,
mapPartitions是一个区创建一个额外的对象,map是每次处理都创建一个额外的对象
比如:当需要连接mysql的数据库的时候,需要建立连接对象,若用map则每条数据都要创建一个连接对象,
,若用mapPartitions则是一个区用一个连接对象
注意:1)连接对象无法被序列化,所以只能放在算子方法中,不能放到外面。若放到算子方法外面, 则在发送给executor的时候,发现有一个外部引用,而这个外部引用是连接mysql的连接对 象,无法被序列化,所以无法发送,进而无法执行
2)在关闭资源的时候,要进行判断是否为最后一条数据,当所有数据执行结束后在再进行关闭。
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[*]")
val sc = new SparkContext(conf)
//分类ID,商品的金额
// (1, 3000.0) ------> (1, 手机, 3000.0)
val tpRDD: RDD[(Int, Double)] = sc.makeRDD(List((1, 3000.0), (2, 2000.0), (3, 2000.0), (2, 2000.0)))
val rdd2 = tpRDD.mapPartitions(it => {
//创建一个JDBC连接(在函数内部创建的,即在Executor中调用时才会创建连接对象)
/*
注意:连接对象无法被序列化,所以只能放在算子方法中,不能放到外面。若放到算子方法外面,则 在发送给executor的时候,发现有一个外部引用,而这个外部引用是连接mysql的连接对象,无法 被序列化,所以无法发送,进而无法执行
*/
val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=utf-8", "root", "123456")
var name: String = null
it.map(t => {
val preparedStatement = connection.prepareStatement("SELECT name FROM tb_category WHERE id = ?")
preparedStatement.setInt(1, t._1)
val resultSet = preparedStatement.executeQuery()
while (resultSet.next()) {
name = resultSet.getString(1)
}
resultSet.close()
preparedStatement.close()
// 在关闭资源的时候,要进行判断是否为最后一条数据,当所有数据执行结束后在再进行关闭。
if(!it.hasNext) {
connection.close()
}
(t._1, name, t._2)
})
})
//根据分类ID,查询数据库获取分类的名称
//对rdd2进行其他的Transformation
val res = rdd2.collect()
println(res.toBuffer)
}
5.1.5 mapPartitionsWitnIndex
mapPartitionsWitnIndex
用法:分区进行map操作,同时可以拿到分区编号
val rdd1 = sc.parallelize(Array(1,2,4,5,6,7,7,89))
val res = rdd1.mapPartitionsWithIndex((index, iter) => iter.map(e => s"partition:$index element:$e"))
底层:MapPartitionsRDD
val rdd1 = sc.parallelize(Array(1,2,4,5,6,7,7,89))
val res = new MapPartitionRDD[String,Int]((_,index,iter)=>iter.map(e => s"partition:$index element:$e"))
5.1.6 keys values
keys values
用法:针对k-v类型的集合,只获取key集合或者value集合
val tpList = List(("spark", 3), ("hadoop", 5), ("flink", 8), ("hive", 5), ("spark", 7), ("flume", 4))
val rdd1 = sc.parallelize(tpList)
val keys = rdd1.keys
val values = rdd1.values
底层:直接map操作就可以了
val keys = rdd1.map(_._1)
val values = rdd1.map(_._2)
5.1.7 mapValues
mapValues
用法:只针对集合中的value进行map操作,比较常用
val tpList = List(("spark", 3), ("hadoop", 5), ("flink", 8), ("hive", 5), ("spark", 7), ("flume", 4))
val rdd1: RDD[(String, Int)] = sc.parallelize(tpList)
val rdd2: RDD[(String, Int)] = rdd1.mapValues(_ * 10)
底层:MapPartitionsRDD
val tpList = List(("spark", 3), ("hadoop", 5), ("flink", 8), ("hive", 5), ("spark", 7), ("flume", 4))
val rdd1: RDD[(String, Int)] = sc.parallelize(tpList)
val res = new MapPartitionsRDD[(String, Double), (String, Int)](rdd1, (_, _, iter) => iter.map {
case (k, v) => (k, v * 10.0)
})
5.1.8 flatMapValues
flatMapValues
用法:对value进行flatMap
/*
运算之后结果为:
("spark","3")
("spark","4")
*/
val tpList = List(("spark", "3,4"), ("hadoop", "5,6"), ("flink", "8,9"), ("hive", "5,7"), ("spark", "7,9"), ("flume", "4"))
val rdd1: RDD[(String, String)] = sc.parallelize(tpList)
val rdd2: RDD[(String, String)] = rdd1.flatMapValues(_.split(","))
底层:MapPartitionsRDD
val tpList = List 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1829
1829




 到【灌水乐园】发言
到【灌水乐园】发言







