




 本文详细介绍了如何通过子类调用Analyzer的tokenStream方法构建分词器,并读入待分词文本。深入解析了createComponents方法的实现,以及如何将Tokenizer和Filter传入TokenStreamComponents。阐述了分词和过滤的执行顺序,以及最终分词结果的返回格式。
本文详细介绍了如何通过子类调用Analyzer的tokenStream方法构建分词器,并读入待分词文本。深入解析了createComponents方法的实现,以及如何将Tokenizer和Filter传入TokenStreamComponents。阐述了分词和过滤的执行顺序,以及最终分词结果的返回格式。
分词入口:子类调用 Analyzer.totkenStream(String fieldName,Read read)。构建分词器,读入待分词文本。
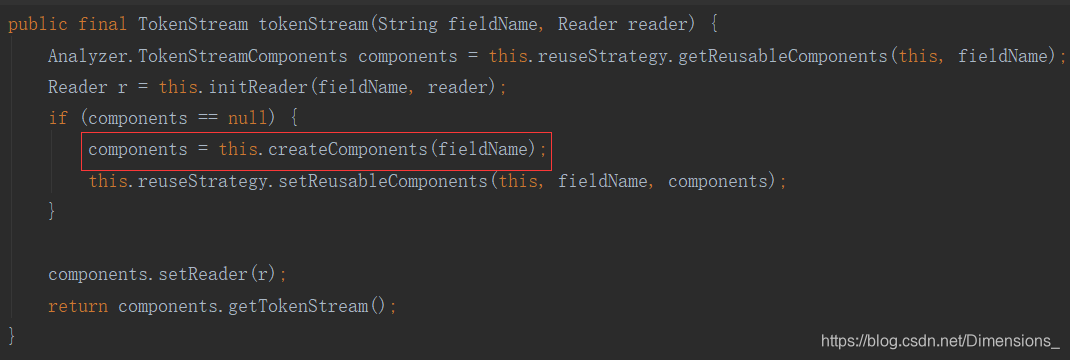
子类中实现createComponents方法
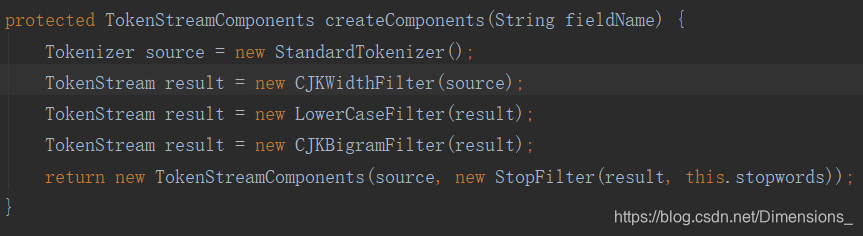
将需要的Tokenizer,及Filter传入TokenStreamComponents , TokenStreamComponents是Analyzer的内部类。

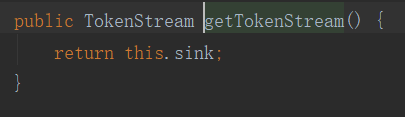
返回对象为包装了Tokenizer的Filter。 Filter继承自TokenStream。
Filter继承自TokenStream。
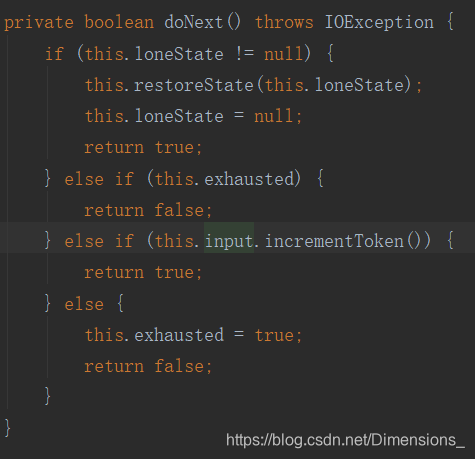
之后用返回的filter对象调用incrementToken方法,外层装饰对象先调用内层装饰对象的incrementToken方法,执行顺序为:最先进行分词,再按照装饰顺序进行过滤,最终分词结果转为指定词元格式后返回。



















 372
372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









