




 本文分享了滴滴在ElasticSearch写入性能优化的实践经验,通过深入分析写入瓶颈,实现了写入性能翻倍,解决了因冷热分离导致的写入延迟问题。优化措施包括改进写入模型、提升单节点写入能力及业务优化,最终每年为公司节省了千万级别的服务器成本。
本文分享了滴滴在ElasticSearch写入性能优化的实践经验,通过深入分析写入瓶颈,实现了写入性能翻倍,解决了因冷热分离导致的写入延迟问题。优化措施包括改进写入模型、提升单节点写入能力及业务优化,最终每年为公司节省了千万级别的服务器成本。


桔妹导读:滴滴ElasticSearch平台承接了公司内部所有使用ElasticSearch的业务,包括核心搜索、RDS从库、日志检索、安全数据分析、指标数据分析等等。平台规模达到了3000+节点,5PB 的数据存储,超过万亿条数据。平台写入的峰值写入TPS达到了2000w/s,每天近 10 亿次检索查询。为了承接这么大的体量和丰富的使用场景,滴滴ElasticSearch需要解决稳定性、易用性、性能、成本等诸多问题。我们在4年多的时间里,做了大量优化,积攒了非常丰富的经验。通过建设滴滴搜索平台,打造滴滴ES引擎,全方位提升用户使用ElasticSearch体验。这次给大家分享的是滴滴在写入性能优化的实践,优化后,我们将ES索引的写入性能翻倍,结合数据冷热分离场景,支持大规格存储的物理机,给公司每年节省千万左右的服务器成本。
1.
背景

前段时间,为了降低用户使用ElasticSearch的存储成本,我们做了数据的冷热分离。为了保持集群磁盘利用率不变,我们减少了热节点数量。ElasticSearch集群开始出现写入瓶颈,节点产生大量的写入rejected,大量从kafka同步的数据出现写入延迟。我们深入分析写入瓶颈,找到了突破点,最终将Elasticsearch的写入性能提升一倍以上,解决了ElasticSearch瓶颈导致的写入延迟。这篇文章介绍了我们是如何发现写入瓶颈,并对瓶颈进行深入分析,最终进行了创新性优化,极大的提升了写入性能。
2.
写入瓶颈分析
▍2.1 发现瓶颈
我们去分析这些延迟问题的时候,发现了一些不太好解释的现象。之前做性能测试时,ES节点cpu利用率能超过80%,而生产环境延迟索引所在的节点cpu资源只使用了不到50%,集群平均cpu利用率不到40%,这时候IO和网络带宽也没有压力。通过提升写入资源,写入速度基本没增加。于是我们开始一探究竟,我们选取了一个索引进行验证,该索引使用10个ES节点。从下图看到,写入速度不到20w/s,10个ES节点的cpu,峰值在40-50%之间。
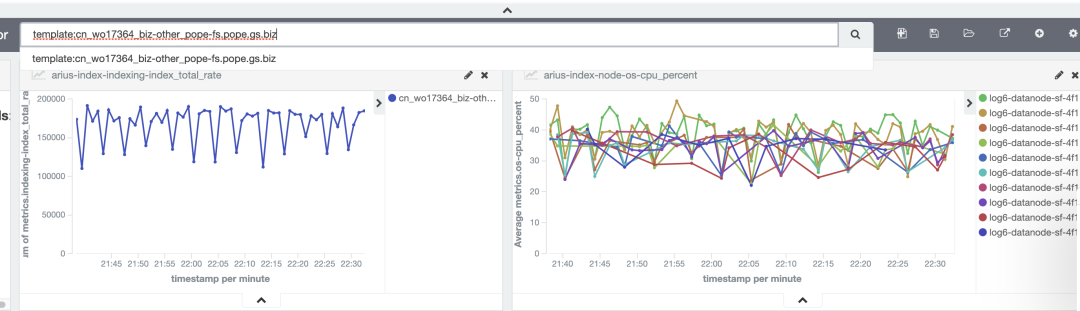
为了确认客户端资源是足够的,在客户端不做任何调整的情况下,将索引从10个节点,扩容到16个节点,从下图看到,写入速度来到了30w/s左右。
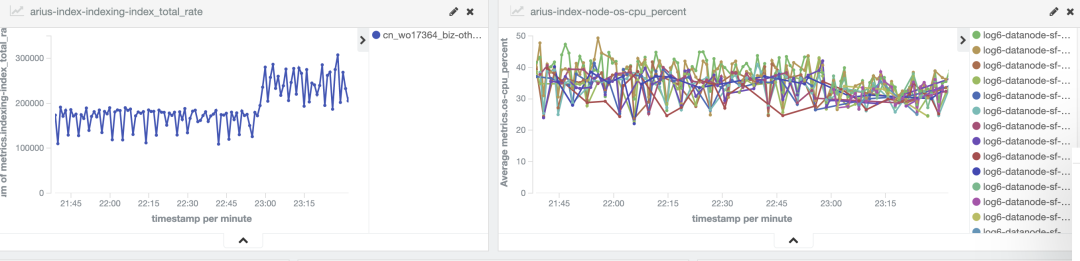
这证明了瓶颈出在服务端,ES节点扩容后,性能提升,说明10个节点写入已经达到瓶颈。但是上图可以看到,CPU最多只到了50%,而且此时IO也没达到瓶颈。
▍2.2 ES写入模型说明
这里要先对ES写入模型进行说明,下面分析原因会跟写入模型有关。
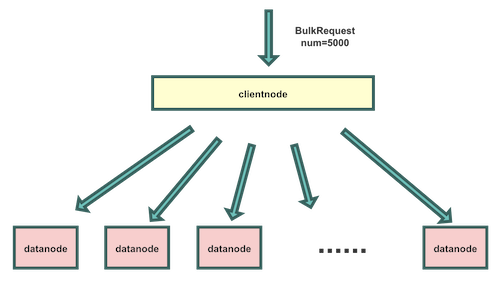
客户端一般是准备好一批数据写入ES,这样能极大减少写入请求的网络交互,使用的是ES的BULK接口,请求名为BulkRequest。这样一批数据写入ES的ClientNode。ClientNode对这一批数据按数据中的routing值进行分发,组装成一批BulkShardRequest请求,发送给每个shard所在的DataNode。发送BulkShardRequest请求是异步的,但是BulkRequest请求需要等待全部BulkShardRequest响应后,再返回客户端。
▍2.3 寻找原因
我们在ES ClientNode上有记录BulkRequest写入slowlog。
`items`是一个BulkRequest的发送请求数
`totalMills `是BulkRequest请求的耗时
`max`记录的是耗时最长的BulkShardRequest请求
`avg`记录的是所有BulkShardRequest请求的平均耗时。
我这里截取了部分示例。
[xxx][INFO ][o.e.m.r.R |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
























 517
517



 到【灌水乐园】发言
到【灌水乐园】发言







