



 周杰伦新歌《说好不哭》上线,QQ音乐销售额破纪录,平台短暂崩溃,显示高并发处理难题。
周杰伦新歌《说好不哭》上线,QQ音乐销售额破纪录,平台短暂崩溃,显示高并发处理难题。
点击上方“开发者技术前线”,选择“星标”
13:21 在看 真爱

吃瓜群众准备好小板凳
瓜有多大
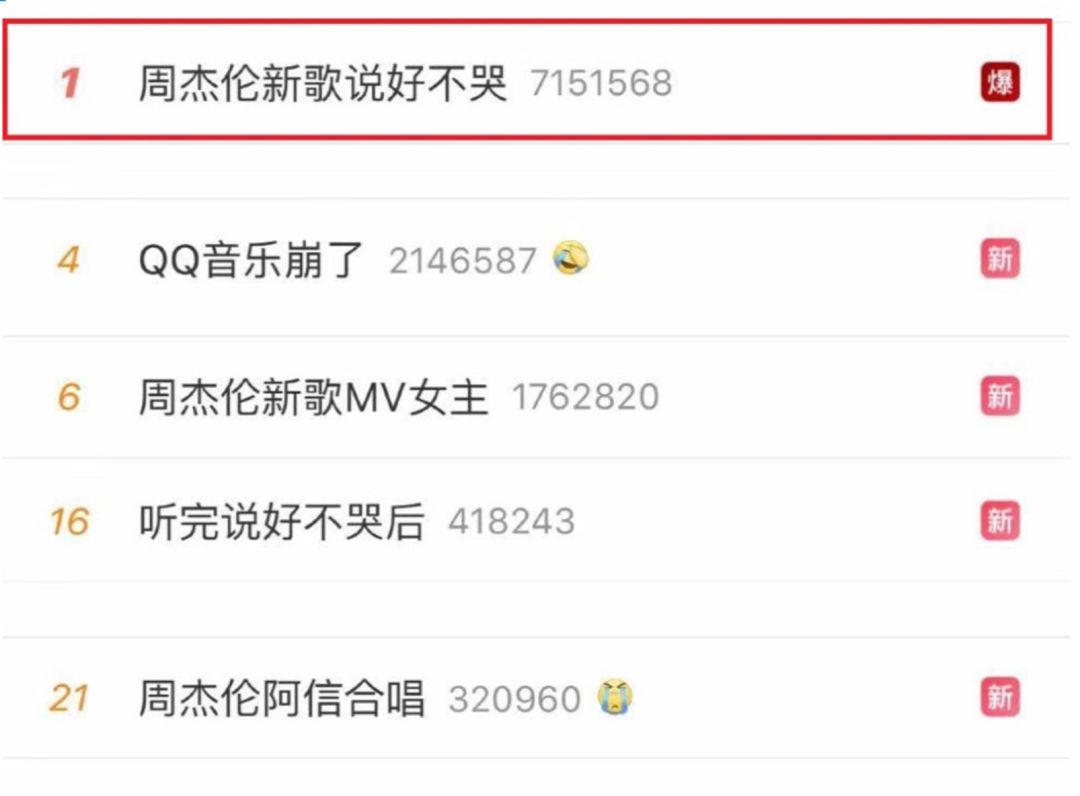
昨日(9月16日)晚间23点,周杰伦新歌《说好不哭》正式上线发售。据QQ音乐数据显示,新单曲上线6分钟,销售额达到500万元;上线100分钟,突破1000万元,成为该平台历史销售额最高的数字单曲(我凑热闹,也买了一张?,怎么能不支持我的偶像呢?)。
由于该单曲的上线,同时涌入用户过多,QQ音乐甚至出现短暂的崩溃。朋友圈被疯狂刷屏、微博热搜前十名挤进5个相关话题…周杰伦“夕阳红粉丝团”正在迎来继超话登顶以来第二个高光时刻。截至截止9月17号18:00,该单曲已经销售620万张铭牌*3元(微信支付2.91元,亲测?)=1890万元。
QQ音乐是大家熟知道的互联网巨头,大家都听说微博经常遇到明星一条突发新闻服务器直接崩溃,却很少听到腾讯旗下的APP出现异常崩溃。
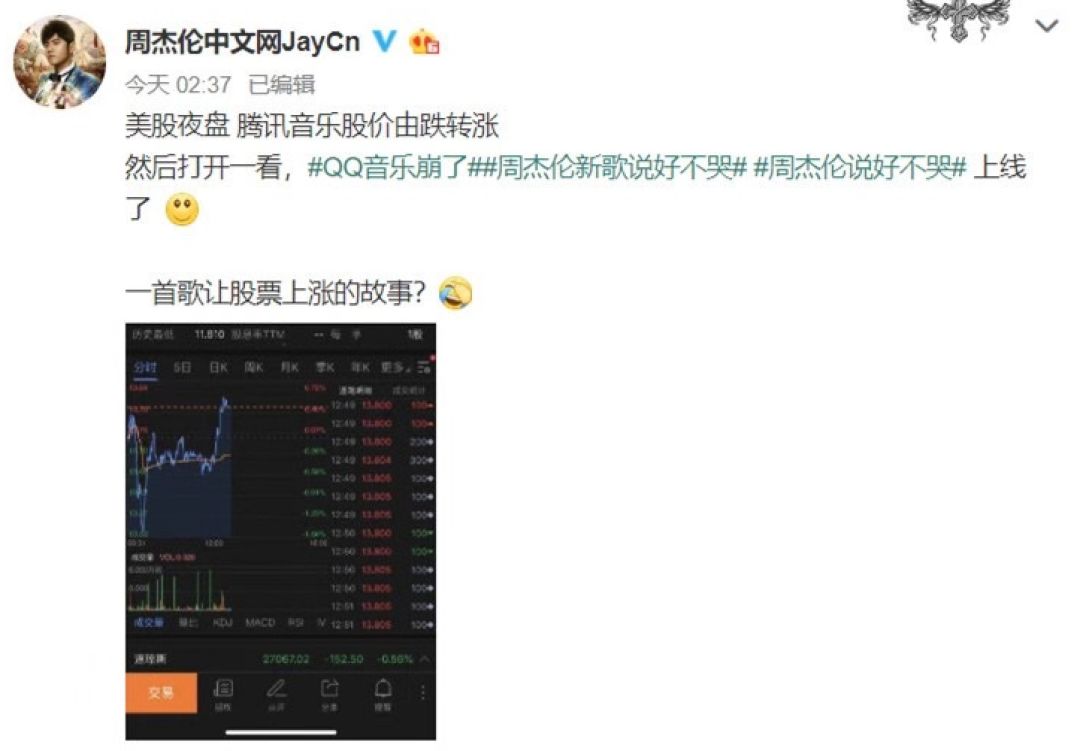
Top5热评
•如果有一天 我带你去看周杰伦的演唱会 那么你一定对我很重要 因为我带你去看的 是我一整个青春•见过让一个软件崩服务器的人吗?他就是周杰伦!出道19年发一个曲子依旧火爆的周杰伦,音乐皇帝!•满怀期待等候多时并且重新下回了qq音乐就是为了此时此刻第一时间来听我伦新歌!!!•等了这么久,终于等到了今天,虽然不是新专但我也一样心满意足,是鸽鸽让我爱上音乐,让我也想和他一样弹钢琴,也是鸽鸽教我要听妈妈的话。我从三岁开始听杰伦的歌,如果说人生中的老师有三个,那么我人生中的老师就是爸妈和杰伦以及让我变得更好的老师们!•“世界上最浪漫的事情是什么呀?”,“当然是带上你的那个她(他)去看一次周杰伦的演唱会啊!毕竟那是自己的整个青春
为什么会挂(个人猜测,非官方)
如何优化的甩锅,又能能升值加薪
•流量突然激增,超出预设请求的阀值(机器没有准备好,为了节省预算,一般互联网都是部署机器的数量跟流量峰值成正比的,高峰会加机器,低峰会线下机器,节省成本,行业内很常见,临时申请机器资源,用完就换回去,节省业务成本,这次估计没有想到杰伦新歌的威力,下次应该不会出现类似问题了。)•流量太大,处理突然激增的方案一直是行业难题,不好弹性伸缩。•系统挂对技术人员是一个好事,说明他们面对的问题很有难度,容易引起引起领导的重视,晋升答辩很有优势,出去技术分享别人也觉着牛,大家提起高并发,肯定第一时间想到的是微博?因为他经常遇到明星出轨,官宣,生子等突发新闻而挂掉,下面拿微博举例子,微博为什么会经常挂
刷微博时,思考这两个问题:
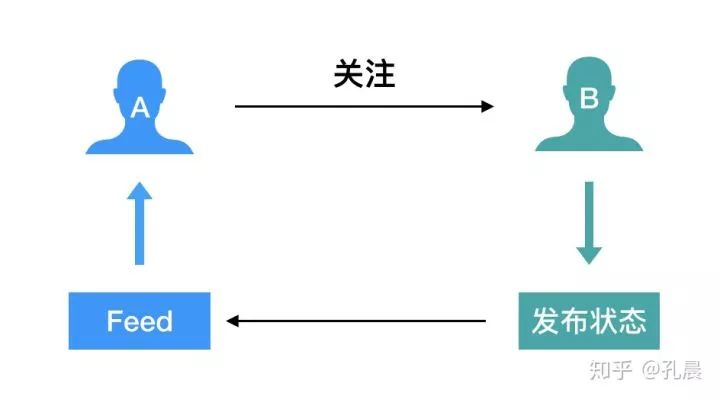
•假如我有1k个粉丝,如果我发一条微博状态,我的1k粉丝如何在一定时间内都收到呢?•假如我关注了1k个用户,那么我如何收到这1k个用户的更新呢?放大这两个问题看看,微博上热门明星的粉丝动辄千万甚至上亿,这样看来,问题开始变得有意思起来。
基本的概念
先来看看Feed的流的基本概念:
•Feed流中的每一条状态或者消息都是Feed,比如微博中的一条微博就是一个Feed。•Feed流持续更新并呈现给用户内容的信息流。每个人微博关注页等等都是一个Feed流。•Timeline其实是一种Feed流的类型,微博,朋友圈都是Timeline类型的Feed流。•关注页Timeline:展示其他人Feed消息的页面,比如微博的首页等。•个人页Timeline:展示自己发送过的Feed消息的页面,比如微博的个人页等。Feed流的主要模式:•推(Push)•拉(Pull)•推拉结合(Hybrid)
推模式
又称写扩散。该方式为每个用户维护一个订阅列表,记录该用户订阅的消息索引(一般为消息ID、类型、发表时间等元数据)。每当用户发布消息时,都会去更新其关注者的订阅列表。
优点:存储空间可能不是很大,用户查询自己关注的所有人Feed时,速度快,性能非常高。
缺点:
1.推送量会非常大。比如微博红人何炅(粉丝1亿+)发一篇微博,如果采用推模式,就会产生一亿+条数据。2.资源浪费。试想,一个大量用户的微博系统如果使用推模式,是不是会产生非常巨大的数据呢?更何况活跃用户只有几千万,剩下几个亿的用户他们可能是半年来一次,或者说更短如两周过来一次;这些数据推给他可能根本没有机会看到,存在很大的资源浪费。
拉模式
又称读扩散。该方式为每个用户维护一个Feed列表,记录该用户所有关注的动态索引。只需要用户发表微博时,存储一条微博数据到Feed表中。用户每次查询Feed时都会去查询Feed表,产生:
SELECT id FROM feeds where uid in(following uid list) ORDER BY id DESC LIMIT n
优点:
这种模式实现起来比较简单,只是在查询的时候需要多考虑下缓存的结构;
缺点:
1.当用户登陆时,必须很快返回数据的时候,运算量非常大。Feeds表会产生很大的压力,对于一个大系统,Feed表会产生比较大的数据,如果粉丝人数比较多,数据库的压力就会非常大。2.一般在线的用户,客户端都会定期扫描,又会增加很大的压力,这在查询性能上没有推模式的效率高。
共性问题:不管推模式还是拉模式都存在如果关注数量或者粉丝数量过多,会导致遍历时间太长的问题。综合所有考虑,因为我们要做的是一个要求实时度很高的系统,把不必要系统开销去掉。
怎么去解决 ?
推拉结合模式
这是一种折中的解决方案:在线推、离线拉。用户发布状态时,即便微博大V,同时在线的粉丝可能只有几万甚至几千。推拉模式只推给在线的粉丝,离线的粉丝上线后手动拉取状态即可同步内容。同时,每个用户都会维护一个类似发件箱与收件箱的东西,来保存自己发过的状态和Feed状态,以完成推和拉。猜想下微信朋友圈,微信每个人的好友有上限,群聊的人数也有上限,所以这就限制了微信朋友圈的设计复杂度应该没有新浪微博那样复杂。
实现
当用户发了一条动态后,后台会有如下这些操作。
在线推:异步遍历在线的粉丝,将动态ID,添加到粉丝的Feed中。
离线拉:离线用户打开APP后,请求一个公共的入口接口,做一些初始化操作。同时开一个异步线程,对用户进行Feed更新操作,防止用户进入APP后等待拉取Feed时间过长,毕竟关注成千上万的人也是有的。
离线拉取过程是把自己最后一条Feed的时间戳取出,去遍历关注、人的Feed,将大于该时间的ID全部拉取回来。用户进入APP后,刷新即可看到最新操作。另外,需全局维护一个在线用户列表,为了防止用户挂后台导致与服务端为离线状态,所以最好是1~3小时未操作或者离线时间不大于3小时的,都当做在线处理,视情况定。
进入关键部分:如何实现一个千万级Feed流系统。要设计一个Feed流系统,最关键的两个核心:存储与推送。
存储
先来看存储,Feed流系统中需要存储的内容分为两部分,一个是账户关系(比如关注列表),一种是Feed消息内容。
考虑维度
•如何能支持100TB,甚至PB级数据量?•数据量大了后成本就很关键,成本如何能更便宜?•如何保证账号关系和Feed不丢失?
分析特点[账户关系存储]
•是一系列的变长链表,长度可达亿级别•数据量大,但关系简单•性能敏感,直接影响关注、取关的响应速度
由于用户关系数据量极大,关系简单不依赖RDBMS的额外特性 (如列数据类型, 第二索引, 高级查询语言等),性能要求还高,因此最适合存账号关系的系统应该是有序性的分布式NoSQL数据库——使用开源HBase存储账号关系。
HBase
如果有上亿或上千亿行数据,HBase是很好的备选。HBase基于HDFS且提供大表记录的高速查找(和更新),存储文件位于 HDFS中。
物理视图如下,它是区分列族存储的。

Row Key
Rowkey和mysql中的主键是完全一样的,HBase使用Rowkey来唯一区分某一行的数据。
HBase只支持三种查询方式:
•基于Rowkey的单行查询•基于Rowkey的范围扫描•全表扫描
因此,Rowkey对HBase的性能影响非常大,Rowkey的设计就显得尤为的重要。
Time Stamp
在HBase中使用不同的TimeStamp来标识相同Rowkey行对应不同版本的数据,它是实现HBase多版本的关键。HBase 中通过 Rowkey 和 Columns来确定一个存储单元称为 cell,每个 cell 都保存着同一份 数据的多个版本,版本通过时间戳来索引。为了避免数据存在过多版本造成的的管理 负担,HBase提供了两种数据版本回收方式:
•保存数据的最后 n 个版本•保存最近一段时间内的版本(设置数据的生命周期 TTL)
Column Family
列族是HBase引入的概念,HBase通过列族划分数据的存储,列族下面可以包含任意多的列,实现灵活的数据存取。列可理解成MySQL列,不需要建表时定义,可灵活添加。
分析特点—Feed消息内容:
•数据量大(特别在推模式下数据量会再膨胀几个数量级),数据量很容易达到PB级别•数据不能丢失,可靠性要求高•数据格式简单
根据上述这些特征,最佳的系统应该是具有主键自增的分布式NoSQL数据,常用做法是采用关系型数据库 + 分库分表来实现。
推送
推送系统需要实现的功能有两个:发布Feed和读取Feed流。
考虑维度:
•如何才能提供千万的TPS和QPS?•如何保证读写延迟在10ms,甚至2ms以下?•如何保证Feed的必达性?
分析Feed流特点:
•多账号内容流:Feed流系统中存在成千上万的账号,账号之间可以关注,取关,加好友和拉黑等操作•非稳定的账号关系:由于存在关注,取关等操作,所以系统中的用户之间的关系就会一直在变化,是一种非稳定的状态•读写比例100:1:读写严重不平衡,读多写少,一般读写比例在10:1,甚至100:1以上•消息必达性要求高:比如发送了一条微博后,结果部分朋友看到了,部分朋友没看到,后果很严重
方案考虑:
如果要实现一个千万量级的Feed流产品,那么推送系统需要具备一些特点:
•具备千万TPS/QPS的能力•必达性要求很高•最好能为用户存储Timeline中所有的Feed•主键自增功能,仍然是保证用户收件箱中的Feed ID是严格递增的,保证可以通过查询(上次读取的最大ID --->MAX)读取到最新未读消息
(SELECT id FROM feeds where uid in(following uid list) ORDER BY id DESC LIMIT n)
因此,推送系统最好是一个性能极佳、可靠、有自增功能的NoSQL系统,所以业内一般如果选择开源系统的话,会在选择了关系型数据库作为存储系统的基础上,选择开源Redis,这样就能覆盖上述的几个特征,也能保证Feed流系统正常运行起来。
如用户A关注了用户B,用户B发布动态则将动态推送到用户A的feed,这里可以使用Redis的zset实现。
•sort为time,以毫秒为时间戳•value为具体的动态+ID,动态的内容可以进行缓存•用户A维护一个zset保存用户B发布的动态,一个zset保存用户B的Feed动态,过期时间3~7天看情况而定
过期时间设置,有个很有意思的产品设计在里面。
一个用户3-7天不打开APP,一方面可能是已经对APP失去兴趣了,打开几率很小,或者已经被卸载了,没有存在的意义了。另一方面,3-7天未登陆APP,关注的人发的动态也不少了,Feed未拉取回来的数据肯定也很多,那么这时候去遍历其实拉取量很大,那么还不如直接全部重新拉一边或者拉取用户最后登陆时间后产出的数据。
由于系统中的所有用户不可能全部在线,更不可能同时刷新和发布Feed,那么一个能支撑千万量级Feed流的系统,在产品上应该可以支撑上亿的用户。
一点感悟
•就像电影特效是为剧情服务,技术永远是为产品服务的,产品需要应对多大的请求量,技术去实现。•不同的业务场景,适合的技术是不一样的。而针对不同的业务难题,并不是一昧地堆机器或挑战更难的技术手段,更应该在产品设计层面深思熟虑。随着产品设计的调整和业务规模的扩大,相应的技术都会做进化和调整。•目的都是一样,那就是留住用户,保障用户体验。
参考
•slideshare.net/iso1600/•新浪微博架构和FEED架构分析--人人架构 - u013790419的专栏 - 优快云博客•如何打造千万级Feed流系统-博客-云栖社区-阿里云
---END---
选择”开发者技术前线 “星标?,内容一触即达。点击原文更多惊喜!
开发者技术前线 汇集技术前线快讯和关注行业趋势,大厂干货,是开发者经历和成长的优秀指南。
历史推荐
点个在看,月薪几万!

















 494
494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









