




 本文解析了WSGI如何触发Flask的__call__方法,解释了应用上下文和请求上下文的创建与使用过程,以及local和localstack在多线程环境下确保数据隔离的作用。
本文解析了WSGI如何触发Flask的__call__方法,解释了应用上下文和请求上下文的创建与使用过程,以及local和localstack在多线程环境下确保数据隔离的作用。
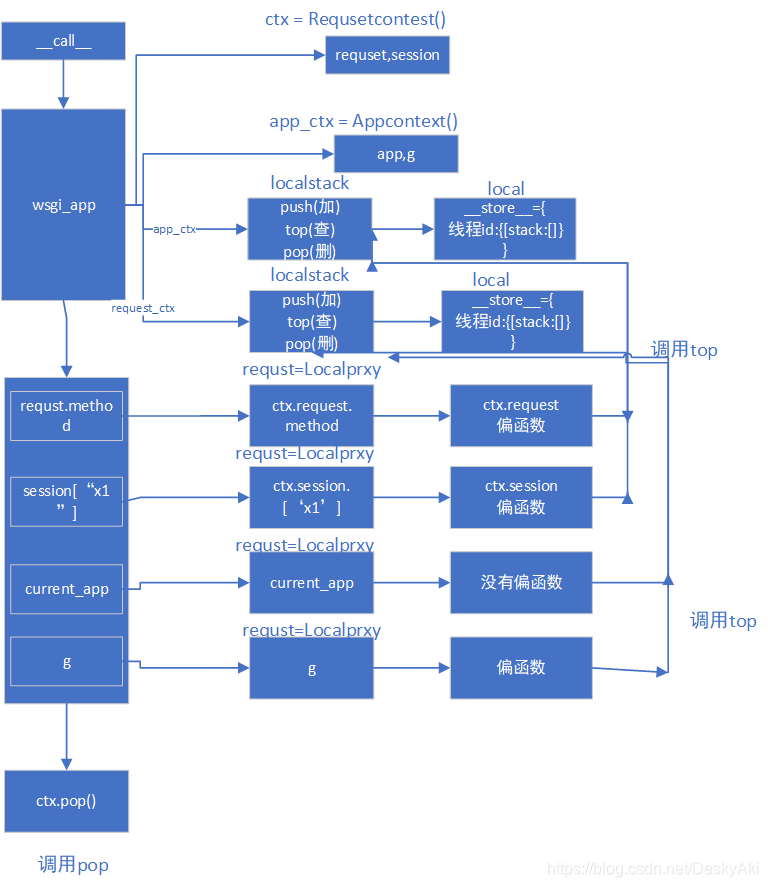
- 请求到来后,wsgi会触发__call__方法,由__call__方法调用wsgi_app方法
- wsgi_app 方法中,创建两个盒子,一个是有app,g的应用上下文,另一个是request,空session的请求上下文
- 应用上下文和请求上下文分别交给两个不同的localstack对象,类似栈的localstack有push,top,pop三个方法,再调用push将它们加到local中,__storage__={线程id:{stack:[]}
- 执行视图函数,视图函数通过localproxy执行localstack的top方法,拿到数据
- 最后执行pop方法,删除上下文
- 当调用app=Flask(__name__)的时候创建了程序应用对象app,
- request 在每次http请求时,wsgi调用Flask__call__(), 然后在Flask内部创建request对象
- app的生命周期大于request和 g, 一个app存活期间,可能发生多次请求,所以可以有多个request和g
- 传入视图
几点说明:
请求上下文:保存了客户端和服务端的交互数据, 临时把某些对象变为全局可访问
应用上下文:在flask程序运行过程中,保存一些配置信息,如程序文件名,数据库连接, 它的作用是帮助request获取当前的应用,它是伴request生, 随request而灭的。
local的作用?
为每个线程开辟一个空间,类似于thread.local作用,不过它更高级,还支持协程
localstack的作用?
把local的值维护成栈,起到线程隔离的作用
为什么导入request就可以使用?
每次执行request.xx时,会触发localproxy的__getattr__等方法,由方法每次动态使用localproxy去local获取数据
为什么要创建两个local?两个localstack?
编写离线脚本时,需要配置文件, 而配置文件放在app中不需要请求相关数据,所以它们分开。
那什么是离线脚本呢?
我的个人理解就是,一个python文件,直接运行,不需要先运行,再用浏览器访问url触发函数

















 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









