




 本文深入解析AXIDMA在ZYNQ中的角色与操作模式,包括Direct Register Mode与Scatter/Gather Mode的区别,以及多通道与循环模式的工作原理,探讨了数据缓存带来的Cache一致性问题。
本文深入解析AXIDMA在ZYNQ中的角色与操作模式,包括Direct Register Mode与Scatter/Gather Mode的区别,以及多通道与循环模式的工作原理,探讨了数据缓存带来的Cache一致性问题。
转载出处:
https://www.cnblogs.com/batianhu/p/zynq_axidma_xiangjie1.html
一、基本概念
AXIDMA: 官方解释是为内存与AXI4-Stream外设之间提供高带宽的直接存储访问,其可选的scatter/gather功能可将CPU从数据搬移任务中解放出来。在ZYNQ中,AXIDMA就是FPGA访问DDR3的桥梁,不过该过程受ARM的监控和管理。使用其他的IP(也是AXI4-Stream转AXI4-MM)可以不需要ARM管理,但是在SOC开发时是危险的,这是后话了。
如图1所示,AXIDMA IP有6个接口,S_AXI_LITE是ARM配置dma寄存器的接口,M_AXI_SG是从(往)存储器加载(上传)buffer descriptor的接口,剩下4个构成两对接口,S2MM和MM2S表示数据的方向,AXI是存储器一侧的接口,AXIS是FPGA一侧的接口。AXIDMA IP和ARM自带的DMA是很像的,只不过不具备从存储器到存储器的功能,当然啦如果将S2MM和MM2S的AXIS接口直接连接也是可以实现的。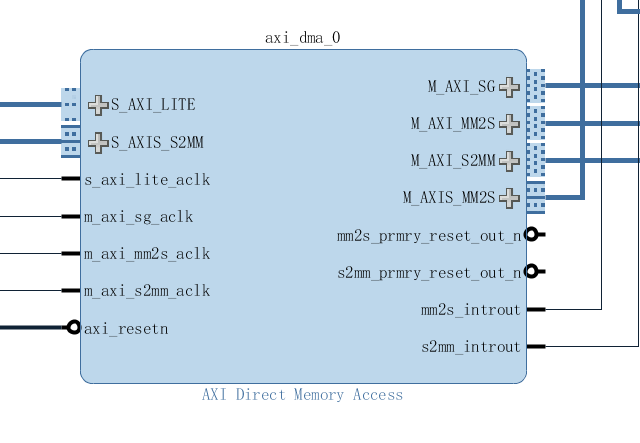
图1
scatter gather模式:AXIDMA工作模式分为两种,分别是Direct Register Mode和Scatter/Gather Mode。
从图2可以看出,Direct Register Mode具备DMA的基本功能,除了控制寄存器和状态寄存器之外,给出源(目的)地址和传输长度之后就可以开启一次传输了。Direct Register Mode的特点(也是缺点)是配置完一次寄存器之后只能完成存储器连续地址空间的读写,如果有需求往不同地址空间搬运数据的话,那就需要重新配置寄存器开启一次新的传输。

图2
鉴于Direct Register Mode的不足,发展出了Scatter/Gather Mode,其工作方式要复杂得多。Scatter/Gather Mode把关于传输的基本参数(比如起始地址、传输长度、包信息等)存储在存储器中,一套参数称之为Buffer Descriptor(简称BD),在工作过程中通过上面提到的SG接口来加载BD并且更新BD中的状态。从图3可以看出,Scatter/Gather Mode下的寄存器列表中没有了Address、Length相关的寄存器了,取而代之的是CURDESC、TAILDESC。
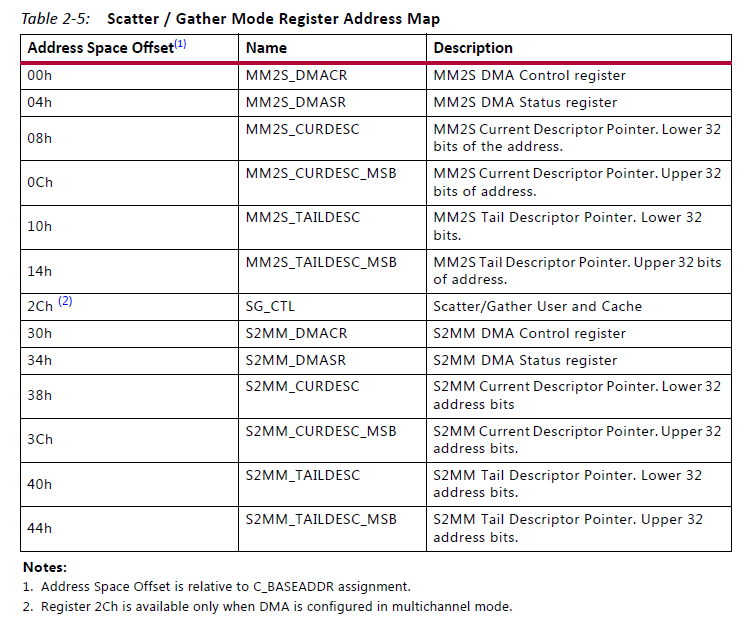
图3
非多通道模式下的BD如图4所示,主要有四部分内容:NXTDESC、BUFFER_ADDRESS、CONTROL、STATUS。NXTDESC指定下一个BD的地址,由此可以构成成一个BD链条,AXIDMA可以顺着该链条依次fetch BD。BUFFER_ADDRESS指定传输的源(目的)地址,CONTROL主要是length和包信息,STATUS反应该BD完成后的状态。
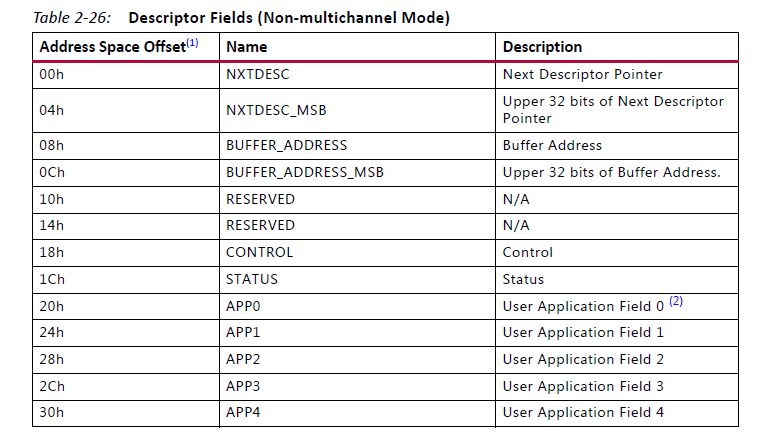
图4
AXIDMA启动后,首先从CURDESC指定的位置加载BD,完成当前BD的传输任务后根据BD链条找到下一个BD,依次完成BD指定的传输,直到遇到TAILDESC指定的BD才停止。
Multichannel DMA:在Scatter/Gather Mode下S2MM和MM2S都支持多个通道,Direct Register Mode不支持多通道。如图5所示,多通道相比非多通道,BD中增加了TID和TDEST,用来区分不同的通道。

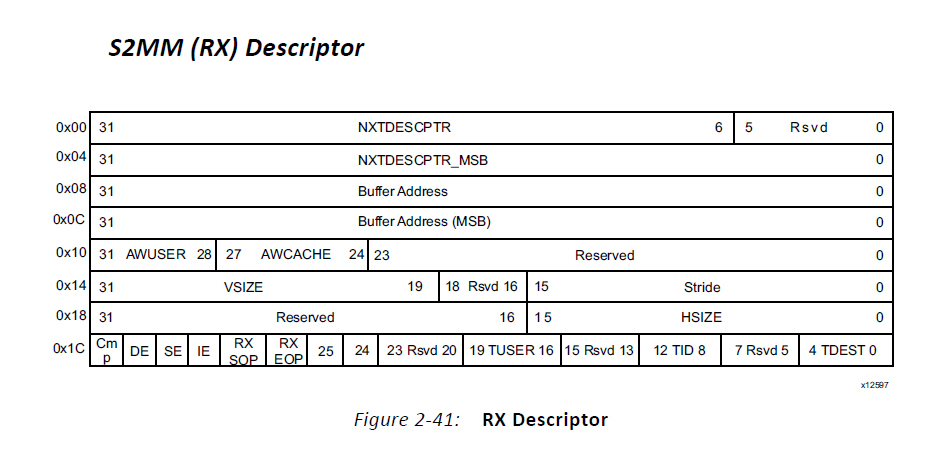
图5
多通道模式支持2D-Transfer,如图6所示,从buffer address开始,读写HSIZE后跳过剩余的Stride - HSIZE个地址单元,下一次从buffer address + Stride位置开始,此过程迭代VSIZE次后结束该BD指定的传输。
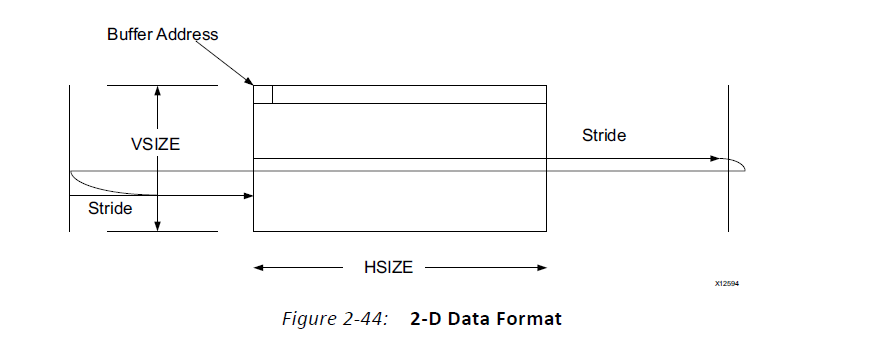
图6
如图7所示,Multichannel模式下,S2MM有16个通道,每个通道都有独立的CURDESC和TAILDESC寄存器,而CR和SR则是共用的。令人费解的是,从对称的角度来说,MM2S理应每个通道也要有独立的CURDESC和TAILDESC寄存器,但事实是多个通道共用一份。手册上的说法是:
MM2S is similar to normal AXI DMA operation. When MM2S_CURDESC and
MM2S_TAILDESC are programmed by software, AXI DMA fetches a chain of descriptors and
processes until it reaches tail descriptor. In AXI DMA, TDEST, TID, and TUSER fields are
assumed to remain constant for an entire packet as defined in the descriptors. That is, each
packet transfer across a logical channel defined by (TDEST, TID, TUSER) runs to completion
before the DMA transfers another packet. Although packet transfers for multiple channels
can be interleaved, after started, each must run to completion before another transfer can
occur. It is your responsibility to avoid deadlock scenarios under this assumption. The AXI
DMA does not signal error conditions if the (TDEST, TID, TUSER) fields within the descriptors
do not adhere to these assumptions. It is up to the software to maintain consistency.
从以上文字来看,MM2S端只能等当前包传输完才能开始下一次的传输,我猜测这与CPU不太容易同时操纵多个通道的数据包发送有关系。所以在实际使用时只能先执行一个通道的发送任务再执行另一个通道的发送任务,虽然很不爽,但是还是能用的。
不知道以上理解是否有误,如果哪位同学能提供更好的解释的话,请在评论区留言。
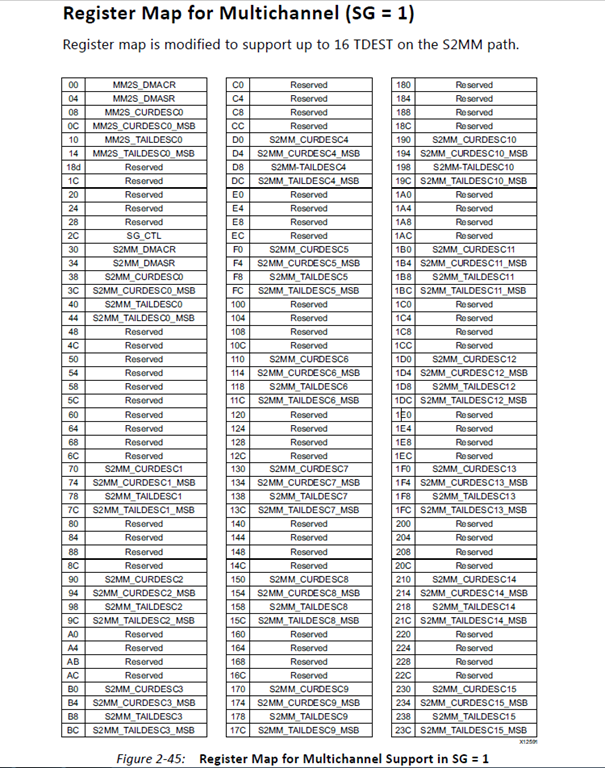
图7
Cyclic DMA:循环模式是在Scatter/Gather模式下的一种独特工作方式,在Multichannel Mode下不可用。正常情况下的Scatter/Gather模式在遇到Tail BD就应该结束当前的传输,但是如果使能了Cyclic模式的话,在遇到Tail BD时会忽略completed位,并且回到First BD,这一过程会一直持续直到遇到错误或者人为中止,图8比较形象地表示了这一过程。Cyclic模式只需要在开启传输前设置好BD链条,工作之后就再也不需要管了。要做到遇到Tail BD时返回到First BD,手册中提供的方法是:
In this setup the Tail BD points back to the first BD. The Tail Descriptor register does not
serve any purpose and is used only to trigger the DMA engine.
Program the Tail Descriptor register with some value which is not a part of the BD chain. Say
for example 0x50.
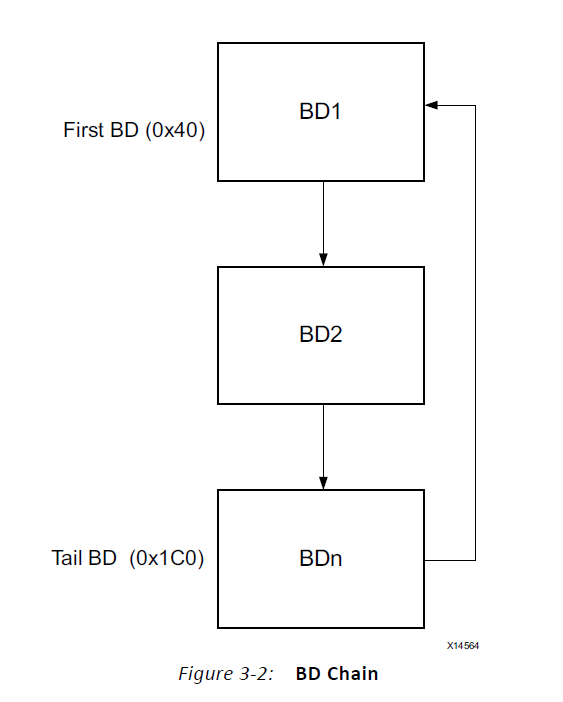
图8
Data Cache:从图9中可以看出,在ZYNQ内部ARM CPU与DDR3之间存在两级缓存区,分别是L1 I/D Cache和L2 Cache,它们都是32-byte line size。Data Cache的使用带来了一个问题,DMA和CPU都与DDR3有数据往来,可CPU的Cache是不知道DMA对DDR3的数据读写过程的,也就是说CPU得到的数据很可能是”假的“,这就是著名的Cache一致性问题。解决该问题的办法是在程序中使用flush函数(invalid函数)及时将Cache的数据写入到DDR3(从DDR3读取数据到Cache),也就是说要避免该问题就只能靠我们自己了。
图9

















 5744
5744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









