




 本文分析了拉勾网的反爬机制,详细介绍了如何使用Python通过GET和POST请求获取页面上的Python职位信息。核心思路在于利用session获取cookie,然后在POST请求中附带cookie以成功获取数据。同时提醒注意避免频繁请求导致IP被封,可采取设置请求间隔或使用代理IP的策略。
本文分析了拉勾网的反爬机制,详细介绍了如何使用Python通过GET和POST请求获取页面上的Python职位信息。核心思路在于利用session获取cookie,然后在POST请求中附带cookie以成功获取数据。同时提醒注意避免频繁请求导致IP被封,可采取设置请求间隔或使用代理IP的策略。
特别声明
众所周知,拉勾网的反爬机制更新较为频繁,本博客所分享的方法不一定永久有效,即具有时效性。研究该网站的反爬机制仅供交流学习,千万不要用于做违法的事情。
网站介绍
拉勾网是一个专业的互联网招聘平台,该网站上有很多公司的招聘信息,所以该网站也成了很多爬虫爬取的重点对象。
思路分析
本文我以Python为例进行思路分析,首先,在搜索框中输入关键字Python,并点击搜索
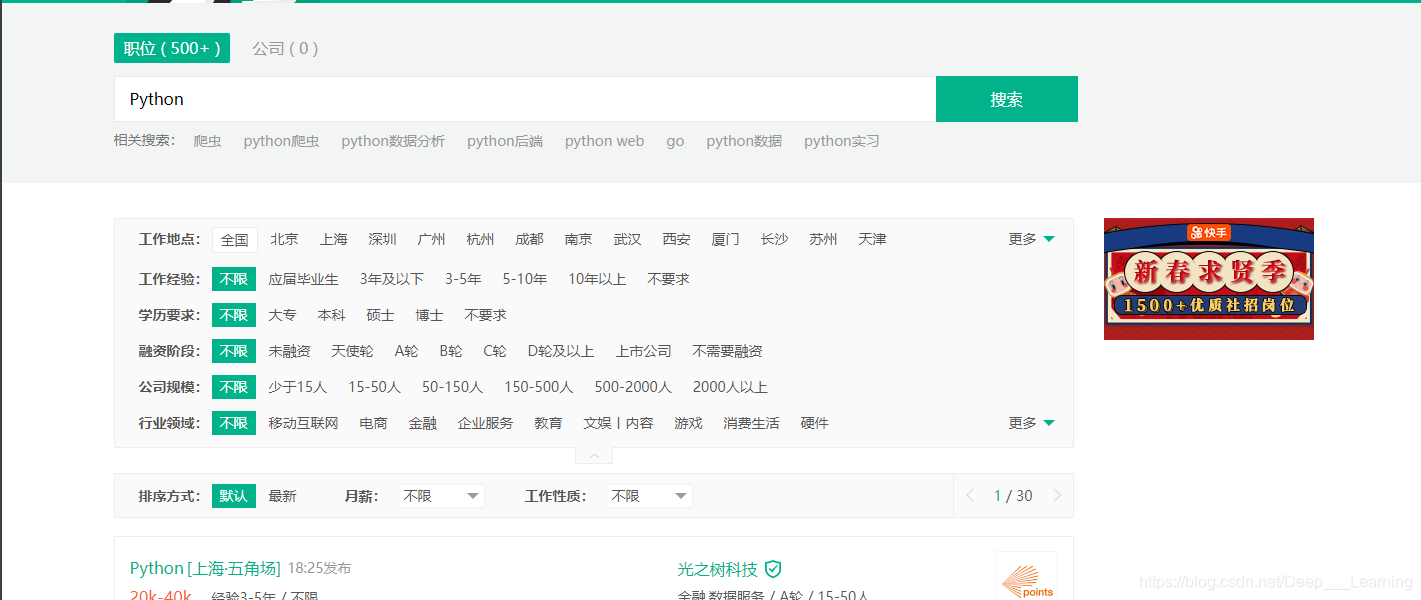
可以跳转到如上图所示的页面,我们要爬取的数据就是下面的职位信息
查看网页源代码,我们可以发现并没有我们想要的数据,由此可以判断数据通过其他的URL请求得到,下面进行抓包分析
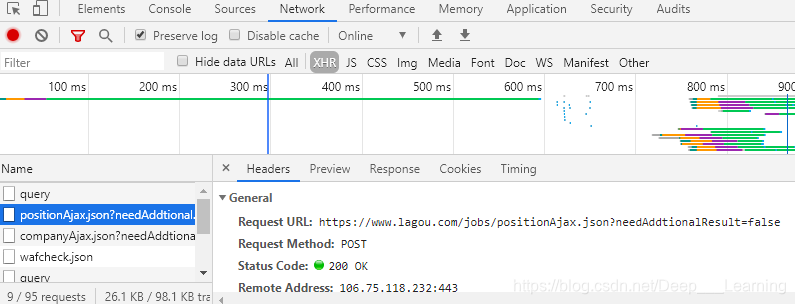
通过抓包,我们发现了请求的URL,请求方式为POST,但是,当我们直接用POST方式请求时,却不能获取到数据,直接给你返回“请求太频繁”(这个提示应该是假的),我尝试增加请求头中的信息,依旧没有用。后来,经过分析我知道了网站后台可能会判断你请求时的cookie,只有cookie正确,才给你返回信息,因此,我们的思路就很明确了,只要在请求之前拿到cookie,并且在请求时在加上cookie就行了。
核心思路:
为了能够拿到我们想要的职位信息,我们分两步走。
第一步,先用get的方式请求一开始的URL,即我们访问页面的URL,这一步的目的是为了能够得到cookie,为下一步请求做准备。
第一次请求的URL:https://www.lagou.com/jobs/list_Python?labelWords=&fromSearch=true&suginput=
第二步,我们用第一步拿到的cookie来发送POST请求,请求的URL为:
https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false
具体实现
首先,我们可以用requests库中的session方法来创建一个session对象来存储cookie,然后再用这个cookie进行第二步中的请求即可。
测试代码
# !/usr/bin/env python
# —*— coding: utf-8 —*— 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6125
6125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









