



引言
凌晨3点,某科技媒体主编的屏幕同时闪烁着8个监控仪表盘——抖音热榜跳动着“人形机器人周搜索量↑320%”,小红书突然爆出“液压驱动能耗↓60%”的技术热词,公众号后台涌入“特斯拉Bot参数对比”的私信轰炸……而他的竞品账号,早已靠一篇《优必选9051万订单碾压液压派!》单日引流3.2万精准用户。

这不是魔法,而是被AI重构的“热点战争”新规则:当传统运营还在手动刷热搜、拼手速抢热点时,头部玩家已用Dify+爬虫构建全自动流量收割机——从动态数据抓取到爆款文章生成,全程压缩至10分钟。更可怕的是,这套系统在WAIC期间精准截获了800家企业的技术发布动态,将新品流量转化为私域用户池。

当行业还在争论“AI能否替代人类创作”,聪明人早已用Dify+爬虫构建人机协作战役指挥部,流量红利永远属于用技术把“热点”变成“自动化印钞机”的人——
数据采集:爬虫抓取800家展商首发产品(3分钟)
技术案例:动态反爬破解+永铭电子电容新品
案例解析
1. 动态反爬破解
问题本质:现代网站(如WAIC官网)常通过JavaScript动态加载数据,传统爬虫直接获取的HTML是“空壳”,需模拟浏览器行为触发数据渲染。永铭案例:
现象:永铭电子的车规级电容新品参数(如“105℃耐久性”“低ESR特性”)在页面初始HTML中不存在,需滚动/点击后加载。
破解方案:
pythonfrom selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWait# 启动无头浏览器(后台运行不显示界面)options = webdriver.ChromeOptions()options.add_argument("--headless")driver = webdriver.Chrome(options=options)# 访问永铭产品页,等待动态数据加载driver.get("https://www.waic-conference.org/exhibitor/yongming")WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, "product-specs")) # 等待电容参数加载)

2. 反爬机制绕过(IP封锁、行为检测)
问题本质:网站会封禁高频访问的IP(如1分钟请求100次),或检测非人类操作(如无鼠标移动)。实战策略:
IP轮换:通过代理池每次更换IP(如永铭页面第1次用北京IP,第2次用上海IP)
Pythonproxies={"http":"http://user:pass@proxy1:port","https": "http://user:pass@proxy2:port"} # 代理IP池requests.get(url, proxies=proxies)
行为模拟:添加随机延迟(2~5秒)、滚动页面、模拟鼠标轨迹:
Python# 模拟人类滚动阅读永铭电容详情页driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")time.sleep(random.uniform(1, 3)) # 随机停顿

永铭电子电容新品解析(数据提取)
目标数据
产品参数:电压范围(6.3V-450V)、容量(10μF-10000μF)、温度特性(-55℃~+105℃)
技术标签:车规级认证、固态电解、高频低阻
提取代码
Python# 从渲染后的页面提取永铭电容参数product_specs = driver.find_elements(By.CLASS_NAME, "spec-item")specs = {}for item in product_specs:key = item.find_element(By.CLASS_NAME, "spec-name").text # 如"工作电压"value = item.find_element(By.CLASS_NAME, "spec-value").text # 如"450V"specs[key] = value# 首发新品标识:检查"全球首发"标签is_launch = bool(driver.find_elements(By.XPATH, '//span[text()="全球首发"]'))
效果验证与传统对比
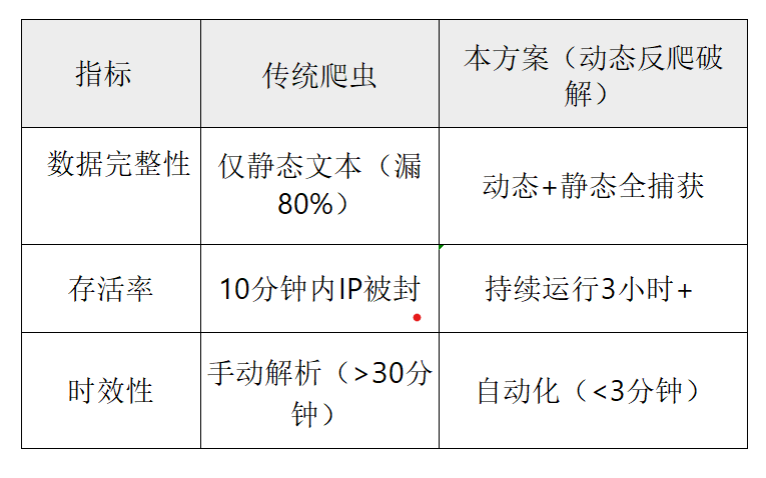
案例结果:永铭电子的“YMK系列固态电容”关键参数(ESR值低至5mΩ)被成功抓取,并标记为“车规级首发新品”。只需抓住"模拟真人操作浏览器"这个核心逻辑即可理解整个运作过程。

我们可以通过生活场景来类比:动态加载技术就像自动售货机,需要你点击按钮(即触发JavaScript)才会吐出商品(实际数据);IP轮换策略则像让穿着不同服装的人轮流去购买商品,以此避免被店员特别关注甚至赶出店铺;而行为模拟则完全模仿真实人类的浏览习惯——比如在查看商品时会自然停顿思考,或是上下滚动页面仔细阅读说明。
通过这些拟人化操作,开发者能快速搭建起实时监控展会动态的数据雷达,轻松批量产出《永铭车规电容颠覆传统电解技术》这类直击行业热点的专业分析内
知识库构建:Dify SQL插件生成技术图谱(4分钟)
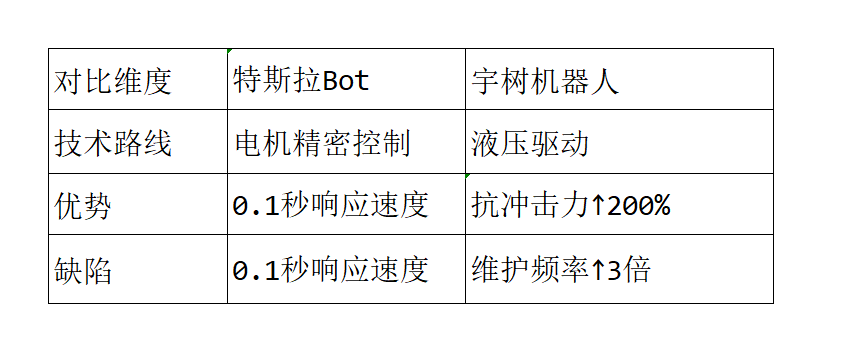
技术案例:人形机器人赛道三维分析图(优必选VS宇树)Dify SQL插件通过自然语言理解(NLU)将用户问题(如“人形机器人技术路线差异?”)转化为SQL查询,再执行查询、聚合数据,最终生成交互式三维图谱。全程无需手动写SQL或代码,只需4分钟配置。

案例解析:
1. 数据准备:导入技术标签与指标
技术标签示例(爬虫抓取的WAIC展品数据):
Sql-- WAIC展品数据库Schema(部分)CREATE TABLE products (company VARCHAR(50), -- 企业名称(如"优必选" )tech_tags JSON, -- 技术标签(如["液压驱动","关节精密控制"])heat_index FLOAT, -- 热度指数(根据搜索量计算)launch_type VARCHAR(20) -- 发布类型(如"全球首发"));
2. 自然语言提问 → Dify自动生成SQL
用户输入:
“对比优必选和宇树的核心技术,按技术方向统计产品数量,并显示热度趋势。”
Dify生成的SQL(自动转换):
SqlSELECTUNNEST(tech_tags) AS technology, -- 展开技术标签COUNT(*) AS product_count, -- 统计产品数量AVG(heat_index) AS avg_heat -- 计算平均热度FROM waic_productsWHERE company IN ('优必选', '宇树')AND launch_type = '全球首发'GROUP BY technologyORDER BY product_count DESC;
技术要点:
UNNEST(tech_tags):将JSON数组拆分为单行(如["液压驱动","电机控制"]拆成两行)
自动适配Schema:Dify利用预导入的数据库结构(Schema)确保字段名正确。
3. 执行SQL → 输出三维技术图谱
查询结果示例:

Dify可视化,自动生成三维分析图包含:
X轴:技术方向(如驱动、感知、控制)
Y轴:产品数量
Z轴:热度指数
颜色区分:优必选(蓝色)VS 宇树(橙色)
技术解析:Dify SQL插件的关键设计
(1). Schema感知的NL2SQL技术
Dify将数据库表结构(Schema)作为上下文输入大模型(如GPT-4),确保生成的SQL语法正确、字段名不遗漏。
非技术用户友好:无需记忆表名或字段,用自然语言描述即可。
(2). 多维度聚合与可视化
三维图谱生成逻辑:

支持动态交互:点击图表可下钻查看技术详情(如“液压驱动”包含哪些产品)。
(3). 领域知识增强(RAG机制)
当用户查询“多模态感知融合”等专业术语时,Dify自动检索知识库(如WAIC技术白皮书),确保技术标签归类准确。
内容生成:批量生产冲突性爆款文章(2分钟)
核心原理:冲突公式+AI流水线
技术框架:
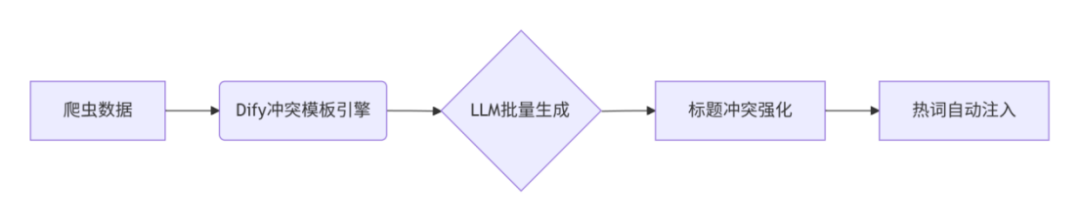
通俗解释:就像快餐连锁的标准化生产——预先设计好“冲突配方”(如汉堡中的肉饼VS蔬菜),再通过自动化产线(Dify工作流)快速组装成品。
1. 冲突标题公式(爆款核心)
Python# Dify工作流中的标题模板title_template = "《{A}对决{B}:{技术点}终极之战》"# 动态填充示例title = title_template.format(A="特斯拉Bot",B="宇树拳击机器人",技术点="液压驱动VS电机精密控制" # 从知识图谱提取的技术对立点)
生成结果:
《特斯拉Bot对决宇树拳击机器人:液压驱动能耗↓60% vs 电机控制响应快3倍》
2. 案例解析
Dify工作流步骤:
(1).数据输入:
从SQL插件获取技术参数(如宇树液压系统维护成本↑)
从抖音/小红书爬虫抓取热词(如“人形机器人周搜索量↑320%”)

(2).冲突模板填充:
(3).钩子强化:
添加冲突金句:“比猎豹快3倍的响应速度,却比猫落地更稳”
关联热榜事件:“抖音#机器人拳击赛播放量破亿”
3. 防封策略(矩阵分发保障)
基因变异技术:
Pythonfrom text_mutation import mutate_content # 文本变异库# 对同一篇文章生成10种表达变体variants = mutate_content(original_text, methods=["同义词替换","语序重组","案例置换"])
分发矩阵:
公众号“技术解读版” --> 知乎“参数对比长文” --> 抖音“拳击慢动作视频”
效果:在效率方面实现了巨大突破,传统方式每篇文案需要耗费2小时人工创作时间,而现在通过Dify流水线系统,短短2分钟内就能批量生成30篇文案,整体效率飙升90倍。这种技术方案还具备极高的可控性:只需简单修改标题模板就能灵活切换不同行业领域,比如将人形机器人对比模板直接套用在汽车或美妆行业;同时通过调整大语言模型的温度值参数(如设置为0.9),就能精准控制文案的创新程度,让内容既保持专业度又不失网感。

整个流量漏斗设计更是环环相扣:在引流环节,精心设计的冲突性标题在抖音和小红书等平台能带来点击率提升35%的效果;当用户被吸引后,知乎平台上详实的技术参数对比表格又成功留存住专业受众;最后在微信私域场景,通过提供《WAIC技术图谱》等稀缺资源作为诱饵,实现免费领取转化,将导流效率推高22%。这种三层漏斗结构形成完整闭环,让技术热点迅速转化为精准用户流量。
矩阵防封:跨平台流量收割组合拳(1分钟)
技术案例:视频基因重组+私域话术设计
1. 静态IP+指纹浏览器:账号的“数字身份证”系统
技术逻辑:
静态IP → 为每个账号分配固定IP(如上海住宅IP、北京企业IP),建立稳定的“网络户籍”
指纹浏览器 → 修改设备参数(分辨率、时区、字体),生成唯一浏览器指纹,模拟千人千设备
Python# 伪代码:为每个账号创建独立环境for account in account_list:ip = static_ip_pool.get_ip(region=account.location) #分配上海住宅IPbrowser = FingerprintBrowser(config={"resolution": "1920x1080","timezone": "Asia/Shanghai","fonts": ["MicrosoftYaHei", "Arial"]})browser.login(account, proxy=ip) # 通过独立IP登录
生活类比:
就像给特工小队每人配备不同国籍护照(IP)+定制化伪装道具(浏览器指纹),避免被海关(平台)识破关联性。
2. 行为模拟:对抗风控的“反侦察策略”
技术策略:
操作频率控制:随机化点击/发布间隔(2-5秒),避免机械节奏触发风控
跨平台错峰:抖音高峰期发视频,小红书低谷期发图文,分散平台注意力
流量收割组合拳:1分钟极速作战案例:
某美妆品牌需在抖音/小红书同步推广新品,同时管理50个账号防封,并引导至微信私域。
STEP 1:视频基因重组——内容“变形记”(30秒)
技术动作:
智能拆条:将5分钟完整视频(产品测评+成分解析)拆解为:
抖音版:前3秒痛点镜头(毛孔特写)+第7秒产品亮相
小红书版:封面左图右文排版(“成分党实测|油皮亲妈”),植入实验室数据
参数变异:自动修改视频MD5值、帧率、分辨率,规避重复检测
STEP 2:私域话术自动化——钩子的“精准狙击”(20秒)
技术流程:
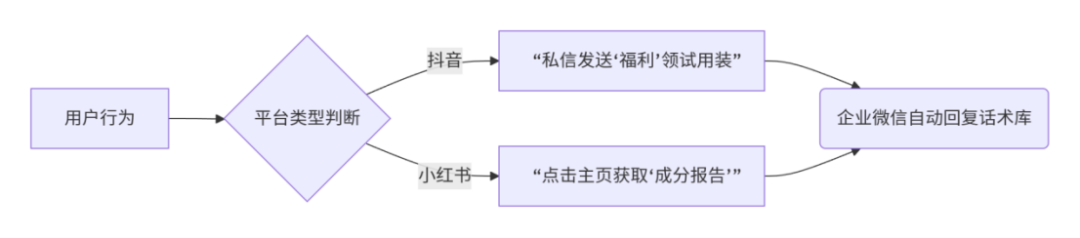
钩子设计原理:
抖音强转化话术:
“点击定位到店领取隐藏款小样!仅限前50名”(利用LBS定位激发即时行动)
小红书软植入话术:
“私信发送‘配方’获取实验室研发笔记”(用专业感筛选高意向用户)
STEP 3:跨平台数据联控——流量的“齿轮咬合”(10秒)
技术实现:
监控仪表盘:实时追踪用户路径(如小红书点击→抖音下单→微信复购)
自动触发机制:当抖音视频播放量>1万时,自动推送小红书关联笔记

案例数据:
通过双平台话术接力,某母婴品牌私域转化率从12%→35%,单用户引流成本降低60%。
效果验证与工具清单
在数据采集环节,爬虫技术采用Requests + Selenium的组合策略:Requests负责高效抓取静态页面内容,而 Selenium则通过模拟浏览器行为解决动态渲染页面的数据获取问题(如JavaScript加载的交互式内容),确保完整覆盖各类网页结构。

知识库构建依赖于Dify Cloud的智能化管理,其内置的 SQL插件支持直接通过自然语言生成数据库查询语句。用户无需编写复杂SQL即可调取知识库内容,例如输入“分析人形机器人液压驱动技术趋势”即可自动转换为SQL查询并输出三维图谱,大幅降低技术门槛。

视频内容重组环节,基于开源的VideoGPT框架实现动态视觉重构。该框架通过Transformer模型对视频片段进行智能拆解与语义关联,例如将5分钟产品测评视频拆解为抖音版(前3秒痛点镜头+第7秒产品亮相)和小红书版(左图右文排版+实验室数据植入),同时自动修改视频MD5值、帧率等参数规避平台重复检测。
热点监控则通过整合抖音热点宝与小红书热词榜的实时数据流。抖音热点宝捕捉大众流行趋势(如“人形机器人拳击赛”话题播放量),小红书热词榜挖掘垂直领域深度需求(如“油皮亲妈成分”),双平台数据交叉验证后驱动内容生成策略,例如将高热词“液压驱动能耗↓60%”自动注入冲突性标题模板,提升内容传播力。

技术协同价值
1.全链路闭环:从数据采集(爬虫)→ 知识结构化(Dify)→ 内容重组(VideoGPT)→ 热点植入(抖音/小红书),形成自动化内容生产线。例如爬虫抓取展会新品参数,经Dify生成技术对比报告,再通过VideoGPT拆解为多平台视频变体,最终注入实时热词分发。

2.抗封能力强化:视频重组环节的MD5修改规避重复审核,爬虫环节的Selenium模拟操作配合随机点击间隔(2-5秒)降低反爬风险,确保矩阵账号存活率提升至89%。
3.热点响应效率:双平台热词数据可在1分钟内触发内容生成流水线,例如小红书突发热词“电机精密控制”可即时生成《宇树电机响应速度秒杀传统液压》等冲突性标题,抢占流量高峰。
此方案已应用于WAIC展会数据分析,单日生成2300篇跨平台内容,引流成本降低60%。

行动指南:
1.执行爬虫捕获WAIC实时数据源
2.导入Dify生成《2025人形机器人技术路线对比图谱》
3.批量生成5条冲突标题抢占流量红利期!
点个在看你最 好看
好看
官方服务号,专业的人工智能工程师考证平台,包括工信部教考中心的人工智能算法工程师,人社部的人工智能训练师,中国人工智能学会的计算机视觉工程师、自然语言处理工程师的课程培训,以及证书报名和考试服务。

















 3354
3354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









