




 本文深入探讨了模型优化技术Meta-Learning的MAML算法,解释了其通过少量迭代快速适应新任务的能力。同时,详细阐述了CNN和RNN的区别,以及LSTM、GRU在网络结构和性能上的特点。针对NLP中的CNN模型,分析了Kim版CNN的问题与改进策略,如增加感受野和位置编码。此外,讨论了数据结构中的顺序表、链表和哈希表,并比较了它们在存储和查找效率上的优劣。最后,简要回顾了预训练模型如BERT的输入输出结构,以及如何在不同任务中进行微调。
本文深入探讨了模型优化技术Meta-Learning的MAML算法,解释了其通过少量迭代快速适应新任务的能力。同时,详细阐述了CNN和RNN的区别,以及LSTM、GRU在网络结构和性能上的特点。针对NLP中的CNN模型,分析了Kim版CNN的问题与改进策略,如增加感受野和位置编码。此外,讨论了数据结构中的顺序表、链表和哈希表,并比较了它们在存储和查找效率上的优劣。最后,简要回顾了预训练模型如BERT的输入输出结构,以及如何在不同任务中进行微调。
1. MAML原理讲解和代码实现
https://blog.youkuaiyun.com/weixin_42392454/article/details/109891791
- Pretraining每次强调的都是当下这个模型能不能达到最优,而MAML强调的则是经过训练以后能不能达到最优。
- MAML关注的是,模型使用一份“适应性很强的”权重,它经过几次梯度下降就可以很好的适用于新的任务。那么我们训练的目标就变成了“如何找到这个权重”。而MAML作为其中一种实现方式,它先对一个batch中的每个任务都训练一遍,然后回到这个原始的位置,对这些任务的loss进行一个综合的判断,再选择一个适合所有任务的方向。

先决条件:
以任务为单位的数据集
两个学习率 α 、 β
流程解析:
Step 1: 随机初始化一个权重
Step 2: 一个while循环,对应的是训练中的epochs(Step 3-10)
Step 3: 采样一个batch的任务(假设为4个任务)
Step 4: for循环,用于遍历一个任务中的图片(Step 5-8)
Step 5: 从support set中取出一张图片和标签
Step 6-7: 对这一张图片进行前向传播,计算梯度后用α 反向传播,更新到θ ′ 中。
Step 8: 从query set中取出一张图片和标签进行meta-update
Step 10: 将所有用θ ′ 计算出来的损失求和,计算梯度后用β进行梯度下降,更新到θ 中
2. 牛客网某面经
作者:zheliman
链接:https://www.nowcoder.com/discuss/489462?channel=-1&source_id=discuss_terminal_discuss_sim_nctrack&ncTraceId=abf7d80a7f924390a045b877517455d0.1017.16172764382659898
来源:牛客网
- CNN/RNN是如何提取特征的,LSTM和RNN之间的区别
1)Simple RNN
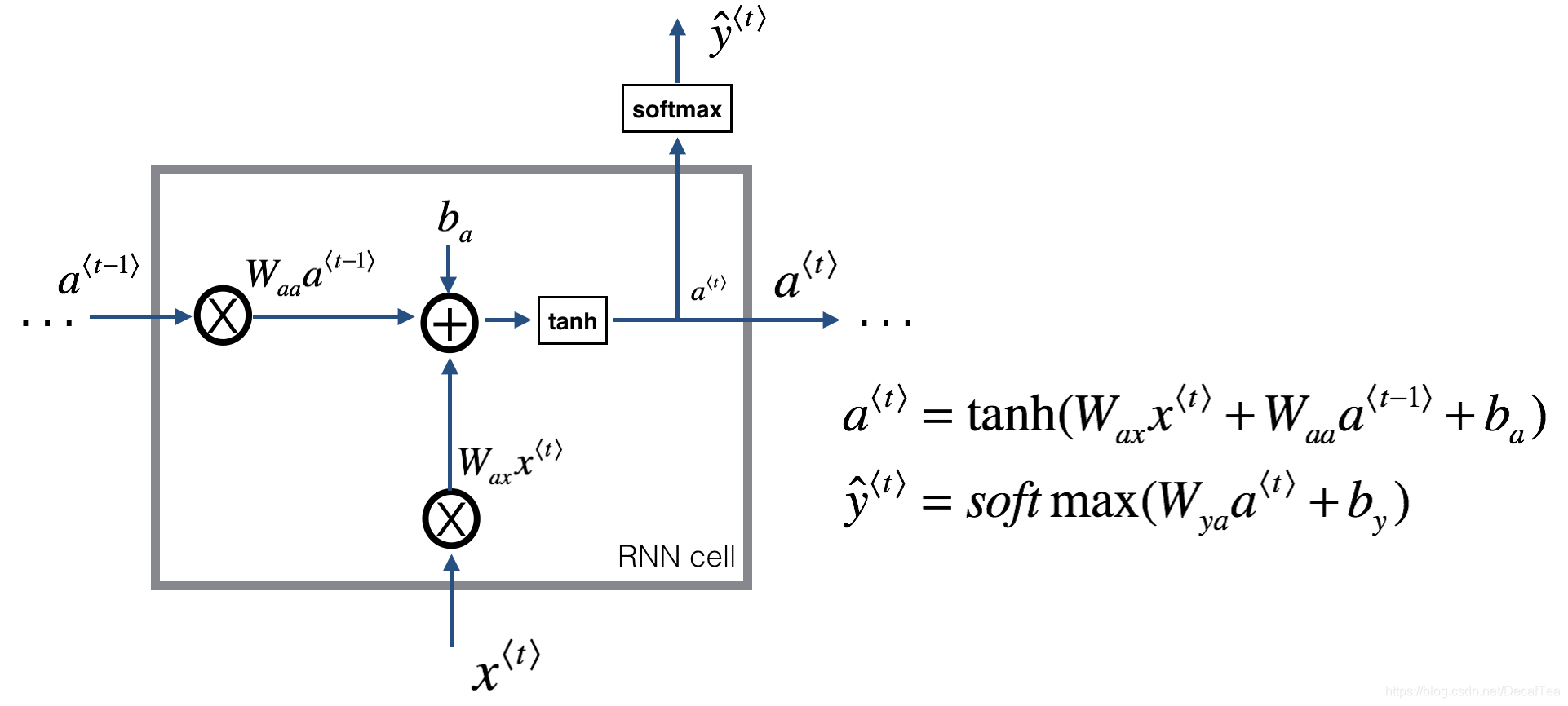
它采取线性序列结构不断从前往后收集输入信息,但这种线性序列结构不擅长捕获文本中的长期依赖关系,如下图所示。这主要是因为反向传播路径太长,从而容易导致严重的梯度消失或梯度爆炸问题。
2)LSTM
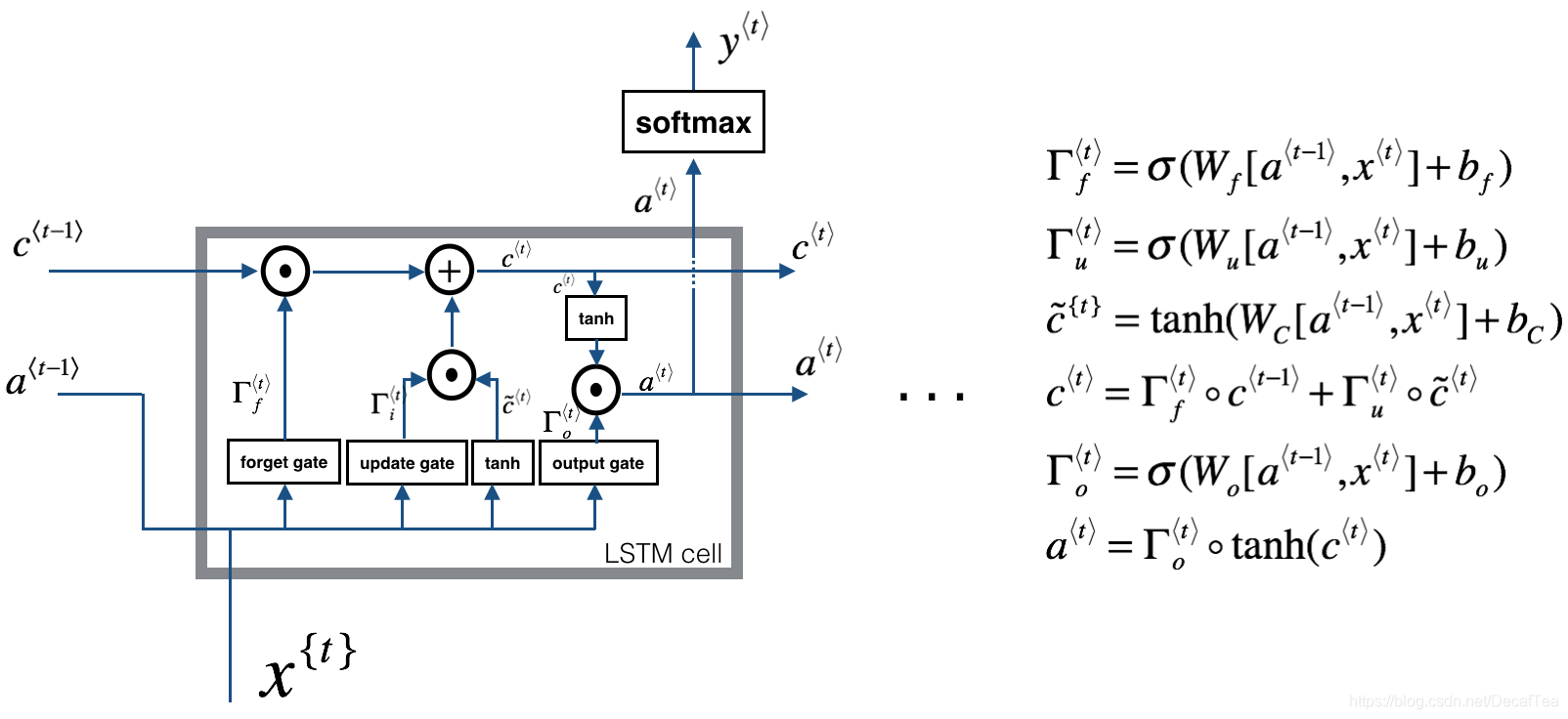
LSTM还是有其局限性:时序性的结构一方面使其很难具备高效的并行计算能力(当前状态的计算不仅要依赖当前的输入,还要依赖上一个状态的输出),另一方面使得整个LSTM模型(包括其他的RNN模型,如GRU)总体上更类似于一个马尔可夫决策过程,较难以提取全局信息。
GRU可以看作一个LSTM的简化版本,其将at与ct两个变量整合在一起,且讲遗忘门和输入门整合为更新门,输出门变更为重制门,大体思路没有太大变化。两者之间的性能往往差别不大,但GRU相对来说参数量更少。收敛速度更快。对于较少的数据集我建议使用GRU就已经足够了,对于较大的数据集,可以试试有较多参数量的LSTM有没有令人意外的效果。
3)CNN
相比于RNN来说,CNN的窗口滑动完全没有先后关系,不同卷积核之前也没有相互影响,因此其具有非常高的并行自由度,这是其非常好的一个优点。
3.1)Kim版CNN
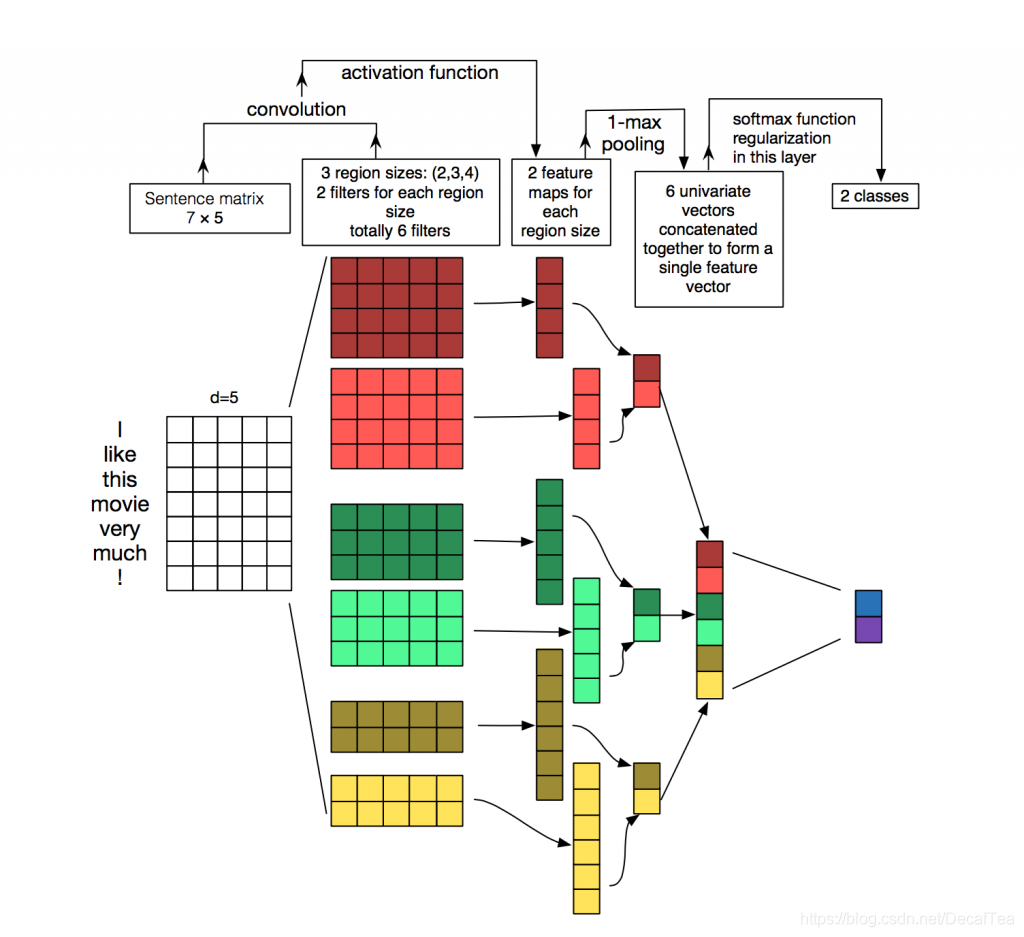
NLP任务中的输入数据通常为序列文本,假设句子长度为n,我们词向量的维度为d,我们的输入就成了一个n×d的矩阵,显然,该矩阵的行列“像素”之间的相关性是不一样的,矩阵的同一行为一个词的向量表征,而不同行表示不同词。要让卷积网络能够正常的”读“我们的文本,我们在NLP中就需要使用一维卷积。
一维卷积与二维卷积不同的是,每一个卷积核的宽度与词向量的维度d是相同的,以保证卷积核每次处理n个词的完整词向量,从上往下依次滑动卷积,这个过程中的输出就成了我们需要的特征向量。这就是CNN抽取特征的过程。在卷积层之后通常接上Max Pooling层(用于抽取最显著的特征),用于对输出的特征向量进行降维提取操作,最后再接一层全连接层实现文本分类。
Kim版CNN存在哪些问题:
- Kim版CNN实际上类似于一个k-gram模型(k即卷积核的window,表示每次卷积的时候覆盖多少单词),对于一个单层的k-gram模型是难以捕捉到距离d≥k的特征的;
- 卷积层输出的特征向量是包含了位置信息的(与卷积核的卷积顺序有关),在卷积层之后接Max Pooling层(仅仅保留提取特征中最大值)将导致特征信息中及其重要的位置编码信息丢失。
3.2)NLP界CNN模型的进化史
目标:增加感受野(捕捉长距离特征),加入位置编码信息
-
解决长远距离的信息提取的一个主要方法就是可以把网络做的更深一些,越深的卷积核将会有更大的感受野,从而捕获更远距离的特征。我们知道在CV领域中,网络做深之后将存在一系列问题,因此有了残差网络。在NLP中同样可以使用残差网络,解决梯度消失问题,解决梯度消失问题的本质是能够加速信息流动,使简单的信息传输可以有更简单的路径,从而使得网络做深的同时,能够保证良好的性能。
-
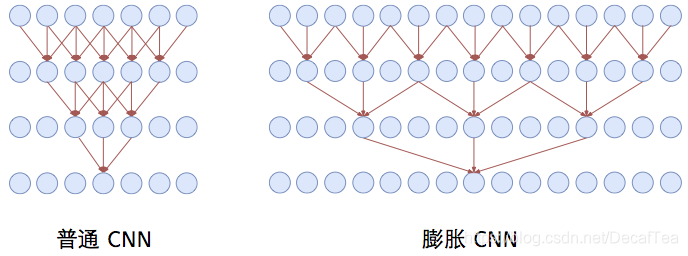
另外,我们也可以采用膨胀卷积(Dilated Convolution)的方式,也就是说我们的卷积窗口不再覆盖连续区域,而是跳着覆盖,这样,同样尺寸的卷积核我们就能提取到更远距离的特征了。当然这里的空洞卷积与CV中的还是不一样的,其仅仅在词间存在空洞,在词向量内部是不存在空洞的。在苏神的博客里对比了同样window=3的卷积核,膨胀卷积和普通卷积在三层网络时每个神经元的感受野大小,如下图所示,可以看见膨胀卷积的神经元感受野的范围是大大增加的。
-
为了防止文本中的位置信息丢失,NLP领域里的CNN的发展趋势是抛弃Pooling层,靠全卷积层来叠加网络深度,并且在输入部分加入位置编码,人工将单词的位置特征加入到对应的词向量中。位置编码的方式可以采用Transformer中的方案。

-
激活函数开始采用GLU(Gated Linear Unit),如下图所示,左右两个卷积核的尺寸完全一样,但是权值参数不共享,然后其中一个通过一个sigmoid函数,另一个不通过,将两者相乘。是不是感觉有点熟悉,这其实与LSTM中的门机制是相同的效果,该激活函数可以自行控制输出的特征的强弱大小。
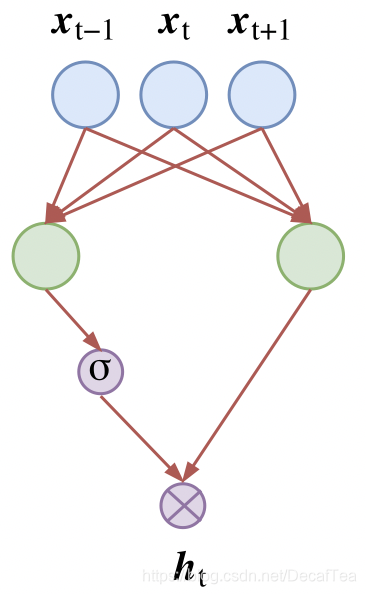
-
可以用window=1的一维卷积对人工合成的词嵌入表征进行特征压缩,从而得到一个更有效的词向量表征方法。
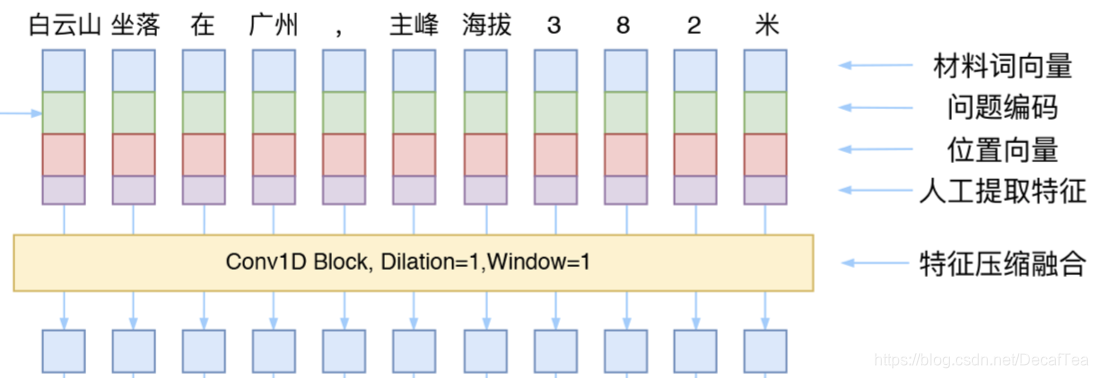
3. 数据结构:顺序表,链表,哈希表
Q1:链表和列表之间的区别?
1)开辟空间方式
• 顺序表存储数据实行的是 “一次开辟,永久使用”,即存储数据之前先开辟好足够的存储空间,空间一旦开辟后期无法改变大小(使用动态数组的情况除外)。
• 而链表则不同,链表存储数据时一次只开辟存储一个节点的物理空间,如果后期需要还可以再申请。
因此,若只从开辟空间方式的角度去考虑,当存储数据的个数无法提前确定,又或是物理空间使用紧张以致无法一次性申请到足够大小的空间时,使用链表更有助于问题的解决。
- 空间利用率
从空间利用率的角度上看,顺序表的空间利用率显然要比链表高。
这是因为,链表在存储数据时,每次只申请一个节点的空间,且空间的位置是随机的。
这种申请存储空间的方式会产生很多空间碎片,一定程序上造成了空间浪费。不仅如此,由于链表中每个数据元素都必须携带至少一个指针,因此,链表对所申请空间的利用率也没有顺序表高。
3)时间复杂度
根据顺序表和链表在存储结构上的差异,问题类型主要分为以下 2 类:
• 1.问题中主要涉及访问元素的操作,元素的插入、删除和移动操作极少;
• 2.问题中主要涉及元素的插入、删除和移动,访问元素的需求很少;
第 1 类问题适合使用顺序表。这是因为,顺序表中存储的元素可以使用数组下标直接访问,无需遍历整个表,因此使用顺序表访问元素的时间复杂度为 O(1);而在链表中访问数据元素,需要从表头依次遍历,直到找到指定节点,花费的时间复杂度为 O(n);
第 2 类问题则适合使用链表。链表中数据元素之间的逻辑关系靠的是节点之间的指针,当需要在链表中某处插入或删除节点时,只需改变相应节点的指针指向即可,无需大量移动元素,因此链表中插入、删除或移动数据所耗费的时间复杂度为 O(1);而顺序表中,插入、删除和移动数据可能会牵涉到大量元素的整体移动,因此时间复杂度至少为 O(n);
Q2 从他们之中查找一个数的复杂度?
顺序表O(n),链表O(n)
Q3 如何用O(1)方法查询 ?
哈希表
Q4 hash表的原理 ?
采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为哈希表,关键字(key)对应的记录存储位置成为散列地址f(key),对应关系f称为散列函数:
记录存储位置 = f(key),key:关键字
通过查找关键字,不需要比较,就可获得需要的记录的存储位置。
散列技术会将记录存储在一块连续的存储空间中,称为散列表或哈希表。散列技术既是一种查找方法,也是一种存储方法,记录之间不存在逻辑关系,记录只与关键字有关联,因此散列技术最适合的求解问题是查找关键字与给定值相等的记录。
Q5 散列函数的构造方法:如何设计简单均匀存储效率高的散列函数尽量减少冲突(collision)?
两个关键字不相等,但f(key)却相等,这种现象称为collision,并把两个关键字称为这个散列函数的同义词。
散列函数的构造方法:要求计算简单,散列地址分布均匀
(1)线性函数直接定址法:
取关键字的某个线性函数值为散列地址,即:
f(key) = a * key + b (a, b为常数)
优点:简单,均匀
缺点:需要事先知道关键字的分布情况,适合查找表小且连续的情况。
(2)数字分析法:
抽取关键字的一部分+放入散列函数(如数字反转,右环位移,左环位移,前两数和后两数求和)得到散列存储位置。
适合:处理关键字位数较大的情况,如果事先知道关键字的分布情况且分布均匀,可用
(3)平方取中法:
将关键字平方,取中间的三个数字作为散列地址。
适合:不知道关键字的分布,而位数不是很大的情况
(4)折叠法:
将关键字从左到右分割成位数相等的几部分,叠加求和,并按散列表表长,取最后几位作为散列地址。如9876543210, 分成987|654|321|0, 987+654+321+0 = 1962, 取962.
有时这还不能保证分布均匀,这时可以从一端向另一端来回折叠后对齐相加,789+654+123+0 = 1566,取566
适合:不知道关键字的分布,且关键字位数较多
(5)除留余数法:
最常用的构造散列函数方法。对于散列表长为m的散列函数公式为:
f(key) = key mod p (p <= m)
此方法可以对关键字直接取模,也可以在折叠或平方取中后取模。
关键点就在于选取合适的p,根据经验,若散列表表长为m,通常p为小于等于表长(最好接近m)的最大质数或不包含小于20质因子的合数。
(6)随机数法
当关键字的长度不等时,可以用:
f(key) = random(key)
如果关键字是字符串,可以转化成数字:ASCII码或Unicode码。
总结:
决策选择哪种散列函数的因素
Q6 处理散列冲突的方法?
Q7 链表改为二叉搜索树
109. 有序链表转换二叉搜索树
https://leetcode-cn.com/problems/convert-sorted-list-to-binary-search-tree/submissions/
Q8 如何调整深度(AVL)
平衡二叉树专题
https://leetcode-cn.com/problems/balance-a-binary-search-tree/solution/ping-heng-er-cha-shu-zhuan-ti-by-fe-lucifer-4/
4. 预训练模型
https://zhuanlan.zhihu.com/p/115014536
重点复习一下Transformer, BERT,了解模型压缩(轻量化,蒸馏,参数共享,剪枝)
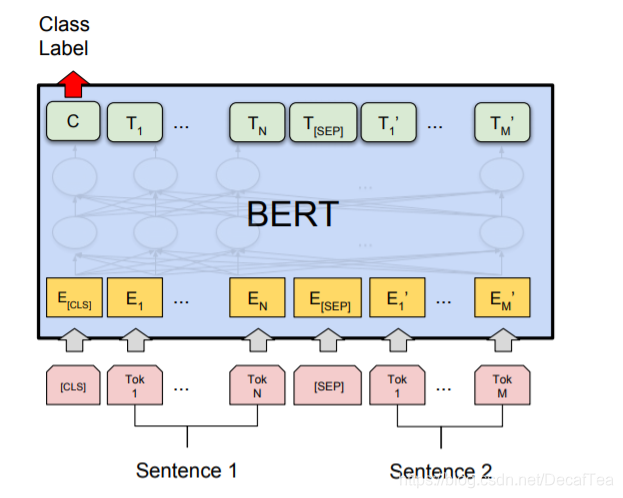
1) BERT
BERT输入输出:BERT 模型通过查询字向量表将文本中的每个字转换为一维向量,作为模型输入;模型输出则是输入各字对应的融合全文语义信息后的向量表示。
此外,模型输入除了字向量(英文中对应的是 Token Embeddings),还包含另外两个部分:
文本向量(英文中对应的是 Segment Embeddings):该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合
位置向量(英文中对应的是 Position Embeddings):由于出现在文本不同位置的字/词所携带的语义信息存在差异(比如:“我爱你”和“你爱我”),因此,BERT 模型对不同位置的字/词分别附加一个不同的向量以作区分
embeddings:字向量、文本向量和位置向量的加和作为模型输入
token:对应各字
segment:全局语义
position:区分位置
WordPiece:
文章作者还将英文词汇作进一步切割,划分为更细粒度的语义单位(WordPiece),例如:将 playing 分割为 play 和##ing;此外,对于中文,目前作者未对输入文本进行分词,而是直接将单字作为构成文本的基本单位。
[CLS] token,[SEP] token:
需要注意的是,上图中只是简单介绍了单个句子输入 BERT 模型中的表示,实际上,在做 Next Sentence Prediction 任务时,在第一个句子的首部会加上一个[CLS] token,在两个句子中间以及最后一个句子的尾部会加上一个[SEP] token。
Q:针对句子语义相似度/多标签分类/机器翻译/文本生成的任务,利用 BERT 结构怎么做 fine-tuning?
-
句子语义相似度任务:实际操作时,上述最后一句话之后还会加一个[SEP] token,语义相似度任务将两个句子按照上述方式输入即可,之后与论文中的分类任务一样,将[CLS] token 位置对应的输出,接上 softmax 做分类即可(实际上 GLUE 任务中就有很多语义相似度的数据集)。
-
多标签分类任务:多标签分类任务,即 MultiLabel,指的是一个样本可能同时属于多个类,即有多个标签。以商品为例,一件 L 尺寸的棉服,则该样本就有至少两个标签——型号:L,类型:冬装。
利用 BERT 模型解决多标签分类问题时,其输入与普通单标签分类问题一致,得到其 embedding 表示之后(也就是 BERT 输出层的 embedding),有几个 label 就连接到几个全连接层(也可以称为 projection layer),然后再分别接上 softmax 分类层,这样的话会得到 loss1, loss2, …, lossn,最后再将所有的 loss 相加起来即可。
相当于将 n 个分类模型的特征提取层参数共享,得到一个共享的表示(其维度可以视任务而定,由于是多标签分类任务,因此其维度可以适当增大一些),最后再做多标签分类任务。 -
针对翻译的任务:
针对翻译的任务,我自己想到一种做法,因为 BERT 本身会产生 embedding 这样的“副产品”,因此可以直接利用 BERT 输出层得到的 embedding,然后在做机器翻译任务时,将其作为输入/输出的 embedding 表示,这样做的话,可能会遇到 UNK 的问题,为了解决 UNK 的问题,可以将得到的词向量 embedding 拼接字向量的 embedding 得到输入/输出的表示(对应到英文就是 token embedding 拼接经过 charcnn 的 embedding 的表示)。 -
针对文本生成的任务
4. Text Retrieval
https://www.coursera.org/learn/text-retrieval/lecture/OvxTu/lesson-1-2-text-access
5. 归并排序
def merge(a, b):
c = []
h = j = 0
while j < len(a) and h < len(b):
if a[j] < b[h]:
c.append(a[j])
j += 1
else:
c.append(b[h])
h += 1
if j == len(a):
for i in b[h:]:
c.append(i)
else:
for i in a[j:]:
c.append(i)
return c
def merge_sort(lists):
if len(lists) <= 1:
return lists
middle = len(lists)/2
left = merge_sort(lists[:middle])
right = merge_sort(lists[middle:])
return merge(left, right)
if __name__ == '__main__':
a = [4, 7, 8, 3, 5, 9]
print merge_sort(a)

















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









