




baseline: BiLSTM+CRF or BERT+BiLSTM+CRF
1)模型之外,如何提升标注效果?
在垂直领域,一个不断积累、不断完善的实体词典对NER性能的提升是稳健的,基于规则+词典也可以快速应急处理一些badcase;
对于通⽤领域,可以多种分词工具和多种句法短语⼯具进行融合来提取候选实体,并结合词典进行NER;
此外,怎么更好地将实体词典融入到NER模型中,也是一个值得探索的问题(如嵌入到图神经网络中提取特征[3])。
2)如何在模型层面提升NER性能?
NER是一个重底层的任务,我们应该集中精力在embedding层下功夫,引入丰富的特征。
比如char、bigram、词典特征、词性特征、elmo等等,还有更多业务相关的特征;在垂直领域,如果可以预训练一个领域相关的字向量&语言模型,那是最好不过的了~总之,底层的特征越丰富、差异化越大越好(构造不同视角下的特征)。
如:
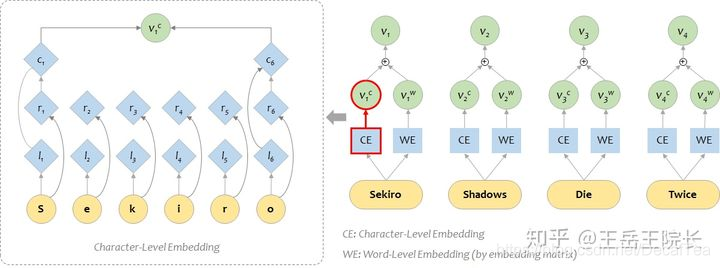
提取字符级别特征character embedding:
下图是使用Bi-LSTM提取字符级别的特征。对于某个单词wi(例如CAT),w=[c1,…,cp],每个字符ci都有一个向量化表示。使用Bi-LSTM建模单词字符词向量序列,并将Bi-LSTM最后输出的隐藏层h1、h2向量(前向、后向各一个)连接起来,作为该词wi字符级别的特征,该特征能够捕获wi形态学特点。
在英文 NLP 任务中,想要把字级别特征加入到词级别特征上去,一般是这样:单独用一个BiLSTM 作为 character-level 的编码器,把单词的各个字拆开,送进 LSTM 得到向量 vc;然后和原本 word-level 的(经过 embedding matrix 得到的)的向量 vw 加在一起,就能得到融合两种特征的表征向量。如图所示:
3)如何构建引入词汇信息(词向量)的NER?
我们知道
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









