




【JVM】内存结构
文章目录
1. 程序计数器
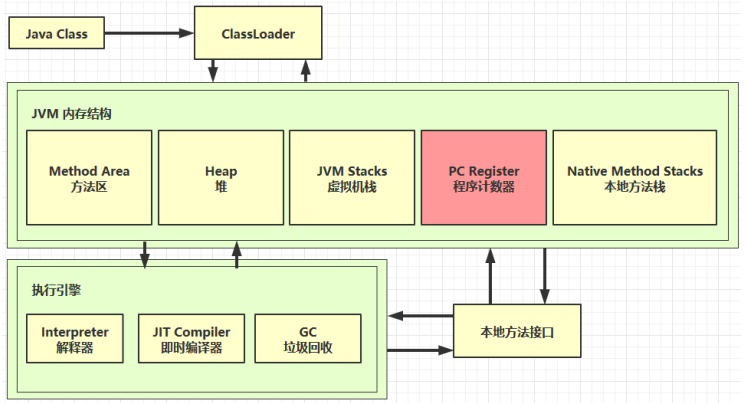
1.1 定义
程序计数器:Program Counter Register 程序计数器(寄存器)
作用:记住下一条jvm指令的执行地址。
特点:
- 是线程私有的(每个线程都有自己的程序计数器,切换线程的时候才知道接下来执行那条命令)。
- 随着线程的创建而创建,随线程销毁而销毁。
- 不会存在内存溢出。
1.2 作用
0: getstatic #20 // PrintStream out = System.out;
3: astore_1 // --
4: aload_1 // out.println(1);
5: iconst_1 // --
6: invokevirtual #26 // --
9: aload_1 // out.println(2);
10: iconst_2 // --
11: invokevirtual #26 // --
14: aload_1 // out.println(3);
15: iconst_3 // --
16: invokevirtual #26 // --
19: aload_1 // out.println(4);
20: iconst_4 // --
21: invokevirtual #26 // --
24: aload_1 // out.println(5);
25: iconst_5 // --
26: invokevirtual #26 // --
29: return
左侧的是 二进制字节码 ,它是jvm指令;而右侧的是 java源代码 。
但是这些jvm指令不能直接交给CPU执行,它需要先转成机器码才能交给CPU执行。这就需要使用到 解释器 将jvm指令转翻译成成机器码再交给CPU。
而程序计数器的作用就是记住下一条jvm指令的地址,如果没有程序计数器,jvm就不知道下一条该执行哪条命令。
①假设取出一条指令 xxx ,解释器将它翻译成机器码再交给CPU执行,与此同时,把下一条的指令地址放入程序计数器。
②等上一条指令执行完后,解释器再去程序计数器中取出下一条指令的地址,再执行①。
2. 虚拟机栈
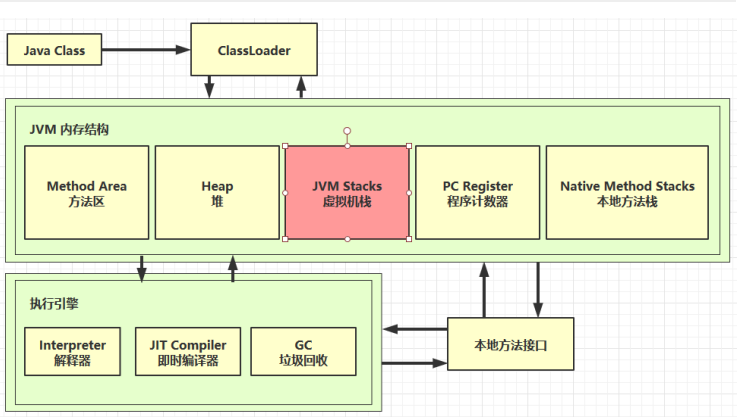
2.1 定义
Java Virtual Machine Statcks (Java虚拟机栈)
- 每个线程运行所需要的内存,称为虚拟机栈。
- 每个栈由多个栈帧(Frame)组成,对应每次方法调用时占用的内存。
- 每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法。
问题辨析:
- 垃圾回收是否涉及栈内存?
- 栈内存分配越大越好吗?
- 方法内的局部变量是否线程安全?
- 如果方法内局部变量没有逃离方法的作用范围,它是线程安全的。
- 如果是局部变量引用了对象,并逃离方法的作用范围,需要考虑线程安全。
1.答:不涉及。栈帧内存在每一次方法调用完毕之后都会弹出栈,不需要垃圾回收来管理栈内存。垃圾回收是去回收堆内存中的无用对象。
2.答:不是。栈内存越大只不过是能进行更多次的方法调用,而且栈内存分配的越大,所支持的线程数会越少。
3.答:安全。局部变量是线程私有的。
2.2 栈内存溢出
栈内存溢出场景:
- 栈帧过多导致栈内存溢出
- 栈帧过大导致栈内存溢出
栈内存大小可通过 -Xss 设置,比如设置 -Xss256k 。栈内存默认大小位1M。
2.3 线程运行诊断
案例1:cpu占用过多
定位:
- 用top命令定位哪个进程对cpu的占用过高,得到pid
- 使用 ps H -eo pid,tid,%cpu | grep pid 。用ps命令进一步定位到是进程的哪个线程cpu占用过高,得到tid
- jstack pid
- 将tid转化为十六进制,与控制台输出比对,进一步定位到问题代码的源码行号
案例2:程序运行很长时间没有结果
- 获得程序的进程id(pid)
- 使用
jstack pid查看信息,发现是死锁 - 在输出信息的末尾可以发现问题原因和代码的源码行号
3. 本地方法栈
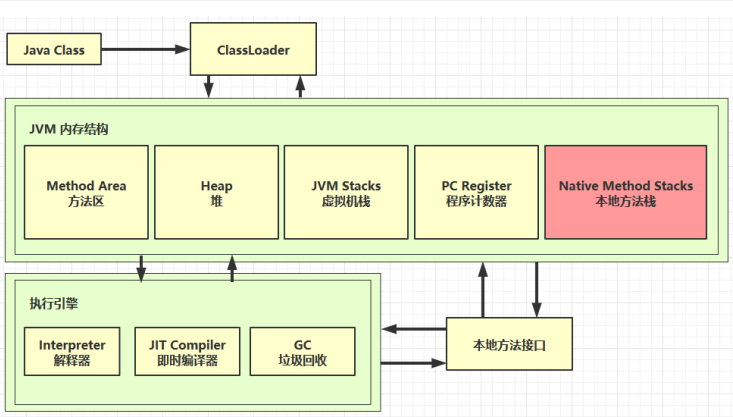
本地方法:不是由java编写的方法,一般是c或c++代码编写的方法。本地方法运行时使用的内存就是本地方法栈。
4. 堆
4.1 定义
Heap 堆
- 通过new关键字创建的对象都会使用堆内存
特点:
- 它是线程共享的,堆中对象都需要考虑线程安全的问题。
- 有垃圾回收机制。
4.2 堆内存溢出
堆内存大小可以通过 -Xmx 设置,比如 -Xmx8m 。
一般来说不再被使用的对象就会被垃圾回收,但是如果对象一直创建一直被使用,那么就会导致堆内存溢出。
4.3 堆内存诊断
- jps工具
- 查看当前系统中有哪些java进程 (
jps)
- 查看当前系统中有哪些java进程 (
- jmap工具
- 查看堆内存占用情况 (
jmap -heap pid)
- 查看堆内存占用情况 (
- jconsole工具
- 图形界面,多功能的监测工具,可以连续监测 (
jconsole)
- 图形界面,多功能的监测工具,可以连续监测 (
案例:
- 垃圾回收后,内存占用仍然很高。
5. 方法区
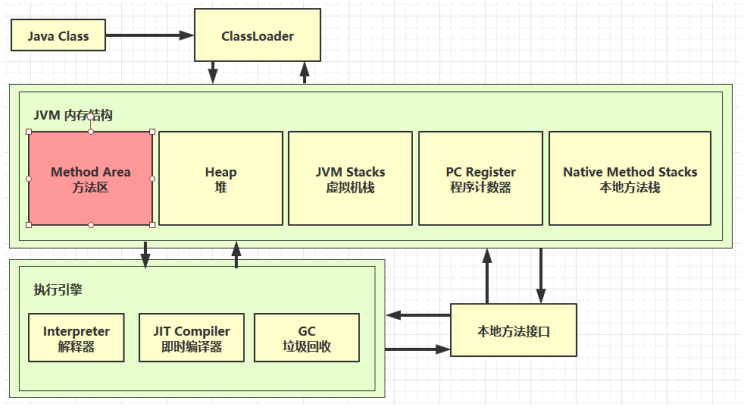
方法区是所有java虚拟机线程所共享的,它存储了类结构的相关信息,比如成员变量,方法和构造器代码,以及特殊方法。
方法区在虚拟机启动时创建,方法区在逻辑上是堆的组成部分,具体是不是堆的一部分不同jvm厂商的实现方式不一样。
5.1 定义
5.2 组成
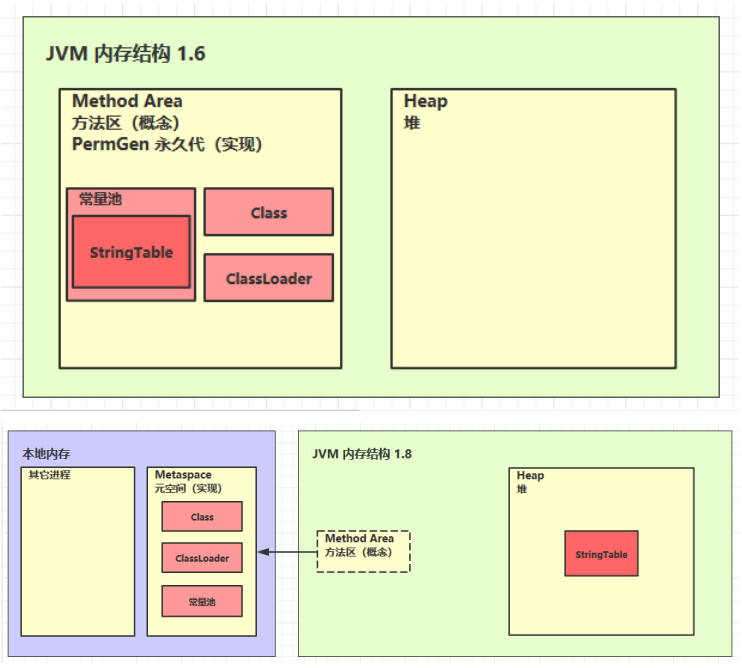
5.3 方法区内存溢出
- 1.8以前会导致永久代内存溢出
* 演示永久代内存溢出 java.lang.OutOfMemoryError: PermGen space
* -XX:MaxPermSize=8m
- 1.8之后会导致元空间内存溢出
* 演示元空间内存溢出 java.lang.OutOfMemoryError: Metaspace
* -XX:MaxMetaspaceSize=8m
场景:
- spring
- mybatis
5.4 运行时常量池
- 常量池:就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息。
- 运行时常量池:常量池是*.class文件中的,当该类被加载,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址。
public class Demo{
public static void main(String[] args){
String s1="a";
String s2="b";
String s3="ab";
}
}
常量池中的信息在程序运行时都会被加载到运行时常量池中,这时a,b,c都还是常量池中的符号,还没有变为java字符串对象。只有当运行到程序引用了”它“的那一行,他才会成为字符串对象。
如下图所示:
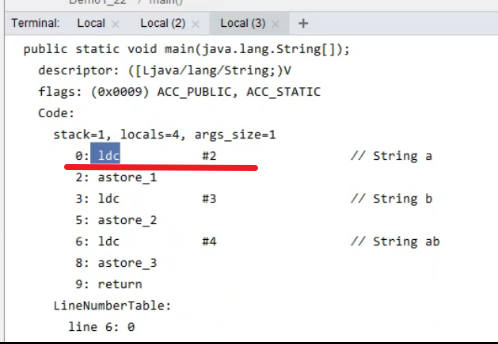
①当程序运行到 ldc #2 时,就要去找一个 a 符号,找到a符号之后就会把它变成字符串对象。
②变成字符串对象之后,jvm需要准备一个 StringTable [] ,又称字符串常量池或串池,它在数据结构上是哈希表,长度固定,不能扩容。
③此时串池还为空,”a“字符串对象创建后把”a“作为key去 StringTable 中找是否有取值相同的key,如果没有,它就会把”a“放入串池。此时串池中只有一个 [“a”]
④接下来两行代码执行完后,串池已经有了三个字符串对象 StringTable ["a","b","ab"]。
在原来的代码中新增一行代码,如下所示:
public class Demo{
public static void main(String[] args){
String s1="a";
String s2="b";
String s3="ab";
String s4=s1+s2; //new StringBuilder().append("a").append("b").toString() = new String("ab")
System.out.println( s3 == s4 );
}
}
将代码编译之后再反编译,如下所示:
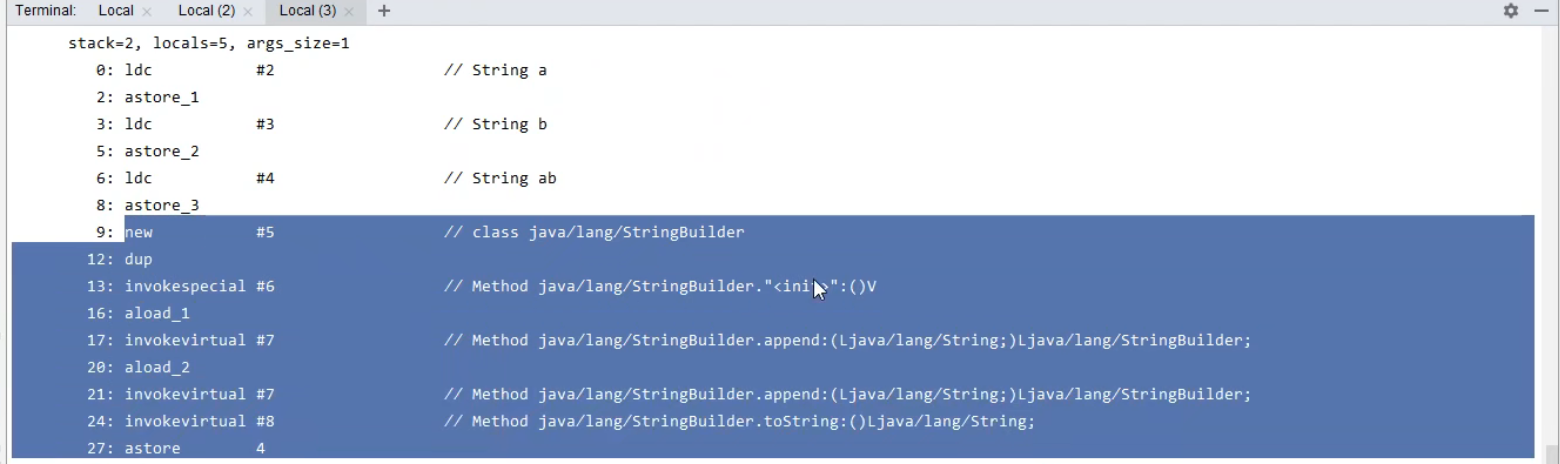
s4的值是通过new关键字创建出来的,它存储在堆中,而s3是串池中的字符串对象,它们的地址不同,所以输出false 。
继续增加代码:
public class Demo{
public static void main(String[] args){
String s1="a";
String s2="b";
String s3="ab";
String s4=s1+s2; //new StringBuilder().append("a").append("b").toString() = new String("ab")
String s5="a"+"b"; //javac 在编译期间就会将"a"+"b"优化为"ab",因为"a"和"b"都已经是常量了。而上一行的是变量,所以不会优化。
System.out.println( s3 == s4 ); //false
}
}
5.5 StringTable 特性
- 常量池中的字符串仅是符号,第一次用到时才变为对象。
- 利用串池的机制,来避免重复创建字符串对象。
- 字符串变量拼接的原理是
StringBuilder。 - 字符串常量拼接的原理是编译期优化。
- 可以使用
intern()方法,主动将串池中还没有的字符串对象放入串池。1.8将这个字符串对象尝试放入串池,如果有则不会放入,如果没有则会放入串池,会把串池中的对象返回。1.6将这个字符串对象尝试放入串池,如果有则不会放入,如果没有会把此对象复制一份,放入串池,会把串池中的对象返回。
例:
public static main(String[] args){
String s = new String("a") + new String("b"); // new String("ab")
//串池 StringTable: [ "a","b" ]
//堆 new String("a") , new String("b") , new String("ab")
//再执行如下代码
String s2 = s.intern(); //将这个字符串对象尝试放入串池,如果有则不会放入,如果没有则放入串池,会把串池中的对象返回。
//串池 StringTable: [ "a","b","ab" ]
//堆 new String("a") , new String("b") , new String("ab")
System.out.println(s2=="ab"); //true
System.out.println(s=="ab"); //true
}
5.6 StringTable 位置
在jdk1.6的版本中,StringTable在永久代中;在 jdk1.8 的版本中,StringTable在堆中。
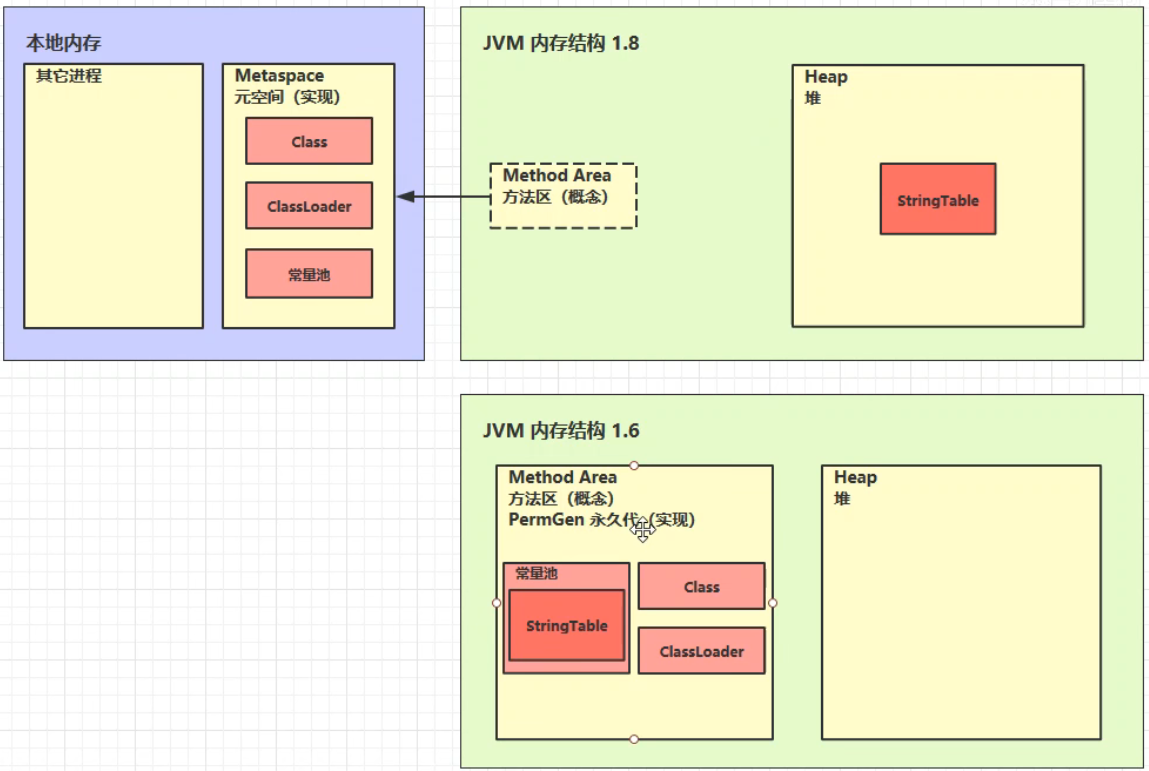
5.7 StringTable 垃圾回收
Xmx10m指定虚拟机堆内存大小。XX:+PrintStringTableStatistics打印字符串常量池信息。-XX:+PrintGCDetails和-verbose:gc打印垃圾回收的信息,如果发生了垃圾回收,会把垃圾回收的次数和耗费时间打印出来
5.8 StringTable 性能调优
- 调整
-XX:StringTableSize=桶个数。最少1009个
桶的个数越多,元素越分散,哈希碰撞的几率就越低,查找的速度就越快。
- 考虑将字符串对象是否入池
可以通过 intern() 方法减少重复入池,保证相同的字符串在内存中只存一份。
6. 直接内存
6.1 定义
直接内存(Direct Memory):直接内存并不是虚拟机运行时数据区的一部分,也不是虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用。而且也可能导致 OutOfMemoryError 错误出现。
jdk1.4 中新加入的 NIO (New Input/Output)类,引入了一种基于通道(Channel)与缓存区(Buffer)的 I/O 方式,它可以直接使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样就能在一些场景中显著提高性能,因为避免了在 Java 堆和 Native 堆之间来回复制数据。
特点:
- 常见于NIO操作时,用于数据缓冲区。
- 分配回收成本较高,但读写性能高。
- 不受JVM内存回收管理。
传统IO读写文件过程:
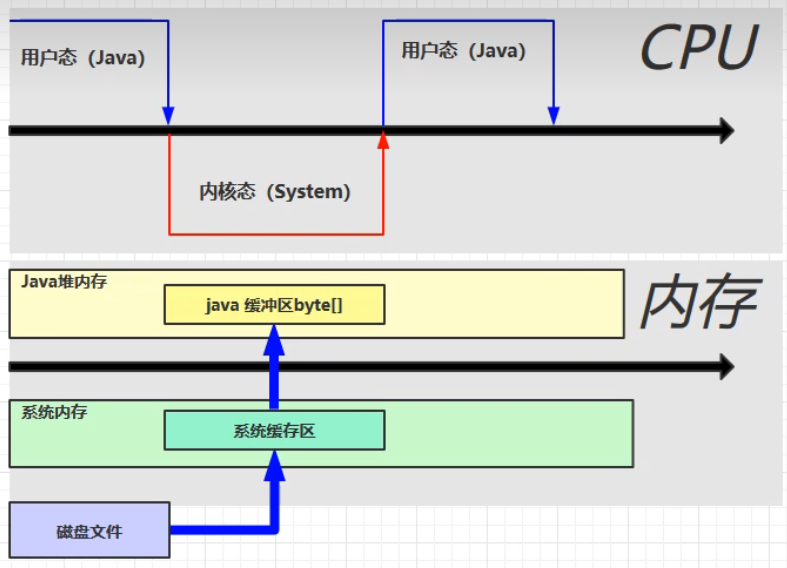
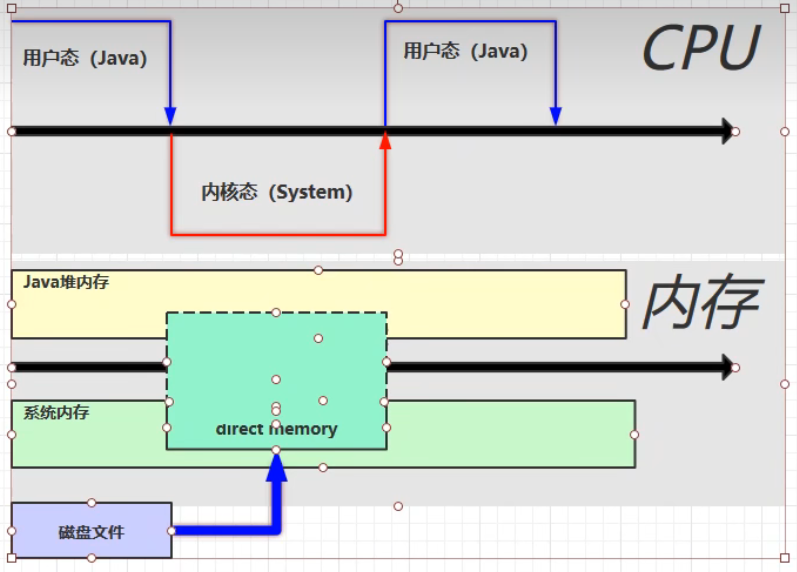
使用DirectBuffer之后读写文件的过程:
direct momory系统可以使用,java代码也可以使用,省略了从赋值系统内存中的数据到java缓冲区的操作,提高了效率。
直接内存溢出:
public class Demo {
static int _100MB = 1024 * 1024 * 100;
public static void main(String[] args) throws IOException {
List<ByteBuffer> list = new ArrayList<>();
int i = 0;
try {
while (true) {
//每次分配100mb的直接内存
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_100MB);
list.add(byteBuffer);
i++;
}
} finally {
System.out.println(i);
}
}
}
运行上述代码:
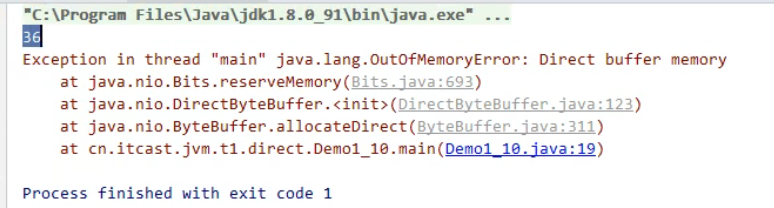
注:本机的直接内存分配不受java堆的限制,但是,既然是内存就会受到本机总内存大小以及处理器寻址空间的限制。
6.2 分配和回收原理
垃圾回收不会管理直接内存。
- 使用了
Unsafe对象完成直接内存的分配回收,并且回收需要主动调用freeMemory方法。 ByteBuffer的实现类内部,使用了Cleaner(虚引用)来监测ByteBuffer对象,一旦ByteBuffer对象被垃圾回收,那么就会由ReferenceHandler线程通过Cleaner的clean方法调用freeMemory来释放直接内存。
在代码中编写 System.gc() 是显示的垃圾回收,它触发的是 Full GC,比较影响性能(不仅要回收新生代,还要回收老年代,会造成程序暂停时间比较长)。为防止一些程序员在代码中经常写 System.gc() ,我们做JVM调优时经常会加上 -XX:+DisableExplicitGC 虚拟机参数来禁用显示垃圾回收(使 System.gc() 无效)。但是加上这个参数后可能会影响直接内存的回收机制。

















 1877
1877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









