 C语言数组排序与二维、一维数组详解
C语言数组排序与二维、一维数组详解





摘要:本文介绍了数组排序算法和数组类型的基础知识。在排序算法部分,详细讲解了冒泡排序和选择排序的工作原理与实现方式:冒泡排序通过相邻元素比较交换实现排序,而选择排序通过每次选择最小元素交换位置实现排序。在数组类型部分,阐述了二维整型数组的存储形式、初始化方法及本质特征,以及一维字符型数组的初始化、元素访问、字符串打印和输入输出操作。特别说明了strlen和sizeof在字符串处理中的区别,并提供了相关示例代码。全文涵盖了数组操作的基础概念和实用技巧。
一、数组的排序
1、冒泡排序
(1)工作原理:是通过重复遍历待排序的数据序列,依次比较相邻元素,并根据需要交换它们的位置。这样,每次遍历都能确保至少一个元素移动到它最终应该在的位置上(对于升序排序来说,较大的元素会向序列末尾“沉”,较小的元素则会逐渐“浮”到前面)。这个过程类似于水中的气泡,小气泡逐渐上升至水面,大气泡则下沉到底部。
(2)实现方式:比较相邻的元素。如果第一个比第二个大(或者想降序排列时,第一个比第二个小),就交换他们两个。对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。针对所有的元素重复以上的步骤,除了最后一个已经确定位置的元素外。重复步骤1~3,直到没有任何一对数字需要比较。
(3)图解:
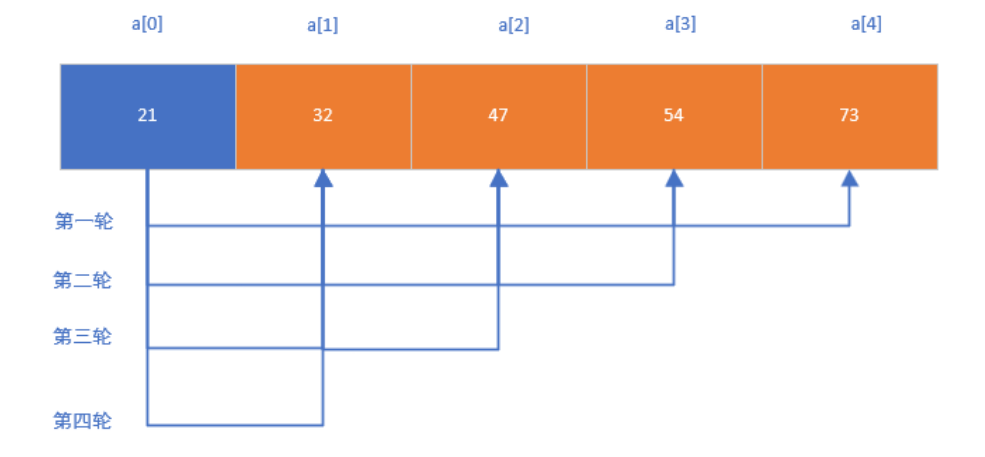
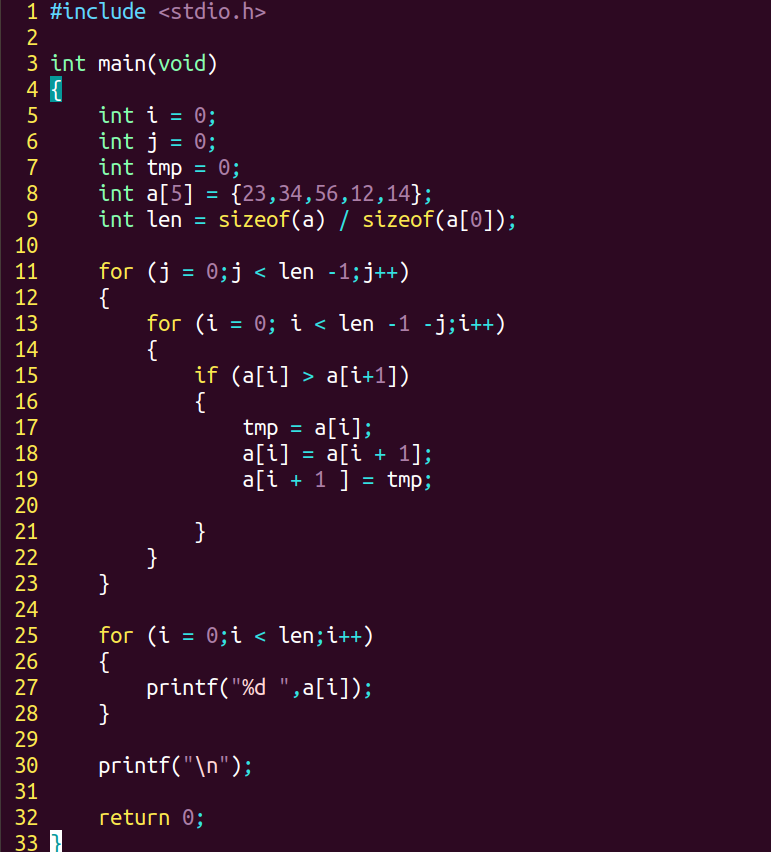
(4)代码实现:利用两个for循环然后再利用 if 语句进行数据交换
(5)示例:利用冒泡排序实现对数组的排序

2、选择排序
(1)工作原理:选择排序是一种简单直观的比较排序算法,其核心思想是每次从未排序部分选出最小(或最大)元素,放到已排序部分的末尾。由于它在每一轮遍历中只进行一次交换,因此比冒泡排序更高效(交换次数更少)。
(2)实现方式:
- 初始状态:整个数组被视为未排序部分
- 查找最小值:在未排序部分中找到最小的元素;
- 交换位置:将找到的最小元素与未排序部分的第一个元素交换位置;
- 缩小范围:将已排序部分的边界向后移动一位,重复步骤2和3,直到整个数组有序。
(3)图解: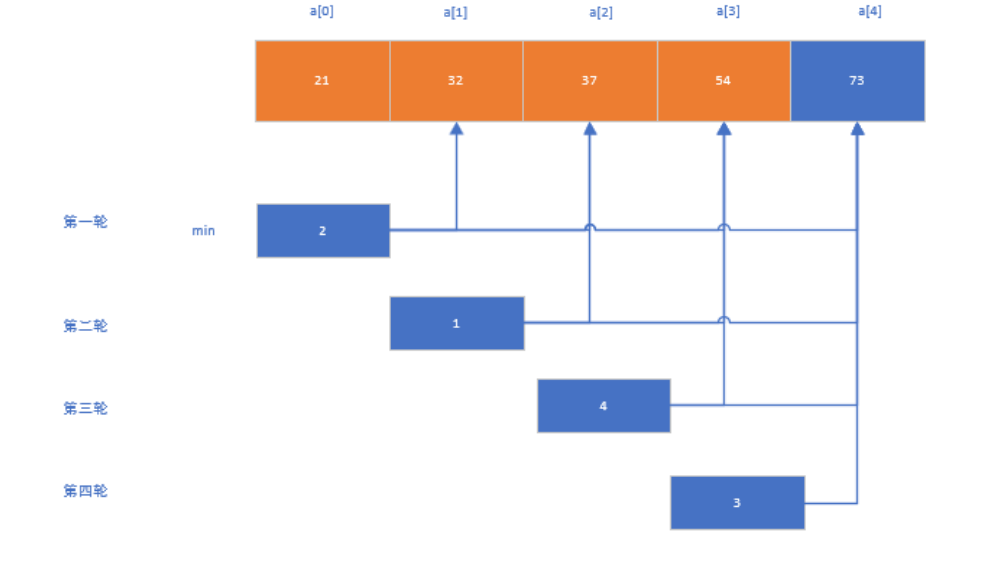
(4)代码实现:选择排序,通过比较选择出最小的数组放在最前面,依次进行。实现方式通过for循环加if语句选出最小值,更新交换数组的方式是用,元素下标法。
(5)示例:利用选择排序对数组进行排列 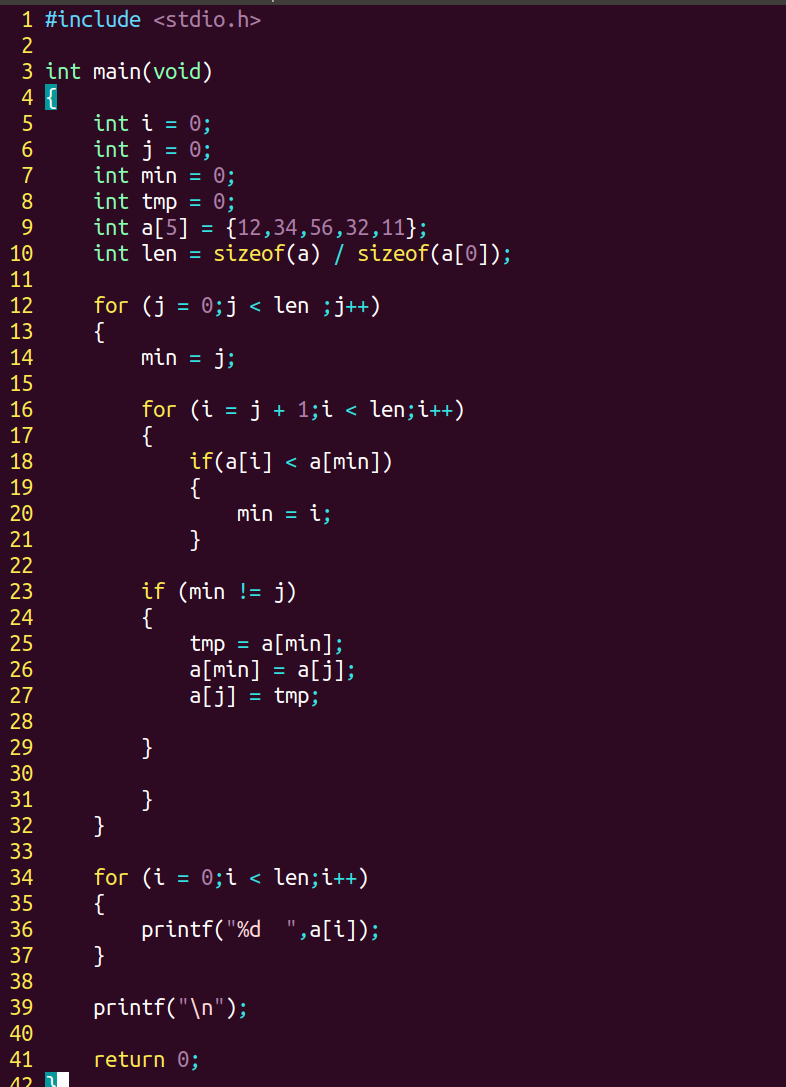

二、二维整型数组
1、形式: 数据类型 数组名[行数][列数];
eg:a[2][3]: a[0][0] = 1; a[0][1] = 2; a[0][2] = 3;
a[1][0] = 4; a[1][1] = 5; a[1][2] = 6;
2、初始化:
- 全部初始化:a[2][3] = {1,2,3,4,5,6};
- 局部初始化:a[2][3] = {{0}};
- 默认初始化:int a[ ][3] = {{1,2},{3}}; //两列三行
3、存储:连续性、有序性
4、本质:二维数组是
三、一维字符型数组
1、形式: char str [元素个数];
元素个数必须为常量、必须注意存储空间(因为字符串末尾有'\0'结尾)。
2、元素访问:
- 元素下标的范围:0—元素个数-1;
- 元素下标可以是常量、变量、表达式;
- 数组只能对单个元素进行操作,不能对整个数组进行操作;
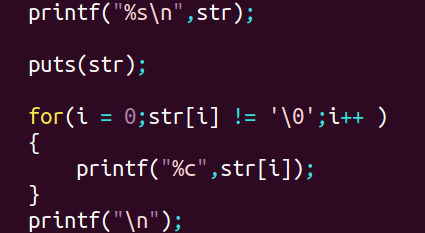
3、字符串打印:
- printf(%s):打印数组开头到 '\0' 中间的内容
- puts:打印数组开头到 '\0' 中间的内容,会多打一个 '\n'
- for循环:利用逻辑表达式
- 用法如图所示
4、初始化:
(1)全部初始化:char str[6] = {'h', 'e', 'l', 'l', 'o', '\0'};
char str[6] = {"hello"} ;
char str[6] = "hello";
(2)局部初始化:char str[6] = {'h', 'e', 'l', '\0'};
char str[6] = {0};
(3)默认初始化:char str[ ] = {'h', 'e', 'l', 'l', 'o', '\0'} ;
char str[ ] = {"hello"};
5、存储:连续性 、有序性
6、从终端接收字符串:
(1)scanf("%s", str); 只能接收不含 '空格' 的字符串
(2)gets(str); 可以接收带有 '空格' 的字符串,会报错但不影响
7、统计字符串长度:
(1)strlen:获得数组中字符串的长度与数组大小无关 ,使用前要加头文件
#include <string.h> //头文件
strlen(str);
(2)sizeof:获得数组所占字节空间大小(由数组定义时元素个数决定,与数组中存放的字符串
没有关系) sizeof(str);
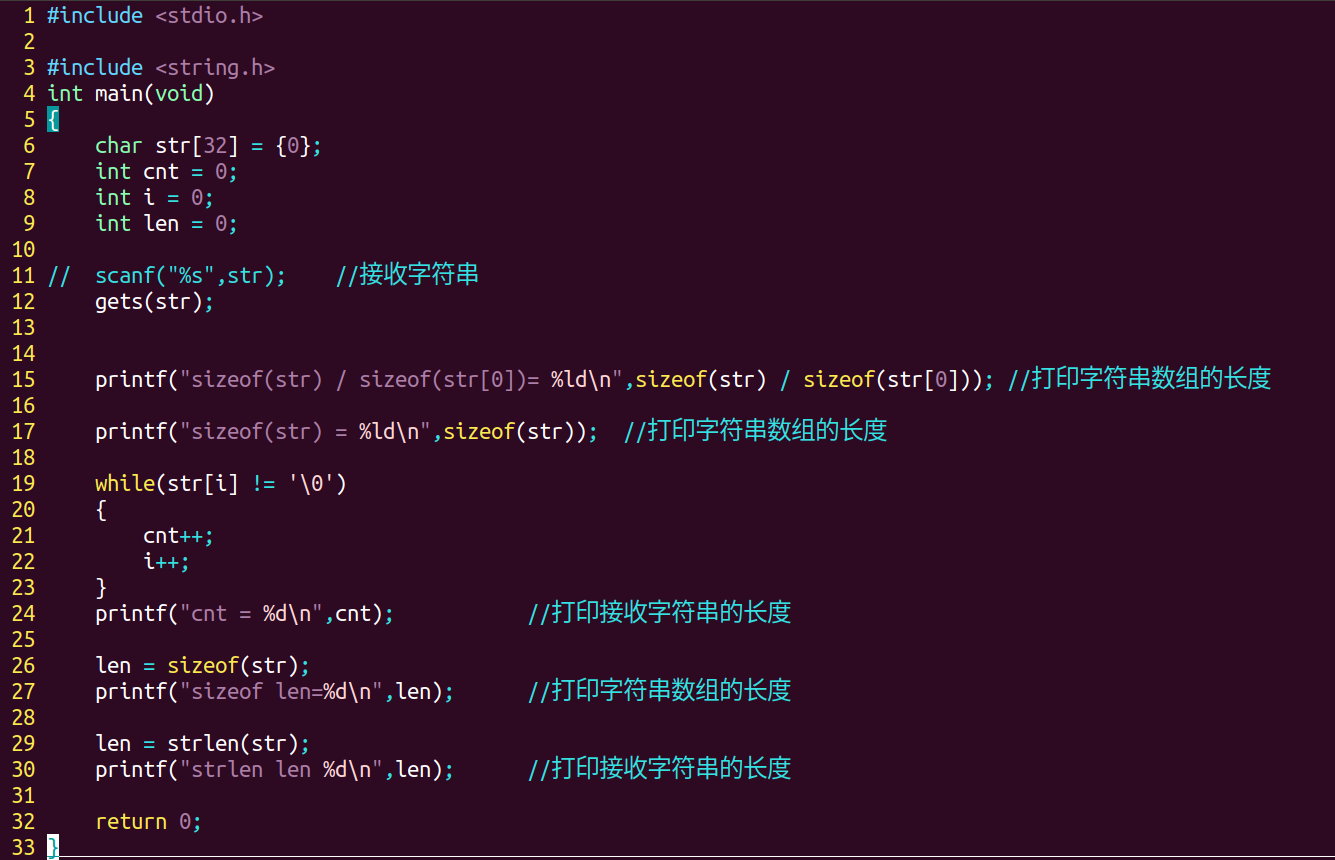
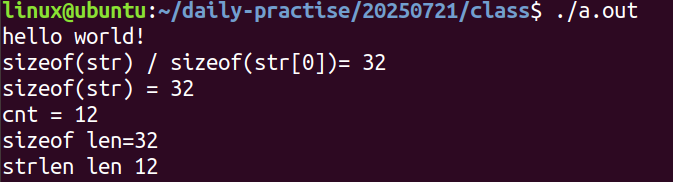
8、示例如图所示

















 792
792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









