




 本文介绍了PyTorch中的数据读取机制,包括DataLoader和Dataset的使用。DataLoader用于构建可迭代的数据装载器,其内部涉及到Sampler和Dataset。Dataset是数据集类,需重写__getitem__方法来读取数据。文章通过实例解释了如何通过DataLoader和Dataset处理数据的划分、读取和预处理,以及如何根据batch_size、shuffle等参数进行数据加载。
本文介绍了PyTorch中的数据读取机制,包括DataLoader和Dataset的使用。DataLoader用于构建可迭代的数据装载器,其内部涉及到Sampler和Dataset。Dataset是数据集类,需重写__getitem__方法来读取数据。文章通过实例解释了如何通过DataLoader和Dataset处理数据的划分、读取和预处理,以及如何根据batch_size、shuffle等参数进行数据加载。
机器学习的五大模块:

数据模块又可分为以下几部分:
● 数据的收集:Image、label
● 数据的划分:train、test、valid
● 数据的读取:DataLoader,有两个子模块,Sampler和Dataset,Sampler是对数据集生成索引index,DataSet是根据索引读取数据
● 数据预处理:torchvision.transforms模块
所以这一节主要介绍pytorch中数据的读取模块
一、DataLoader
torch.utils.data.DataLoader():构建可迭代的数据装载器,在训练数据时,每一个for循环,就是一次iteration,就是从DataLoader中获取一个batchsize大小的数据
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)
常用的参数:
dataset:Dataset类,决定从哪读取以及如何读取数据;
batch_size:int型,批量的大小
shuffle:每个epoch的数据是否打乱
num_workers:是否进行多进程读取数据,若采取多进程,减少读取数据的时间,可以加速模型训练
drop_last:当样本数不能被batchsize整除时,是否舍弃最后一批数据
另外:Epoch,Iteration,Batchsize的区别
Epoch:所有的数据都输入到模型中,称为一个Epoch;
Iteration:一批样本输入到模型中,为一次Iteration;
Batchsize:输入到模型中的一批样本的大小;
例:假设样本总数是80,batchsize是8,那么一个epoch=10次Iteration;假设样本总数是87,batchsize是8,如果drop_last=True,最后一批数据不满足batchsize 8,舍去,一个epoch=10次Iteration,若drop_last=False,不舍去最后一批数据, 一个epoch=11次Iteration,最后一次的Iteration有7个样本。
二、Dataset
torch.utils.data.Dataset():Dataset类,所有自定义的数据集都要继承这个类,并且复写__getitem__()这个类方法;定义数据从哪里读取以及如何读取。
class Dataset(object):
def __init__(self):
pass
def __len__(self):
raise NotImplementedError
def __getitem__(self,index):
#接受一个索引,返回一个样本
raise NotImplementedError
__getitem__方法是Dataset的核心,作用是接受一个索引值,返回样本数据,在自定义数据集中重点是要如何根据这个索引值来读取数据。
下面以人民币的二分类任务介绍具体的数据读取机制,在数据读取之前,思考以下数据的三个问题:
1、读哪些数据?在每一次iteration时要读取batch size大小的数据,那么如何从样本中选取这batch size大小的数据呢?
2、从哪里读取?也就是在硬盘中该怎么去找数据,在哪设置这个参数?
3、怎么读取数据?
带着这三个问题,来看一下这个任务的数据读取部分:
split_dir = os.path.join(BASE_DIR, 'data', 'rmb_split')
if not os.path.exists(split_dir):
raise Exception('\n{} 路径不存在'.format(split_dir))
train_dir = os.path.join(split_dir, 'train')
valid_dir = os.path.join(split_dir, 'valid')
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(root_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(root_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
在上面代码中,首先是数据的读取路径,其次是数据的预处理模块,然后是通过自定义数据集RMBDataset类来构建数据集,最后是构建数据装载器DataLoader。其中核心是构建数据集的RMBDataset类,这个自定义数据集类继承了Dataset,并且重写了__getitem__() 方法,这个类的目的就是传入数据的路径和预处理部分,然后返回数据。
class RMBDataset(Dataset):
def __init__(self, root_dir, transform=None):
self.lable_name = {'1': 0, '100': 1}
self.data_info = self.get_img_info(root_dir)
self.transform = transform
def __getitem__(self, index):
img_path, label = self.data_info[index]
img = Image.open(img_path).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.data_info)
def get_img_info(self, root_dir):
data_info = list()
for root, dirs, files in os.walk(root_dir):
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root_dir, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
for i in range(len(img_names)):
img = img_names[i]
img_path = os.path.join(root_dir, sub_dir, img)
label = self.lable_name[sub_dir]
data_info.append((img_path, int(label)))
return data_info
在RMBDataset类中是接受一个index,返回一个样本的img和label,那如何获取batch size大小的样本呢?正是通过DataLoader类来获取,通过设置batch_size参数,来确定一批数据获取多少个样本。
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
下面来看在具体的训练过程中是如何调用,在模型训练的数据读取部分打上断点,进行debug,如下:
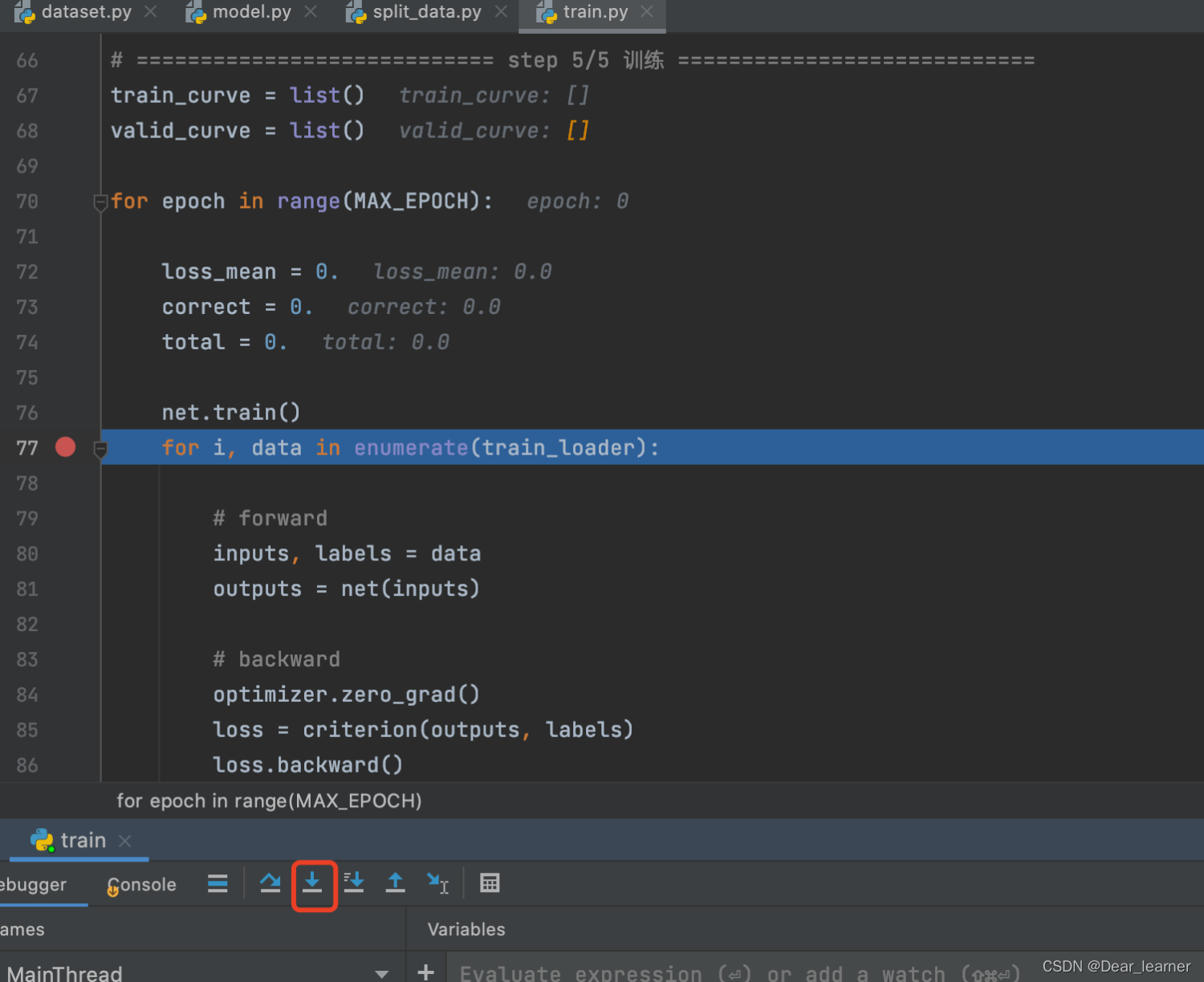
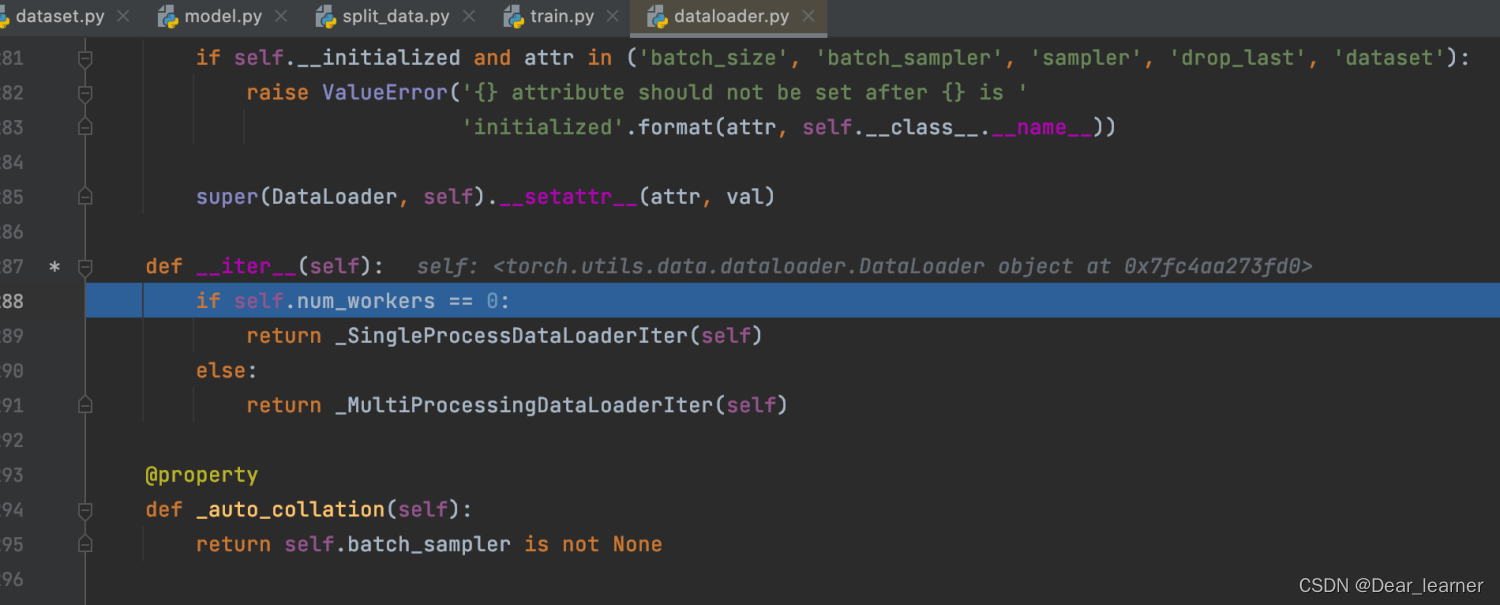
可以看到程序跳转到了dataloader.py 文件中的 __iter__方法中,说明是用单进程还是多进程来读取数据,step into 进入单进程读取数据
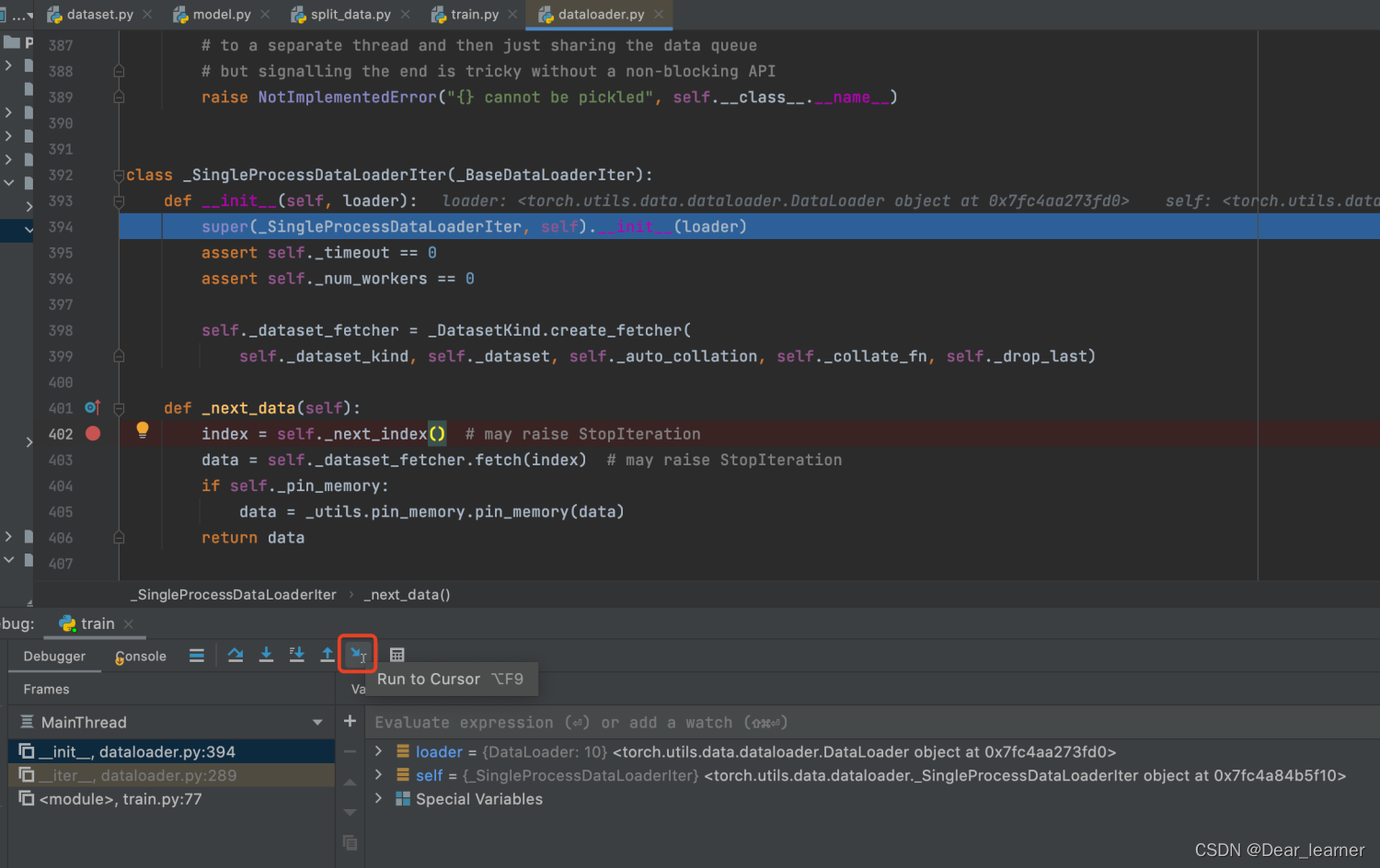
从此类中的_next_data()方法中可以看出,通过index来获取数据data,将光标放到 index = self._next_index() 这一行,然后点击下面的 run to cursor 图表,就会跳到这一行,然后 stepinto
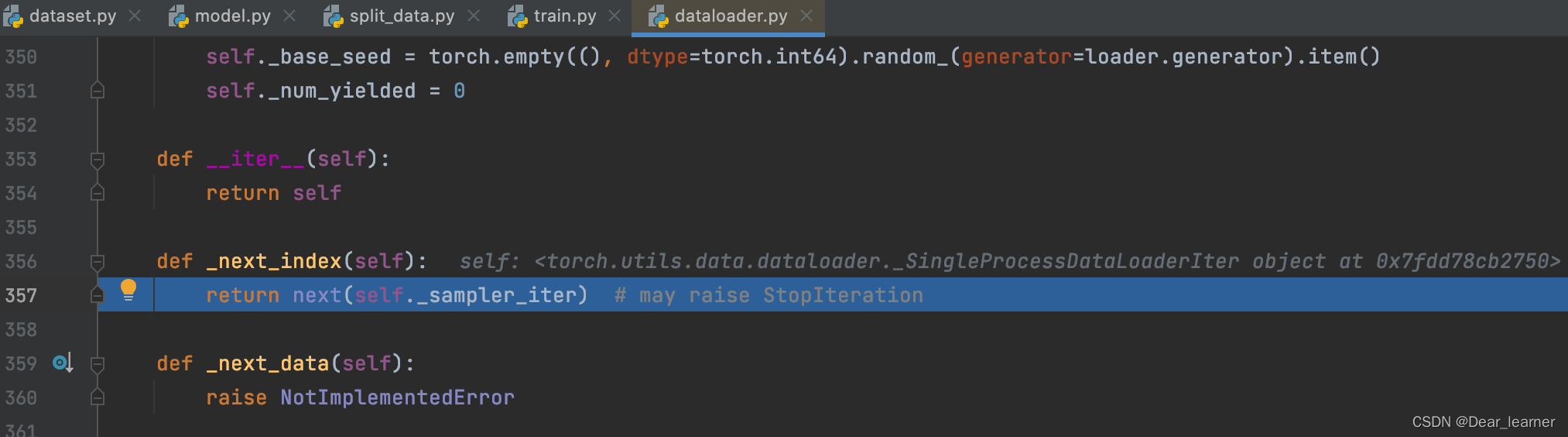
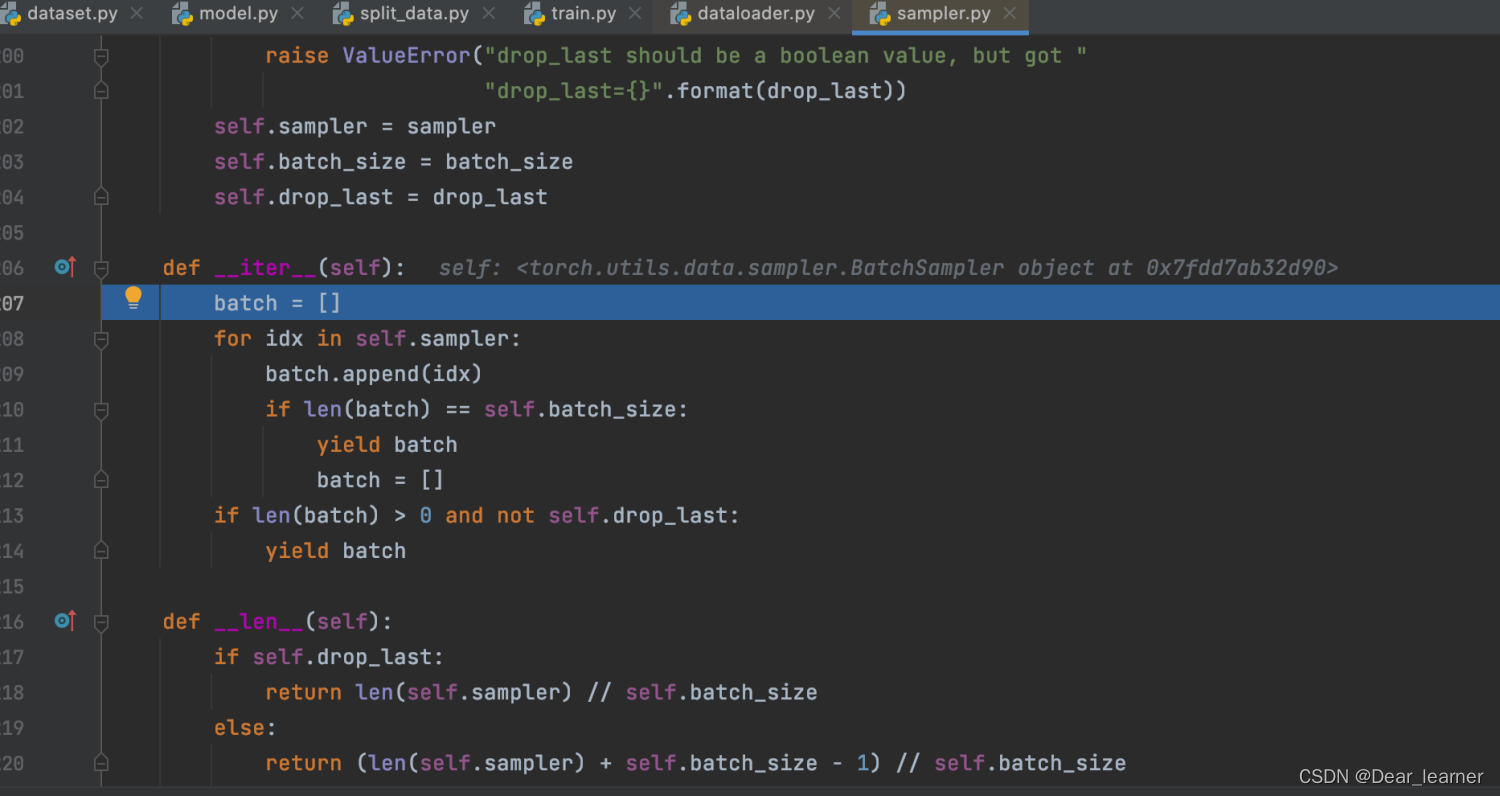
进入到sampler.py文件中,其中最重要的是__iter__方法,主要作用是一次次采样数据的索引,直到batch size大小返回。
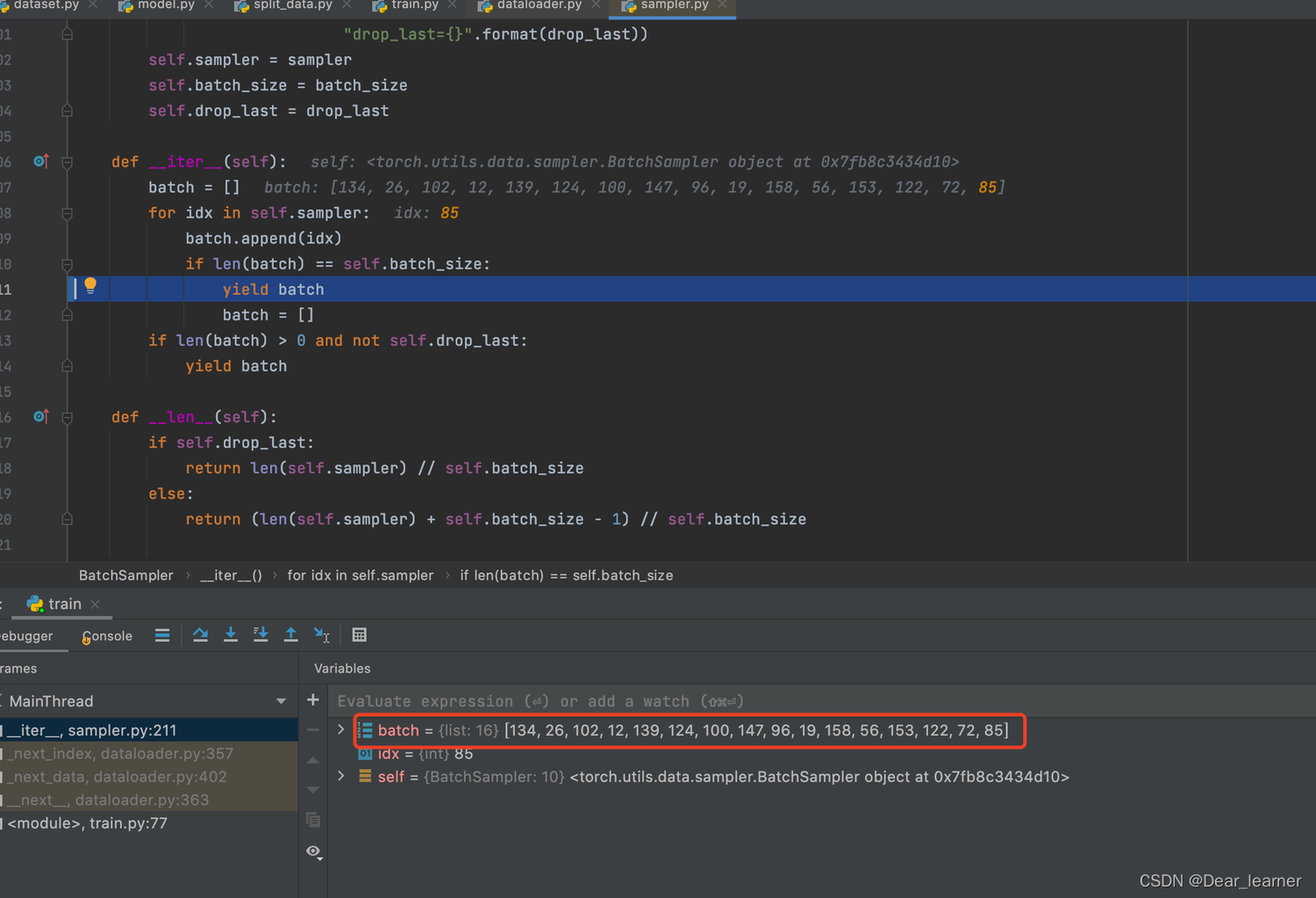
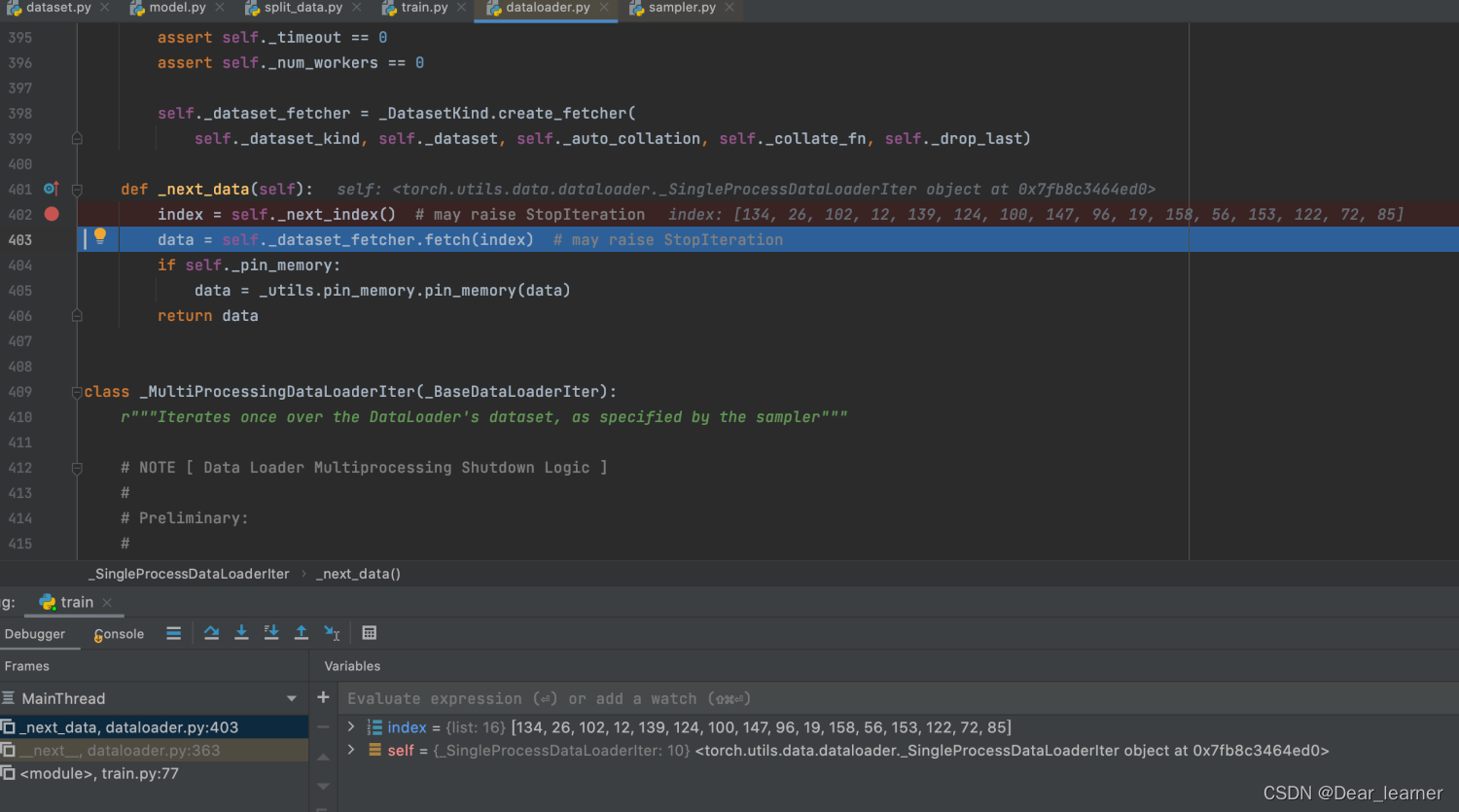
通过sampler.py文件中的__iter__方法获得了batch size大小的索引,代码 data = self._dataset_fetcher.fetch(index) 正是通过这些索引来获取数据,step into 来查看一下具体是怎么获取这些数据的。

进入到fetch.py 文件中,核心方法是fetch方法,这里调用了self.dataset[index]方法来获取数据,进一步step into,可以看到进入自定义数据集 RMBDataset 类中的 __getitem__方法中,这个在前面已经介绍过,通过索引来获取样本的数据和标签,在fetch中获取data是通过一个列表推导式,所以就可以这个方法获取一个batch size大小的样本
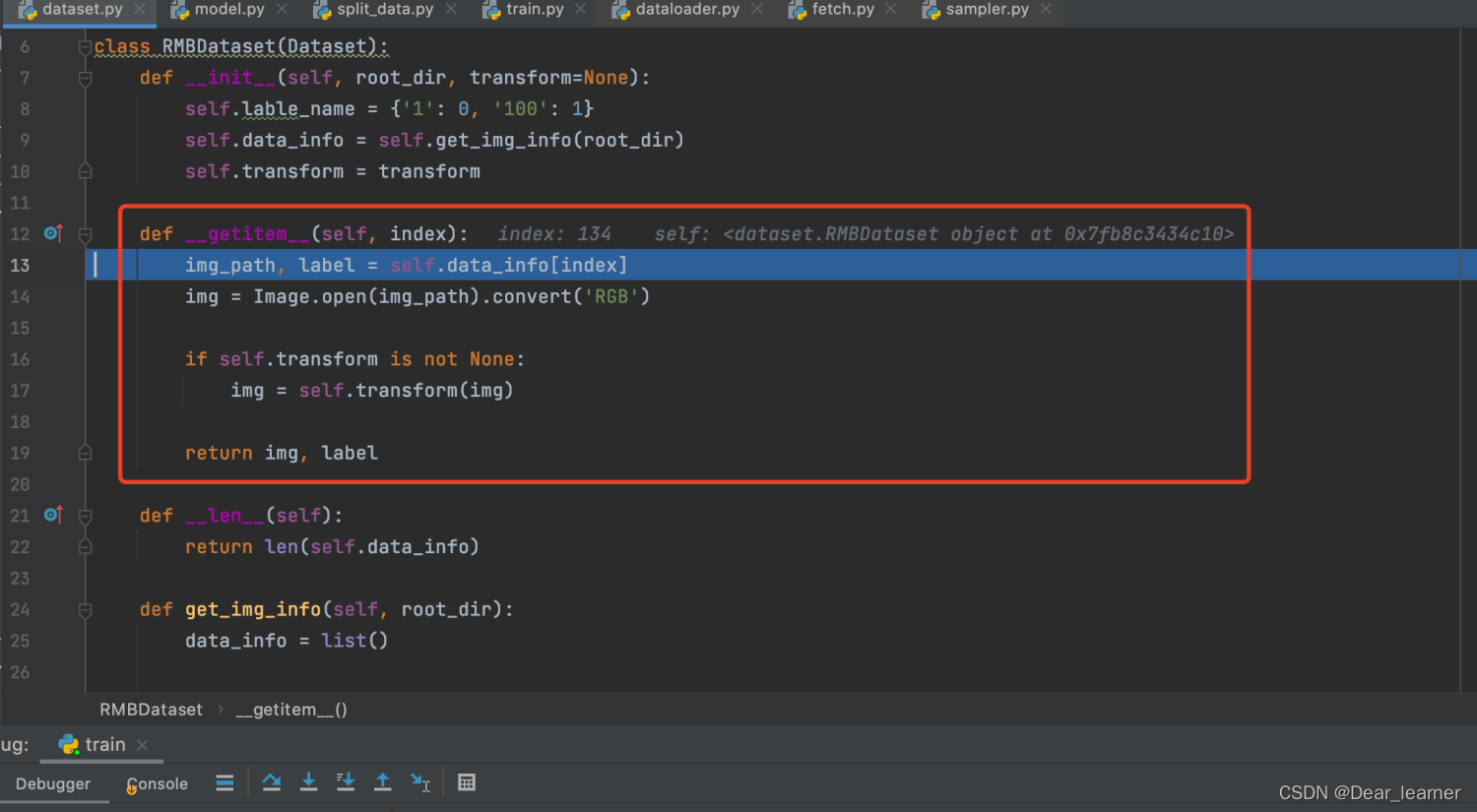
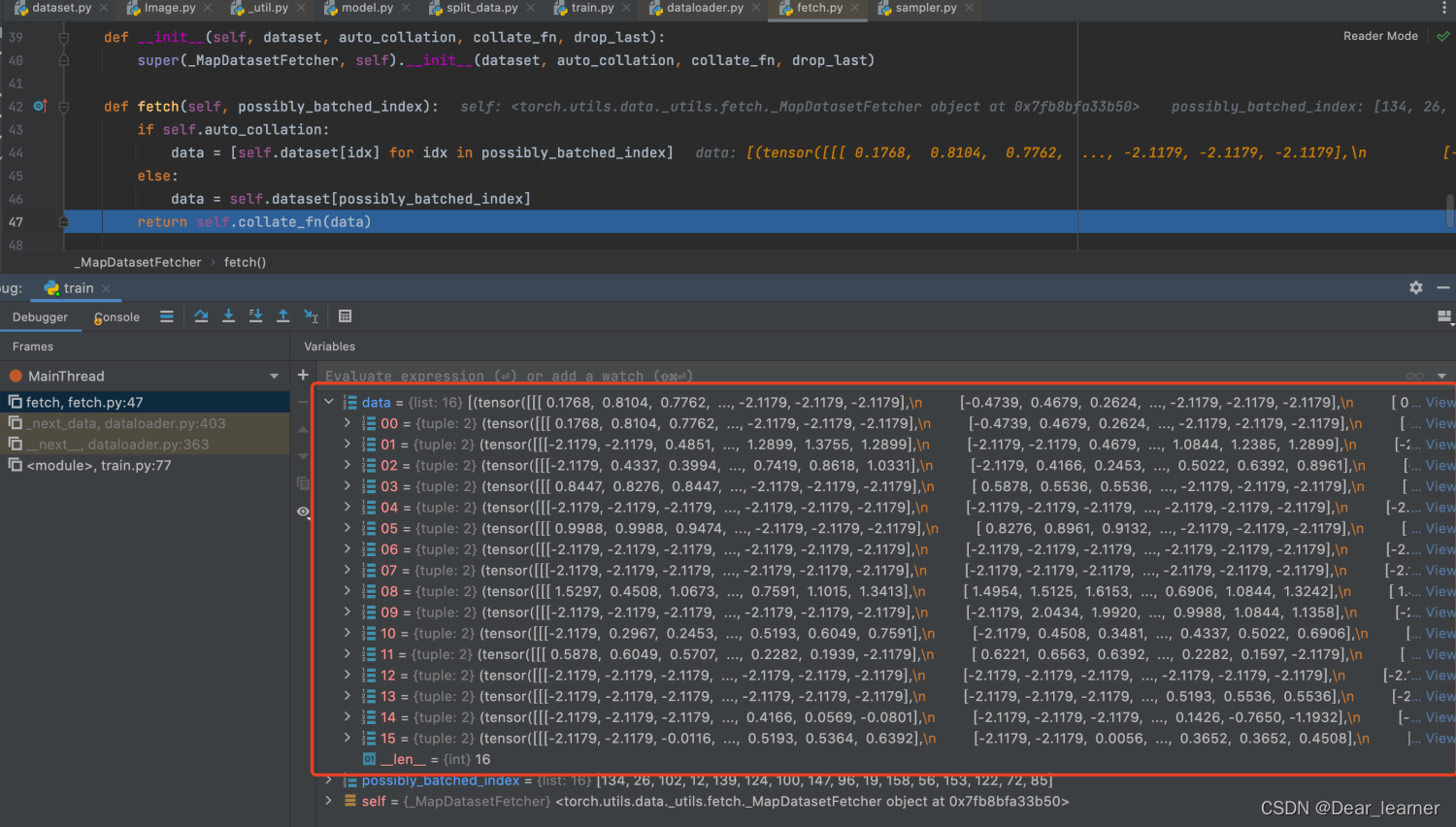
取完一批batch size的数据,然后进入self.collate_fn(data)进行整合,step into 进入到collate.py文件中
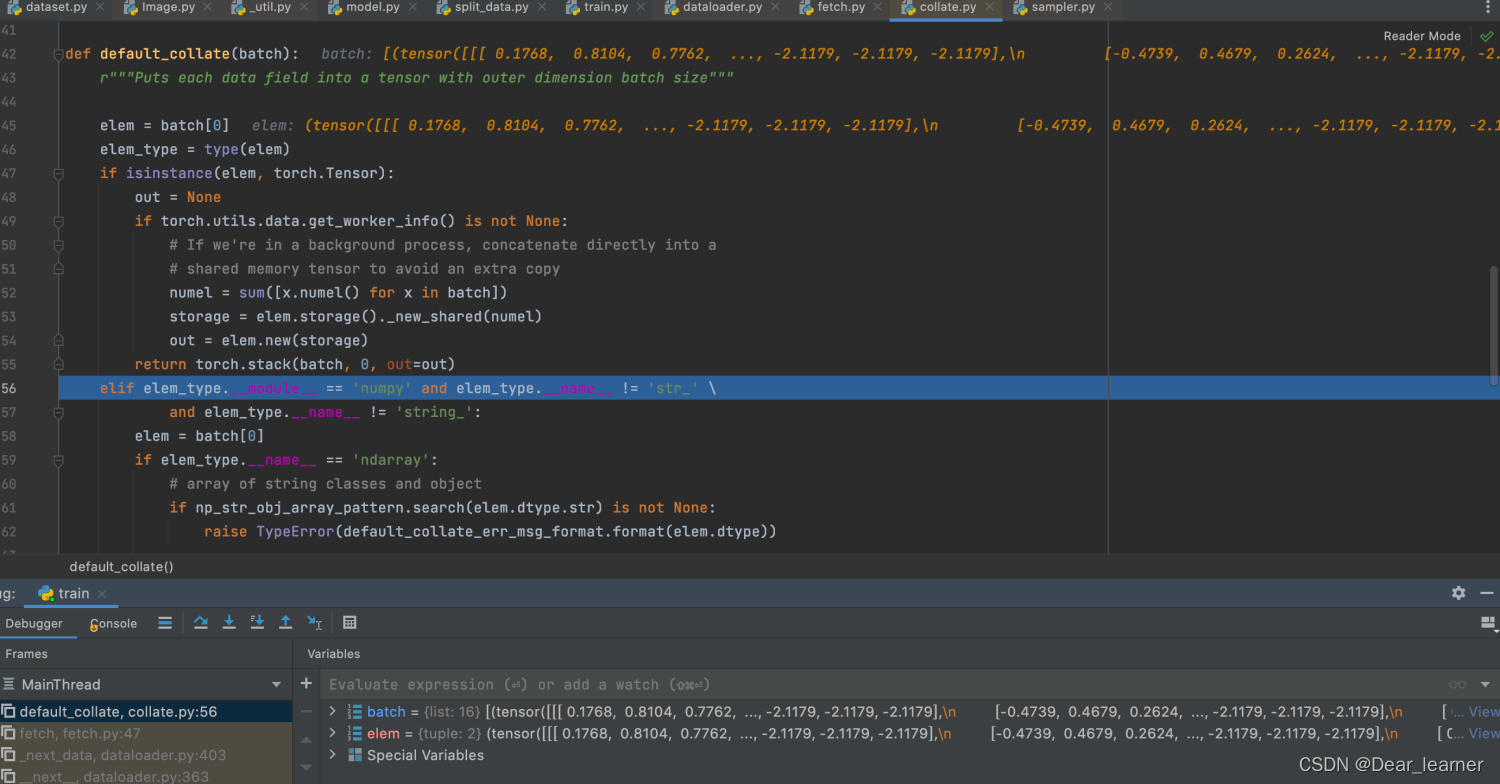
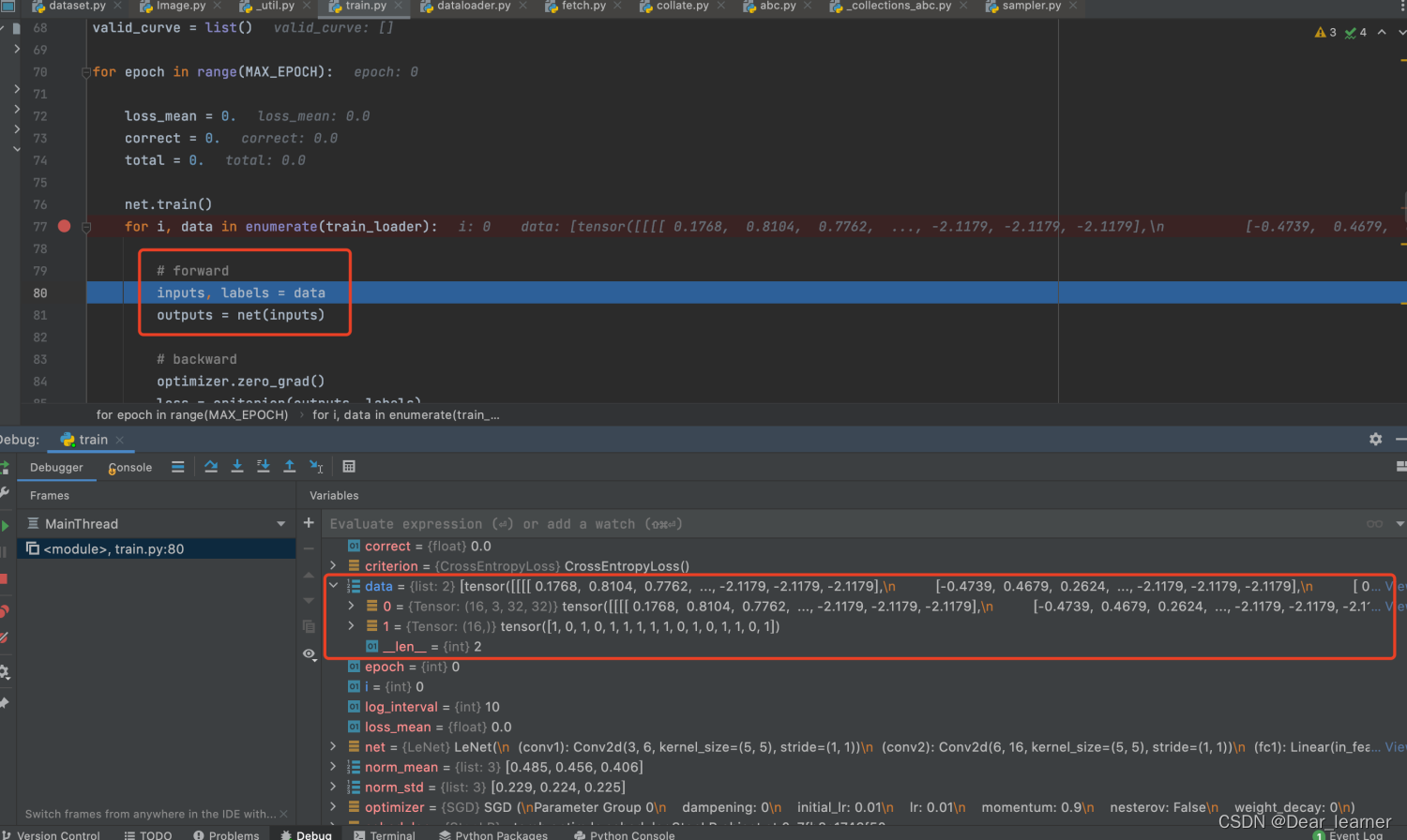
通过上面可以看到获得了第一个批次的数据,所以train_loader 把数据分成一个个的batch,然后通过enumerate就可以获得一批批的数据用于训练模型,这这批次的所有数据进入模型训练,就完成了一个epoch的训练。
通过代码调试,可以看到DataLoader读取数据的大概过程,回到读取数据的三个问题:
1、读哪些数据?这个是根据Sampler输出的index来决定的;
2、从哪读数据?这个Dataset中通过设置的data_dir来读取;
3、怎么读数据?Dataset中的__getitem__方法,来获取一个样本的数据。
下面用流程图来梳理一下这个逻辑过程:
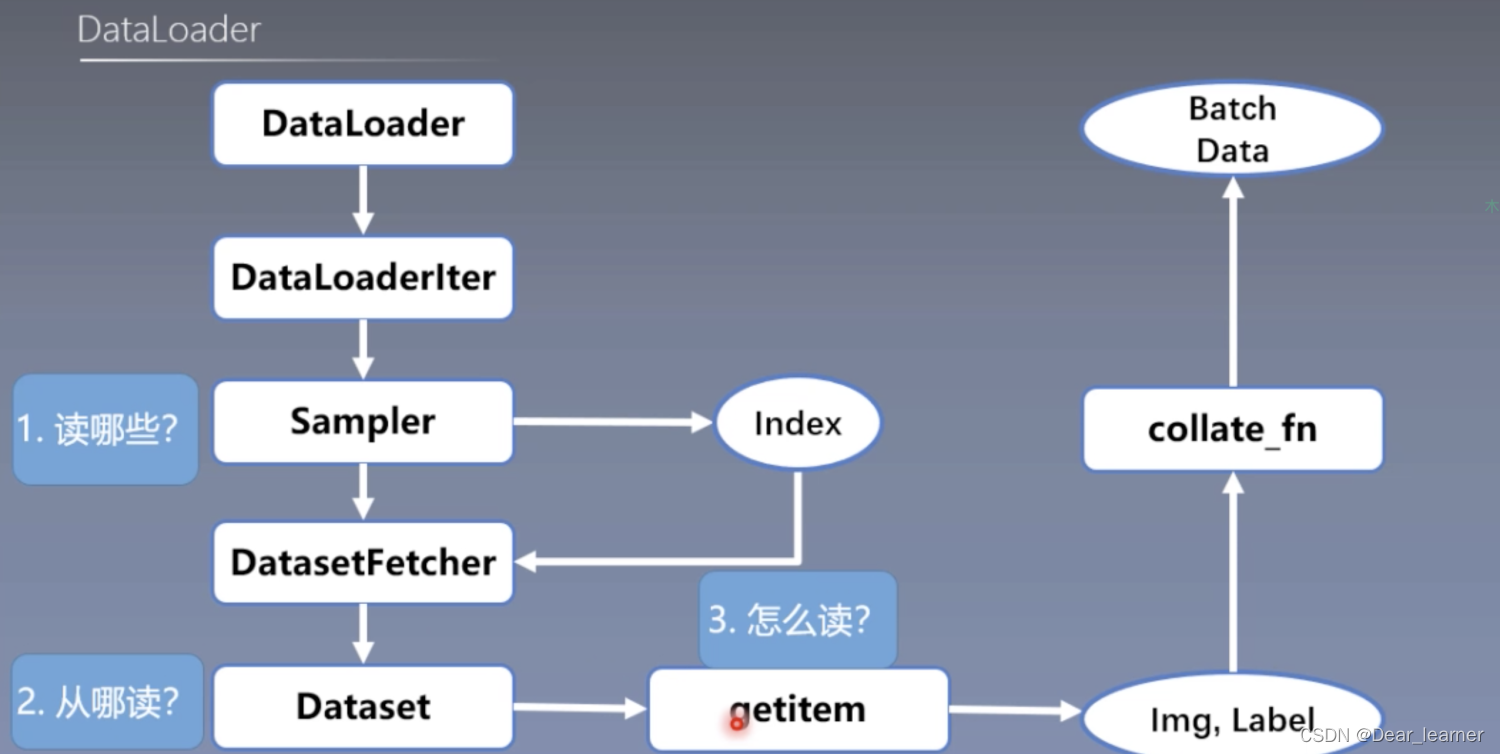
总结:
● DataLoader的作用就是提供一个数据装载器,根据batch size的大小,将数据分成一个个batch去训练模型,而分数据的这个过程需要把数据读取到,这个借助Dataset中的__getitem__方法来获取样本数据。
● 在构建自定义数据集时,需要继承Dataset,并且复现__getitem__方法,实现数据怎么读,另外要重写__len__方法,返回多少个数据样本。


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









