




线程和进程并发(concurrently)或并行执行(in parallel),并且可以共享资源(例如,设备、内存变量和数据结构)。
- 多编程/多处理提高了系统利用率
线程可以在任何时间点(计时器、I/O)被中断。
- 进程状态保存在进程控制块(process control block)中
项目的结果可能变得不可预测:
- 共享数据可能会导致不一致——我们可能会在做某事的过程中被打断。
- 执行的结果可能取决于代码在CPU上运行的顺序。
例子
递增计数器
#include <stdio.h>
#include <pthread.h>
int counter = 0;
void* calc(void* param) {
int const iterations = 50000000;
for(int i = 0; i < iterations; i++)
counter++;
return 0;
}
int main() {
pthread_t tid1 = 0,tid2 = 0;
pthread_create(&tid1, NULL, calc, 0);
pthread_create(&tid2, NULL, calc, 0);
pthread_join(tid1,NULL);
pthread_join(tid2,NULL);
printf("The value of counter is: %d\n", counter);
}
这段 C 程序是一个典型的 多线程竞态条件(Race Condition)示例,它创建了两个线程同时对同一个全局变量 counter 进行累加操作,最终打印 counter 的值。
-
#include <stdio.h> #include <pthread.h>引入标准输入输出库和 POSIX 线程库(pthread)。
-
int counter = 0;全局变量
counter,初始值为 0,两个线程都会访问并修改它。 -
线程函数:
void* calc(void* param) { int const iterations = 50000000; for(int i = 0; i < iterations; i++) counter++; return 0; }每个线程都会执行这个函数。
每个线程将
counter自增 50,000,000 次。 -
主函数:
int main() { pthread_t tid1 = 0, tid2 = 0; pthread_create(&tid1, NULL, calc, 0); pthread_create(&tid2, NULL, calc, 0); pthread_join(tid1, NULL); pthread_join(tid2, NULL); printf("The value of counter is: %d\n", counter); }创建两个线程
tid1和tid2,都执行calc。pthread_join等待两个线程执行完毕。打印
counter的值。
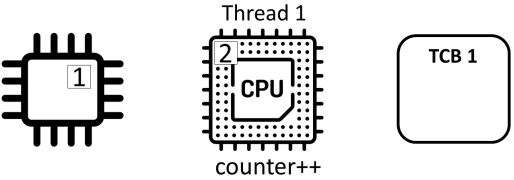
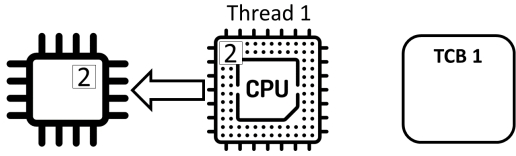
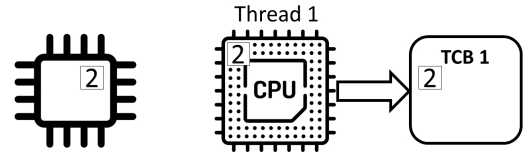
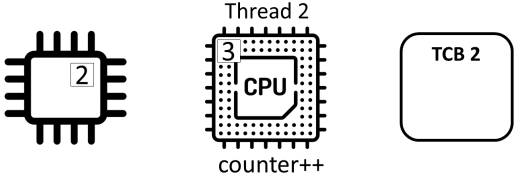
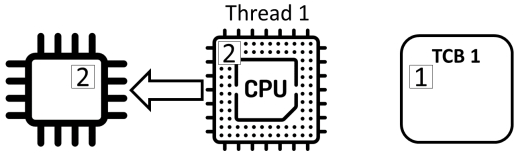
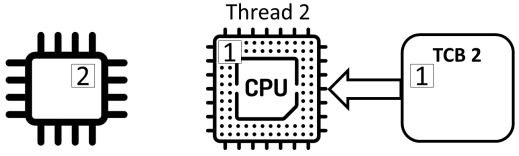
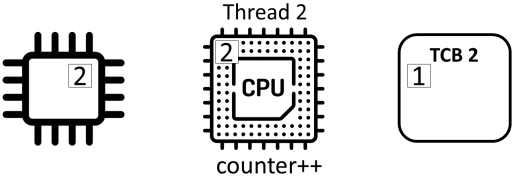
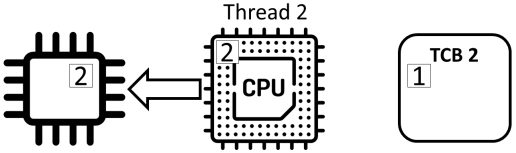
Counter ++不是原子(“atomic”)操作,而是由三个独立的动作组成:
- read: 从内存中读取计数器的值并将其存储在寄存器中
- add: 对寄存器中的值加1
- store: 将寄存器的值存储在内存中的计数器中
示例:
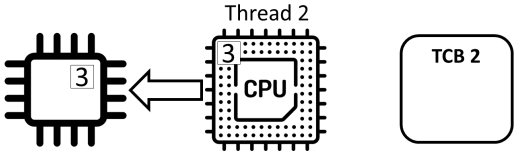
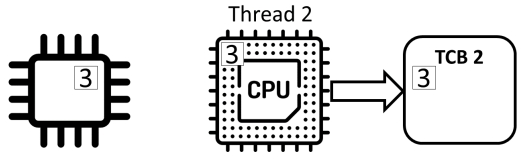

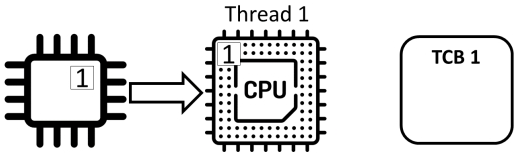
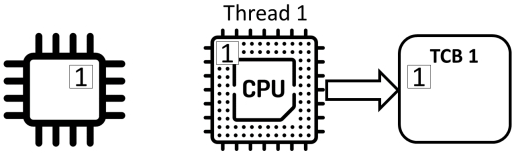
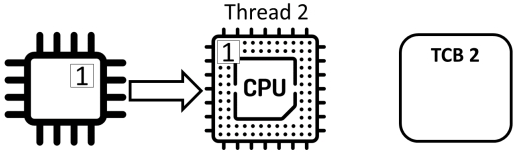
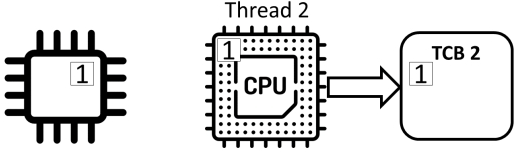
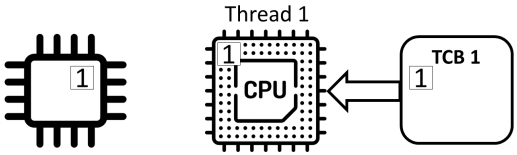
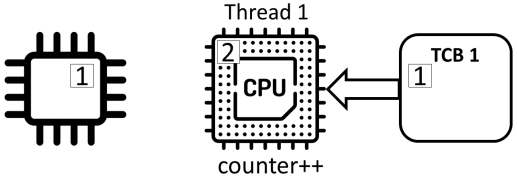
共享程序
考虑以下线程/进程之间共享的代码
chin 和 chout共享全局变量
void print()
{
chin = getchar();
chout = chin;
putchar(chout);
}
考虑两个进程/线程和以下交错的指令序列(它们不相互作用):

考虑两个进程/线程和以下交错的指令序列(它们确实相互作用):

有界缓冲区
考虑一个有界缓冲区,其中可以存储N个项目
维护一个计数器来计算当前缓冲区中的项数
- 添加项时递增
- 删除项时自减
当多个线程读写有界缓冲区时,也会出现与计算总和类似的并发性问题。
生产者/消费者:用 counter 记录当前缓冲区中的数据项数。
// producer
while (true) {
while (counter == BUFFER SIZE);
buffer[in] = new_item;
in = (in + 1) % BUFFER_SIZE;
counter++;
}
// consumer
while (true) {
while (counter == 0);
consumed = buffer[out];
out = (out + 1) % BUFFER_SIZE;
counter--;
}
但它有两个关键缺陷:
-
竞态条件(Race Condition)
生产者和消费者是两个线程,counter、in、out、buffer[]都是共享变量,而所有读写操作都没有加任何同步原语(锁、信号量等)。
例如:-
两个线程同时修改
counter; -
一个线程在读
buffer[out]的同时,另一个线程可能正在写buffer[in],甚至in == out时造成数据覆盖或读取脏数据。
-
-
忙等(Busy-waiting)
while (counter == BUFFER_SIZE);和while (counter == 0);属于轮询方式,会 100 % 占用 CPU,浪费资源。
竞态条件(Race Conditions)
如果代码的行为依赖于执行计算的时间,则代码具有竞态条件。
当多个线程访问共享数据时,通常会出现竞争条件,并且结果依赖于指令交错的顺序。
我们将对提供同步访问数据和避免竞争条件的机制感兴趣。
操作系统中的并发性
数据结构
现在的核心程序是抢占式的
- 内核中正在运行多个线程。
- 内核代码可以在任何时候被中断。
内核维护数据结构,如进程表和打开文件列表:
- 这些数据结构可以并发访问。
- 这可能会受到并发性问题的影响。
操作系统必须确保操作系统内部的交互不会导致竞争条件。
临界区和互斥
由于竞态条件可能导致疯狂的、不可预测的和明显的错误行为,我们希望软件抽象能够帮助防止它们。
临界区(critical section)是一段一次只能由一个线程运行的代码。这种性质被称为互斥(mutual exclusion)。
临界区
在编程中访问共享资源的一段代码,这段代码不能同时被多个执行线程访问。
互斥
在计算机科学中,指一种同一时间只允许一个进程或线程访问共享资源的机制。
那么问题就变成了如何执行互斥?潜在的方案:
- O/S和编译器可以将临界区作为程序设计基本指令提供直接支持。
- O/S和编译器提供的锁一次最多只能由一个线程持有。
互斥
do {
...
// ENTRY to critical section
critical section, e.g.counter++;
// EXIT critical section
// remaining code
...
} while (...);
临界区问题的解应满足以下要求:
- 互斥:在任何一个时间点,只有一个进程处于临界段
- 进程:任何进程都必须能够在某个时间点进入其临界区域。“剩余代码”中的进程/线程不会影响对临界区的访问
- 公平/有限等待:公平分配的等待时间/进程不能无限期地等待
这些要求必须得到满足,与计算执行的顺序无关
强制互斥
强制互斥的标准方法是通过称为互斥锁(mutexes)的锁。这些可以通过各种方式实现:
- 基于软件:Peterson的解决方案
- 基于硬件:test_and_set(), swap_and_compare()
- 基于O/S的——操作系统阻塞等待锁的进程。
不幸的是,互斥锁和其他并发原语(如信号量(semaphore))引入了一个新问题——死锁(deadlocks)。
死锁
例子
假设X和Y是互斥体(mutexes)。
线程A和线程B需要同时获取互斥锁,并以相反的顺序请求它们。
以下一系列事件可能发生在多程序系统中:

定义
如果一组线程中的每个线程都在等待只有该组中的另一个线程才能引起的事件,则该组线程被死锁
- 每个死锁线程都在等待另一个死锁线程持有的资源(该线程不能运行,因此不能释放资源)。
- 这可以发生在任意数量的线程之间和任意数量的资源上
最小条件
发生死锁必须满足四个条件:
- 互斥:一个资源一次最多只能分配给一个进程
- 保持和等待条件:资源可以在请求新资源时被保持
- 无抢占:不能从进程中强制拿走资源
- 循环等待:存在一个由两个或多个进程组成的循环链,等待其他进程持有的资源
如果不满足其中一个条件,则不会发生死锁
如果您的课程作业解决方案出现死锁,请检查请求资源的顺序
理解
1. x != y 会不会“原子地”发生?
不会。
即使表达式本身“只读”,它也要先把 x 和 y 的值从内存读到寄存器,再比较。
在大多数 ISA 上,这至少是两到三条指令:
load r1, [x] ; 读 x
load r2, [y] ; 读 y
cmp r1, r2 ; 比较
如果另一个线程在这两条 load 之间把其中某个变量改掉,比较结果就可能“过时”。
因此读操作也需要同步(加锁、原子变量或 memory barrier)才能保证一致性。
2. 在“单硬件线程”的机器上会不会出现竞态或死锁?
-
竞态条件
如果操作系统做时间片抢占式调度,即使只有一个物理核,两个线程仍会在不同时间片里交替运行,因此竞态条件依旧可能触发。 -
死锁
死锁只需要“占有且等待”的四条件成立,与 CPU 个数无关。
因此单核也能死锁——典型场景:线程 A 占锁 L1 后阻塞,线程 B 占锁 L2 后想去拿 L1,于是互相等待。
3. 两个线程跑同一个函数会不会互相死锁?
可能,也可能不会,关键在于函数里如何申请锁。
-
如果函数内部只用一把递归锁(或根本没锁),当然不会死锁。
-
如果函数内部按固定顺序先后拿两把锁,也不会死锁。
-
如果函数内部按不同顺序拿锁(例如线程 1:先 L1 后 L2,线程 2:先 L2 后 L1),就可能形成循环等待,从而死锁。
因此,“函数相同”本身不会阻止死锁;真正决定是否死锁的是锁的获取顺序和策略。

















 894
894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









