



Datawhale发布
最新发布:Dexmal 原力灵机
在人工智能突破认知智能的边界后,全球研究界已将目光聚焦于具身智能(Embodied AI)。
这里的挑战不再是生成文本或图像,而是让机器人真正获得与物理世界交互、完成复杂任务的能力。
实现这一跨越的关键,在于视觉-语言-动作模型(VLA)。它就像AI的“手脑中枢”,负责把人类的口头指令,转化为机器人在物理世界中精确的抓取、移动等操作。
然而,对于每一个投身 VLA 前沿的团队而言,都无法逃脱三大工程化难题的困扰。这些难题,正在将宝贵的创新时间,浪费在无休止的“重复造轮子”上。
第一,环境配置碎片化。
具身智能研究就像搭城堡,但各团队使用的砖块标准不一,论文复现、产学协作自然就成为了难题。当研究人员想要对比当下最火的SOTA算法,比如 Pi0、CogACT 或 OFT 时,必须配置 2-3 套完全独立的深度学习环境。Python、PyTorch、CUDA 版本之间的冲突就会很常见,消耗大量的研究时间,被消耗在与核心算法毫无关系的工程基建上。

第二,模型更新起来不方便。
VLA 模型的能力高低,全看它这颗 VLM(视觉-语言大模型)大脑的聪明程度。遗憾的是,由于环境配置和迁移成本太高,很多 VLA 项目至今还在用几年前的旧版 VLM,比方说 Llama 2 作为基础。这使得研究人员无法及时享受 Qwen3、PaliGemma2 等新一代通用模型带来的认知飞跃和泛化能力。当通用 AI 日新月异时,具身智能的“智商”却被旧组件拖了后腿,成为了性能提升的一大瓶颈。
第三,数据格式难统一。
机器人数据非常宝贵,但它们都被锁在了不同的保险柜里。不论是 Open-X Embodiment、Robomind 等大型数据集,还是那些不同的硬件平台,都采用着各自为政的数据格式。这就会导致:

5家具身智能开源数据集基本情况梳理,图源:机器觉醒时代
数据像被割裂的孤岛,在跨任务、跨平台的大规模通用模型训练时难上加难。在数据和算法都如此碎片化的情况下下,科研协同性又如何能得到保证?
正是洞察到这些痛点,由 Dexmal 原力灵机重磅推出的 Dexbotic,以一套视觉-语言-动作模型工具箱(VLA Toolbox),针对这三大问题提出了解法。而且,全面开源。
官网:https://dexbotic.com/
论文:https://dexbotic.com/dexbotic_tech_report.pdf
GitHub:https://github.com/Dexmal/dexbotic
HuggingFace:https://huggingface.co/collections/Dexmal/dexbotic-68f20493f6808a776bfc9fc4
Dexbotic 真正想表达的是:它不只是一个工具,而是要成为具身智能领域的基础设施,将 VLA 研究从“重复造轮子”的泥潭中彻底解救出来。
核心创新一:实验导向型开发框架
传统的 AI 框架,配置的起点往往是复杂的 YAML 文件,就像要你填一张有几百个空格的表格。微调一个参数,就要在像迷宫一样的配置层级中,反复查找和修改,极其繁琐。
Dexbotic 则把视角放在了最核心的“实验脚本”上。
它创新性地采用了「实验为中心(Experiment-Centric)」的开发框架。
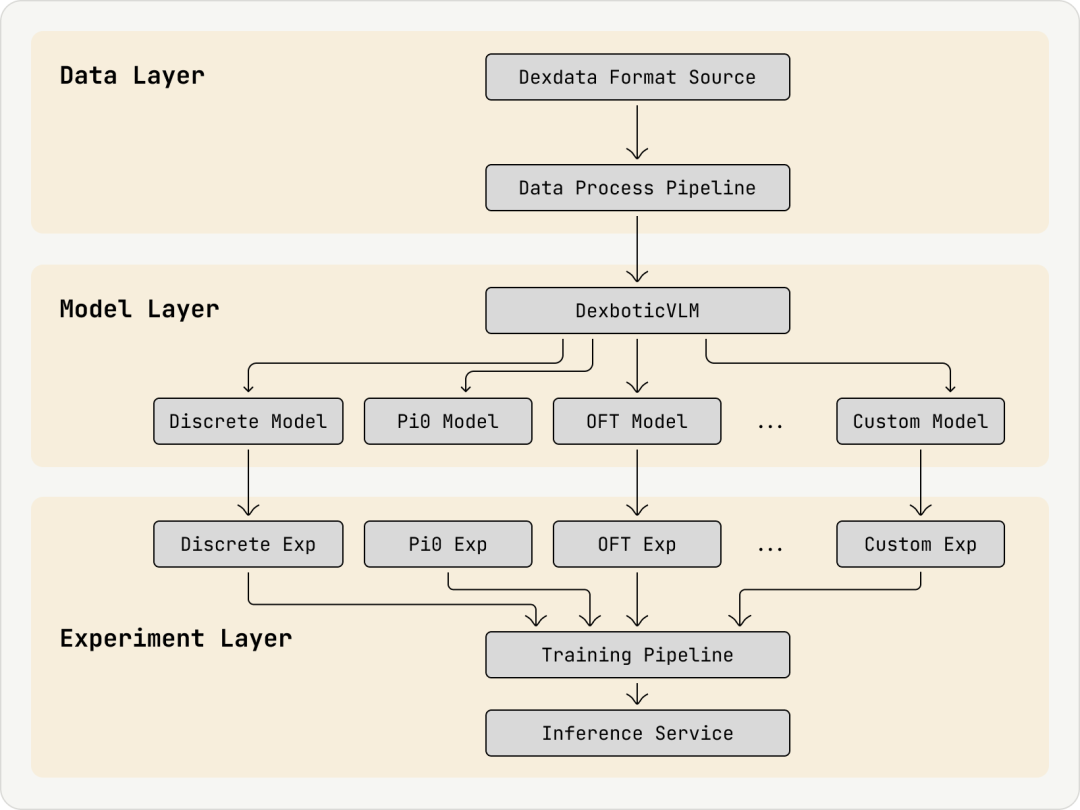
其核心是清晰的三层架构:
Data Layer(数据层): 负责将所有异构数据统一处理为 Dexdata 格式。
Model Layer(模型层): 负责 VLM 和 AE 的模块化和策略组装。
Experiment Layer(实验层): 负责实验的快速定义、配置和运行。
使用者只需继承一个基础脚本(base_exp),再通过 Python 脚本修改极少数的差异化参数(如学习率、特定模型组件)就可以开展新的实验。举个例子,从复现 CogACT 切换到 OpenVLA-OFT,不再需要重写配置文件或重建环境,只需切换或修改一行脚本即可。
但是,易改常伴随着易错。享受超快的速度启动和切换实验时,随之而来的挑战是:怎么快速诊断新模型或新配置带来的失败呢。

研究团队想到了这一点,不仅提供了运行环境,更内置了一套强大的诊断工具:它通过统一日志自动记录每一次实验配置和决策流程,并通过视频回放一键生成动作视频,直观看清成功/失败全过程。
核心创新二:积木式架构与统一数据格式
光有环境还不够,为了让一个环境能够兼容所有主流 VLA 算法,Dexbotic 采取了提供“标准接口”和“统一格式”的策略,打造了清晰、高度解耦的模块化“积木”架构。
VLA 策略的两块标准积木: Dexbotic 将 VLA 策略解耦为视觉-语言模型(VLM,AI 的“认知”)和动作专家(Action Expert, AE,AI 的“执行”)两个核心模块。这种“积木式”设计,让使用者可以灵活地更换其中的任意一个模块,从而快速构建或复现新的 VLA 策略。
核心通信机制——统一的备忘录: Dexbotic 模块化设计的灵魂。 想象一下上面解耦之后的机器人“大脑” (VLM) 和“双手” (AE) 是两个独立的专业部门。
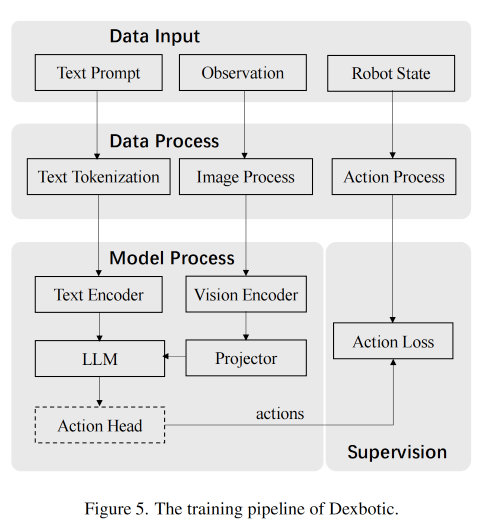
VLM 的工作: 接收人类的复杂指令和机器人看到的实时画面。它负责复杂的理解、推理和规划。
VLM 的输出: 它不会直接输出机器人的关节角度,这太复杂了,而是输出一份高度凝练的统一备忘录。这份备忘录标准且清晰,相当于AI抽象出来的一个中间决策。以「把红色的积木放进蓝色的盒子」的动作为例,这个中间决策就是:目标是抓取桌面上的红色物体,并移动到坐标 X, Y, Z。
AE 的工作: 它只需要阅读这份标准备忘录,然后将 X, Y, Z 这样的抽象目标,转化为机器人所需的精确 Delta坐标或扭矩,完成细腻的抓取动作。
这种「只负责思考」和「只负责执行」的清晰分工,以及它们之间通过标准“备忘录”进行的通信,是实现 VLA 策略快速组装和研究迭代的关键。
统一数据格式(Dexdata): 面对多源、异构数据,Dexbotic 定义了 Dexdata 统一格式。

它以高效的视频(video)和 jsonl 文件形式存储机器人数据集,能有效节省存储空间,并简化了数据处理流程。更酷的是,它从设计之初就考虑到了未来的全身控制、复杂交互,为人形机器人的研究预留了接口扩展能力。
核心创新三:自有的高性能基础模型
如果说工程框架是「身体」和「骨架」,那么高性能的预训练模型就是 VLA 的「大脑」和「引擎」。
Dexbotic 从头预训练了自有的基础模型——DexboticVLM。它使用 CLIP 作为视觉编码器、两层 MLP 作为投影器,并集成了 Qwen2.5 作为 LLM,确保 VLA 模型能够立即获得当前最优的跨模态对齐和强大的语言理解能力。
这种 “最新 VLM + 高性能预训练” 的组合,在实战中带来了巨大的性能提升:
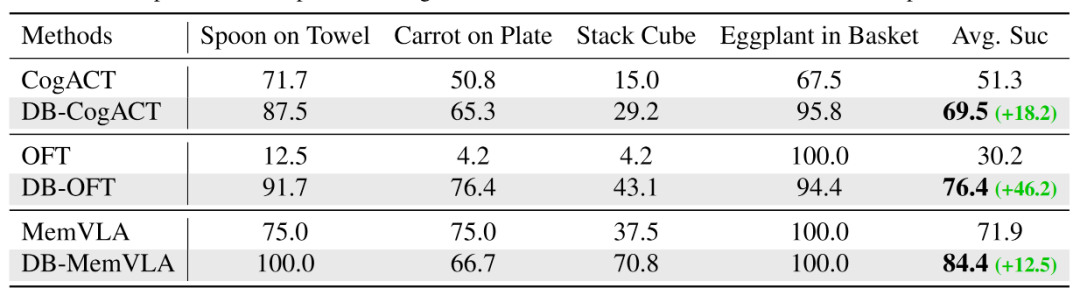
在 SimplerEnv 基准测试上: 基于 Dexbotic 预训练模型的 db-CogACT 成功率比官方 CogACT 绝对提升了 18.2%(从 51.3%提升到 69.5%)。db-OFT 相比官方 OpenVLA-OFT 更是取得了 46.2% 的绝对提升(从 30.2% 提升到 76.4%)。
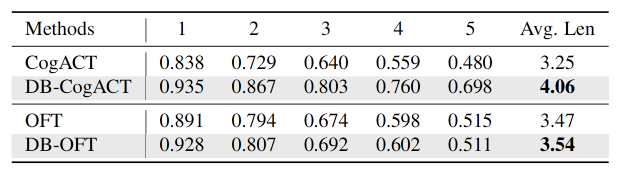
在 CALVIN 长时序任务中: db-CogACT 在所有指标上均超越了官方模型,平均任务完成长度从 3.25 优化到 4.06。
这不仅是数字上的提升,更意味着 VLA 模型在复杂、长时序任务中「更聪明」、「更可靠」。
扩展生态:开源硬件 DOS-W1
除了VLA算法,具身智能的研究发展也离不开硬件的支撑。有鉴于此,Dexmal 原力灵机也推出了其首款开源硬件产品——Dexbotic Open Source - W1(DOS-W1)。

它采用了大量的快拆结构与可替换模块,还为了提升操作人员的舒适度与数据采集效率,专门进行了人体工学的抗疲劳设计。同样的,也是完全开源!即将开源所有的文档、BOM、设计图纸、组装方案、相关代码。
据悉,Dexmal 原力灵机也将与各产业伙伴一起,持续丰富 Dexbotic Open Source 系列,以开源硬件助力具身智能前沿研究,加速机器人技术在真实物理世界的落地与应用。
结论:将创新从工程中解放
能聊天的 AI 已经足够多,世界需要更多能干活的 AI。
Dexbotic 所扮演的角色,正是具身智能领域的 “效率革命者”:它通过统一的代码架构、统一的数据格式和高性能的预训练权重,使得全球研究者能够在一个相同的、最优化的环境下,公平、快速地复现和对比各种前沿 VLA 算法。
当研究者可以将 100% 的精力投入到「如何让机器人更智能地行动」,而不是「如何让我的环境跑起来」时,我们有理由相信,具身智能的技术浪潮,将以前所未有的速度席卷而来。
上周,Dexbotic 原力灵机联合 Hugging Face 推出全球首个大规模、多任务真机评测平台 RoboChallenge,正是检验 VLA 算法真实能力的最终平台。Dexbotic 工具箱提供的统一环境和高性能模型,将成为研究者高效参与 RoboChallenge 的技术基础,助力算法快速通过高难度、长时程的真机任务,从而在真实世界中验证和孵化出更具颠覆性的 VLA 创新。
现在,是时候将你的创新算法交给 Dexbotic,去开启下一代具身智能的飞跃了。
10月23日晚 19:00,Dexmal 原力灵机创始团队成员汪天才将现身直播间,讲解开源一站式 VLA 工具箱 Dexbotic,欢迎大家扫描图中二维码预约观看、线上交流 : )


一起“点赞”三连↓

















 1531
1531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









