



Datawhale分享
关于:Deep Research,来源:PaperAgent
前几天,阿里开源了Tongyi DeepResearch,热度很高,目前14.1k star了!
开源地址:https://github.com/Alibaba-NLP/DeepResearch
关于Deep Research背后更全面的技术栈都有哪些?今天分享两篇最新的Deep Research技术综述:
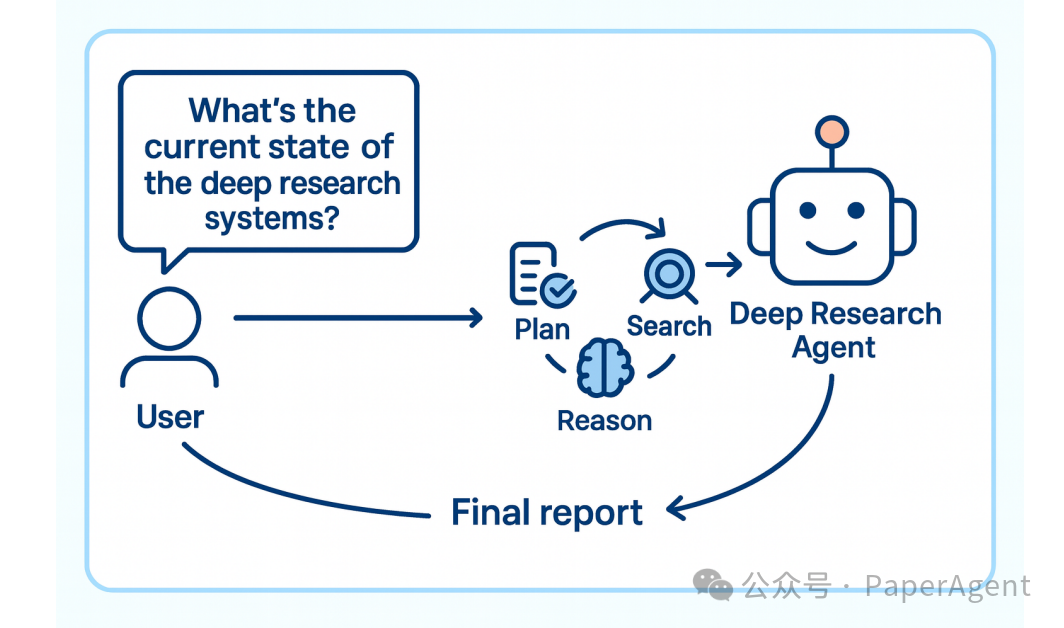
传统大模型虽然强大,但受限于静态知识边界,面对开放、动态、复杂的科研任务时往往力不从心。为此,Deep Research 应运而生:

一种让智能体主动探索、动态推理、生成可靠报告的代理研究新范式。
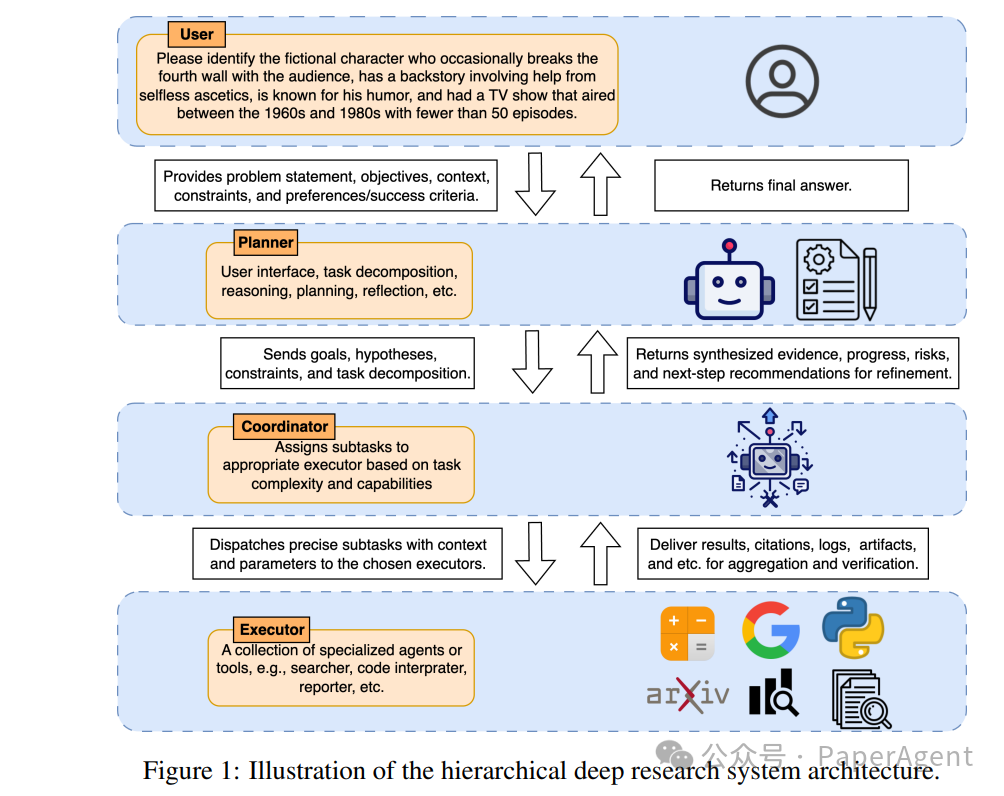
它不再是“问答机”,而是“能自己找资料、写综述、做分析”的AI研究员。
Deep Research 的四大核心模块
一个完整的 Deep Research 系统应包括以下四个阶段:
模块 | 功能 | 关键挑战 |
|---|---|---|
| Planning | 将用户问题拆解为可执行的研究子目标 | 如何生成结构化、可解释的研究路径? |
| Question Developing | 为每个子目标生成多样化、上下文相关的检索查询 | 如何平衡查询的准确性与覆盖度? |
| Web Exploration | 主动调用搜索引擎、浏览网页、提取信息 | 如何过滤冗余、识别可信来源? |
| Report Generation | 整合证据,生成结构清晰、事实可靠的报告 | 如何控制结构一致性与事实一致性? |
图1:Deep Research 系统架构概览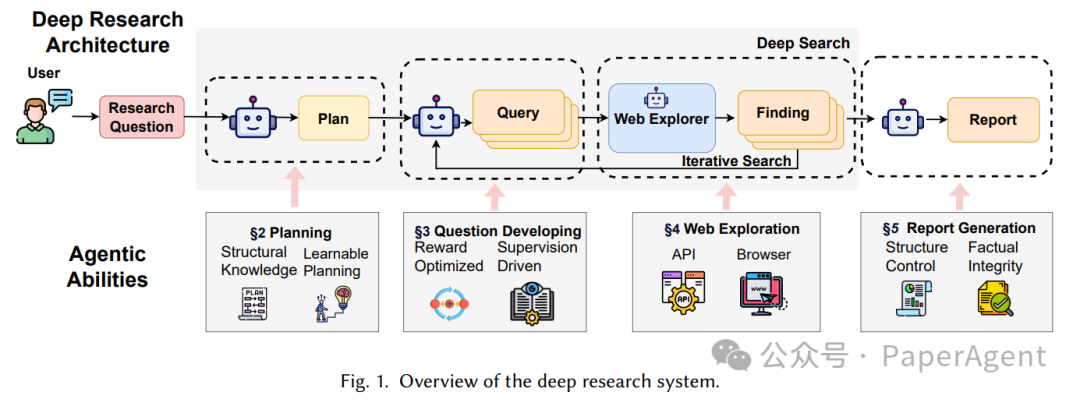
📊 Planning(研究规划)
✅ 目标
将模糊、开放的研究问题转化为可执行的研究计划,如子问题、检索顺序、证据整合策略。
🔧 方法分类
类别 | 方法示例 | 特点 |
|---|---|---|
结构化世界知识 | Simulate Before Act、WebPilot | 利用外部知识图谱或模拟器进行预演 |
可学习规划 | AgentSquare、MindSearch | 通过RL或搜索自动优化规划策略 |
🔍 Question Developing(问题演化)
✅ 目标
将每个子目标转化为多个高质量检索查询,提升信息召回率与相关性。
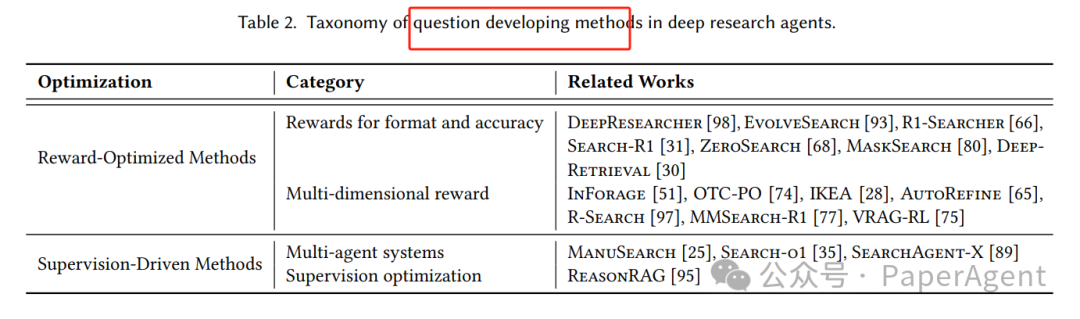
🔧 方法分类
类别 | 方法示例 | 特点 |
|---|---|---|
奖励优化类 | DeepResearcher、R1-Searcher | 用RL优化查询生成策略 |
监督驱动类 | ManuSearch、SearchAgent-X | 基于规则或多Agent协作生成查询 |
🌐 Web Exploration(网页探索)
✅ 目标
主动与网页交互,检索、浏览、提取、过滤信息,支持多轮迭代。
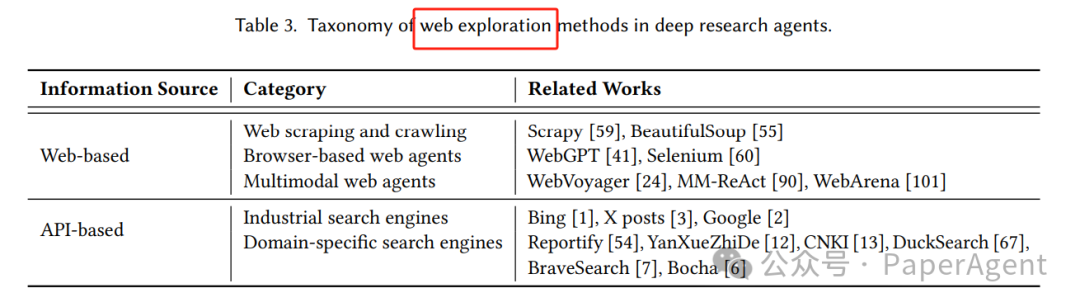
🔧 方法分类
类型 | 方法示例 | 特点 |
|---|---|---|
网页Agent | WebGPT、WebVoyager | 模拟人类浏览行为,支持点击、表单、导航 |
API检索 | Bing/Google Search API | 快速、稳定,适合结构化查询 |
🧾 Report Generation(报告生成)
✅ 目标
将碎片化证据整合为结构清晰、逻辑连贯、事实可靠的研究报告。
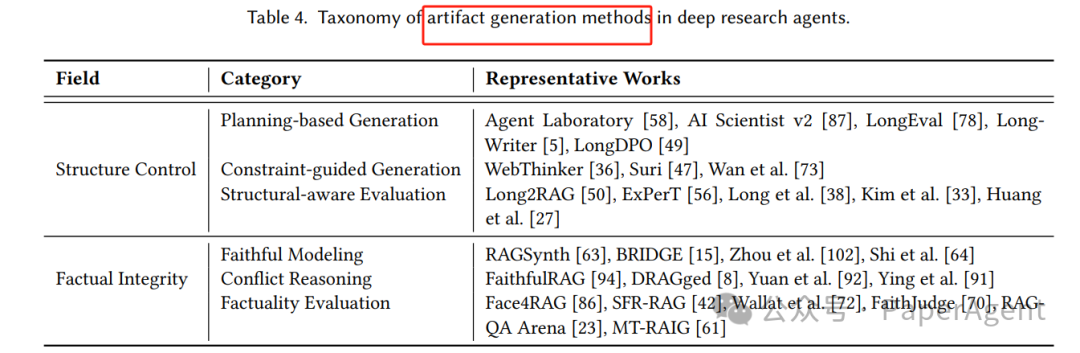
🔧 方法分类
类别 | 方法示例 | 特点 |
|---|---|---|
结构控制 | Agent Laboratory、WebThinker | 通过大纲、约束、模板控制生成结构 |
事实一致性 | FaithfulRAG、DRAGged | 引入冲突检测、证据对齐、引用验证机制 |
优化:如何让 Deep Research 更靠谱?

传统的大模型问答=“背答案”;
真正的深度研究=多步规划 → 问题演化 → 工具调用 → 结构化报告。
SFT/DPO 只能“模仿”人类轨迹,无法闭环利用环境反馈(搜索失败、网页失效、预算超限)。
RL 用轨迹级奖励直接优化“端到端任务成功”,天然契合“工具-交互”研究场景。
方法 | 优化目标 | 数据形式 | 关键短板 |
|---|---|---|---|
SFT | 模仿单步 | (q, a) 对 | 暴露偏差、无法纠错 |
DPO | 偏好排序 | (q, a⁺, a⁻) | 无状态、信用分配短视 |
RL | 最大化回报 | (q, τ, r) | 需可验证奖励+探索策略 |
数据:RL的“燃料”怎么炼?
提出 Construct → Curate → Curriculum 三段式流水线:
策略 | 代表工作 | 核心技巧 |
|---|---|---|
| 跨文档合成 | WebPuzzle、R-Search | 把新鲜新闻+arXiv聚类→生成多跳问题,防止“背参数” |
| 图结构生长 | CrawlQA、WebSailor | 从维基/GitHub 根节点随机游走→按路径长度自动标难度 |
| 难度变换 | E2HQA、StepSearch | 用 LLM 迭代给原问题加约束,控制“跳数”与“证据密度” |
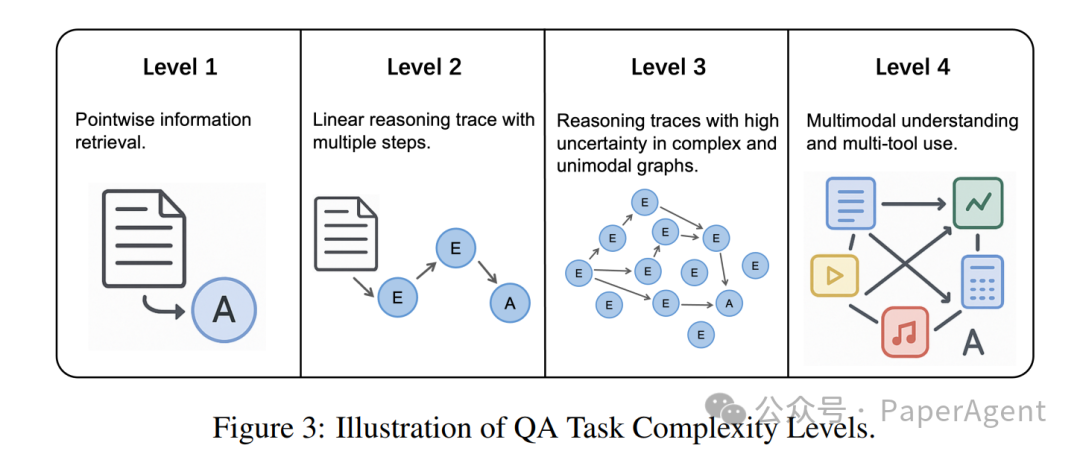
Level | 特征 | 示例数据集 |
|---|---|---|
L1 | 单点检索 | SimpleQA |
L2 | 线性多跳 | HotpotQA |
L3 | 高不确定性+复杂图 | SailorFog-QA |
L4 | 多模态+多工具 | WebWatcher |
奖励:拿什么信号训练“Agent”?
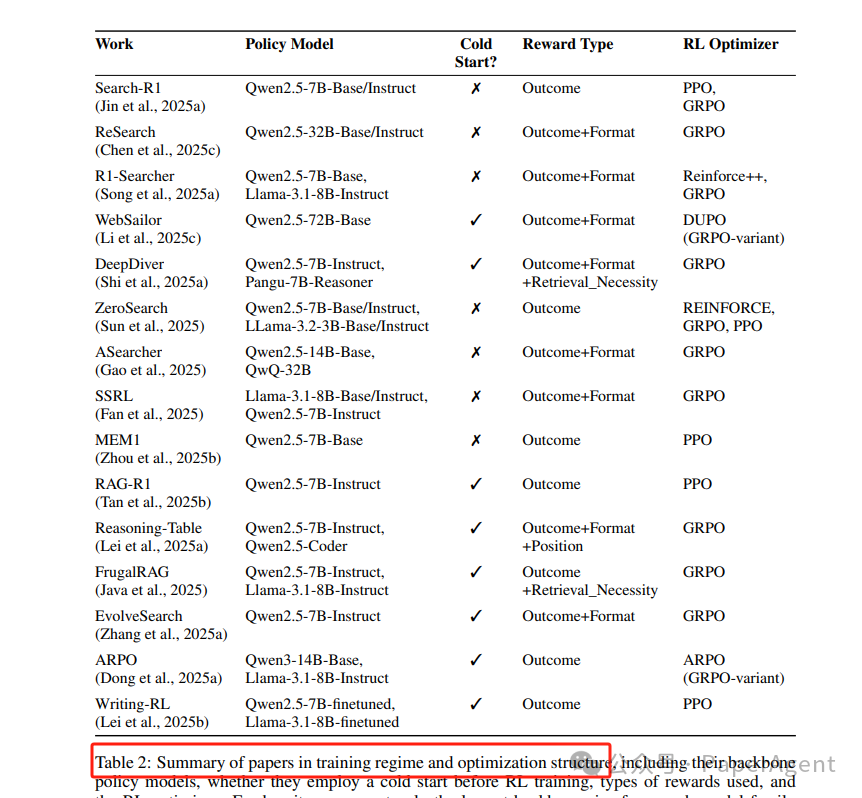
结果奖励(Outcome-only)
经典指标:EM/F1、LLM-as-Judge
新花样:
GBR(Gain-Beyond-RAG):相比“无脑 top-k RAG”的边际提升;
Evidence-Utility:用冻结 LLM 只看收集到的证据能否答对;
Group 相对节俭:同批次正确轨迹里检索次数最少得 bonus。
步骤奖励(Step-level)
工具执行奖励:MT-GRPO 给“成功调用+返回含答案片段”即时 bonus;
信息增益 - 冗余惩罚:StepSearch 用余弦增量衡量每轮收获;
多模态步骤:Visual-ARFT 对每轮图片裁剪→OCR→代码打分。
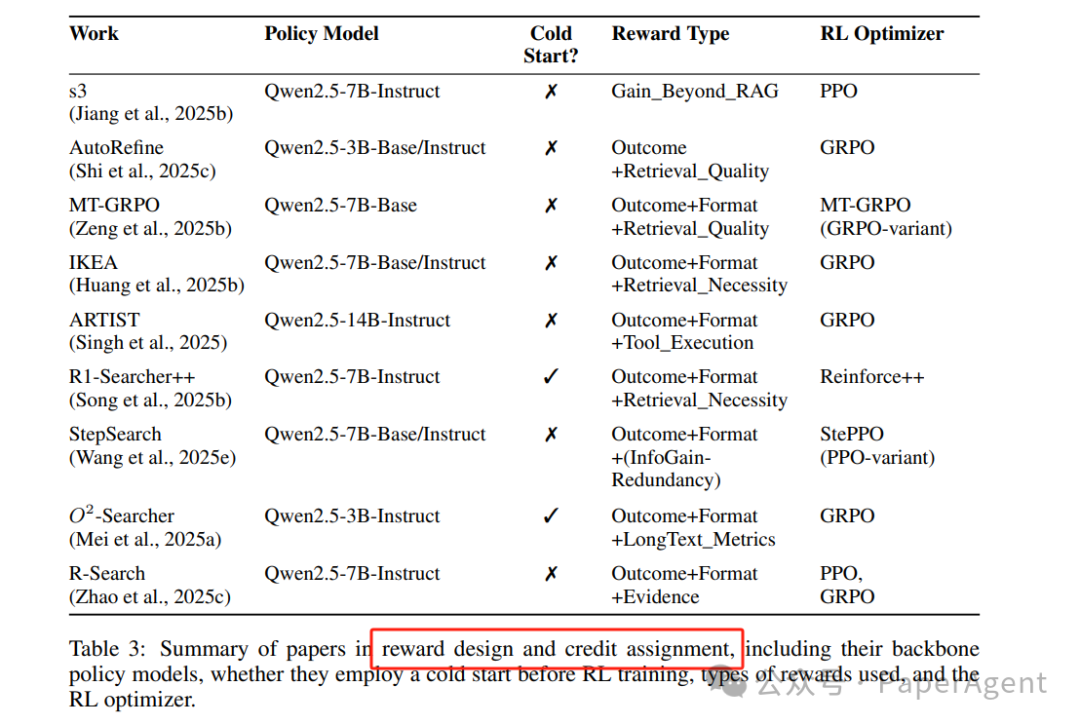
信用分配(Credit Assignment)
粒度 | 做法 | 代表 |
|---|---|---|
轨迹级 | 整条 τ 用 GAE | Search-R1 |
回合级 | 每轮混合即时+终端奖励 | MT-GRPO |
Token 级 | 工具调用边界挂奖励 | ARTIST |
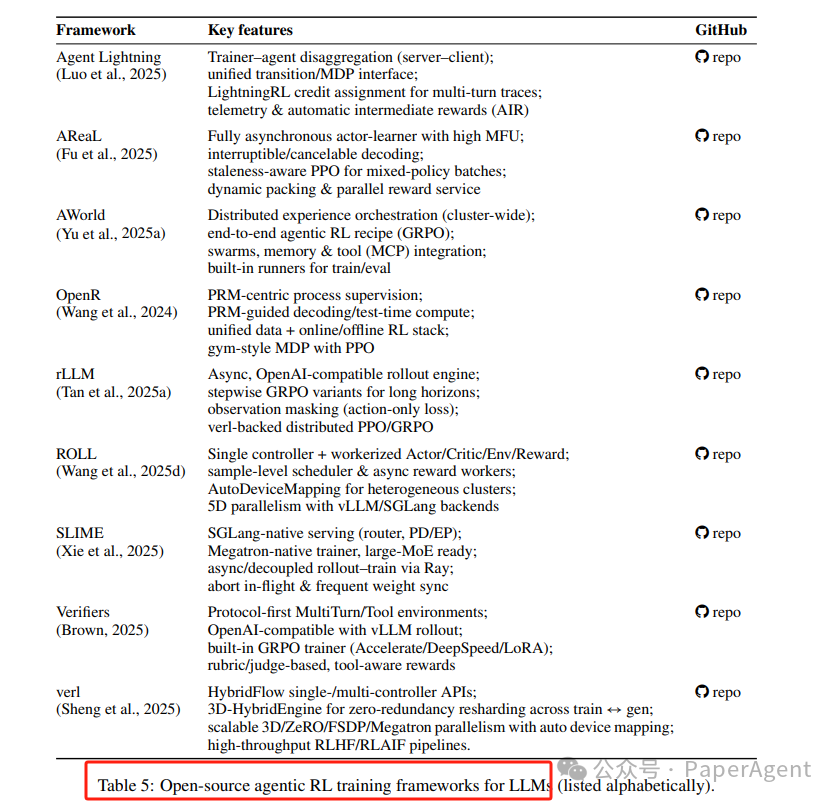
开源系统:让RL训练“跑得动”
长工具链 = 高延迟 + 大显存 + 策略过期。2025 新框架亮点:
论文1:https://arxiv.org/pdf/2509.06733
Reinforcement Learning Foundations for Deep Research Systems: A Survey
论文2:https://arxiv.org/abs/2508.12752
Deep Research: A Survey of Autonomous Research Agents

一起“点赞”三连↓

















 1294
1294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









