



Datawhale报告
作者:赵越,State-of-Datawhale项目
在2025年5-7月,Datawhale迎来了“爆炸性”的增长,共增长31861颗star,是Github所有同类型组织中涨幅最高的一个,全球排名前进11名,来到了53名,成为同类组织全球排名第5,国内排名第1的开源学习社区。
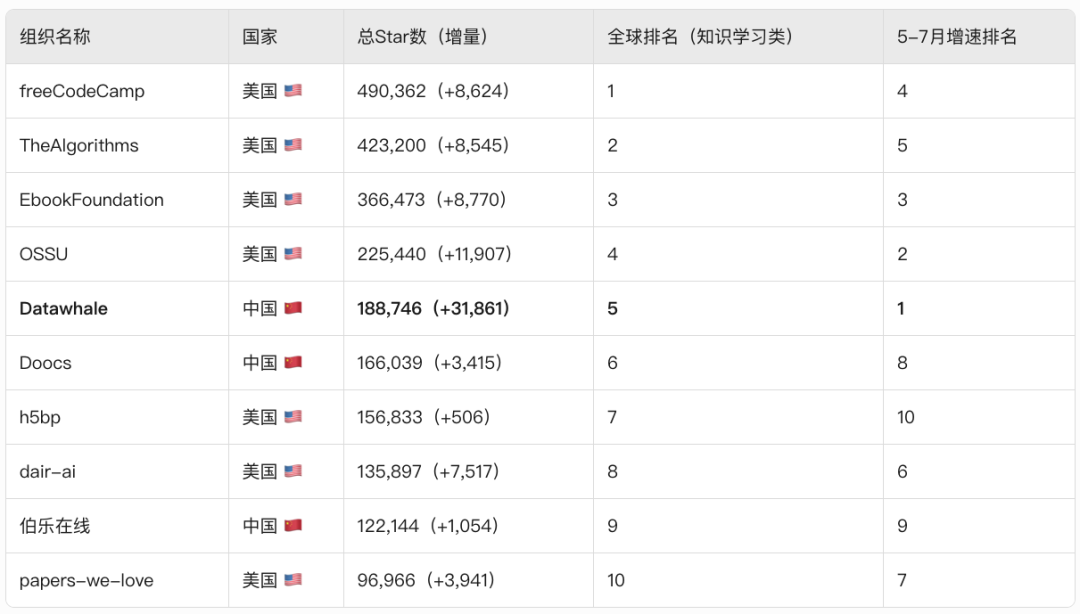
高速增长的背后原因
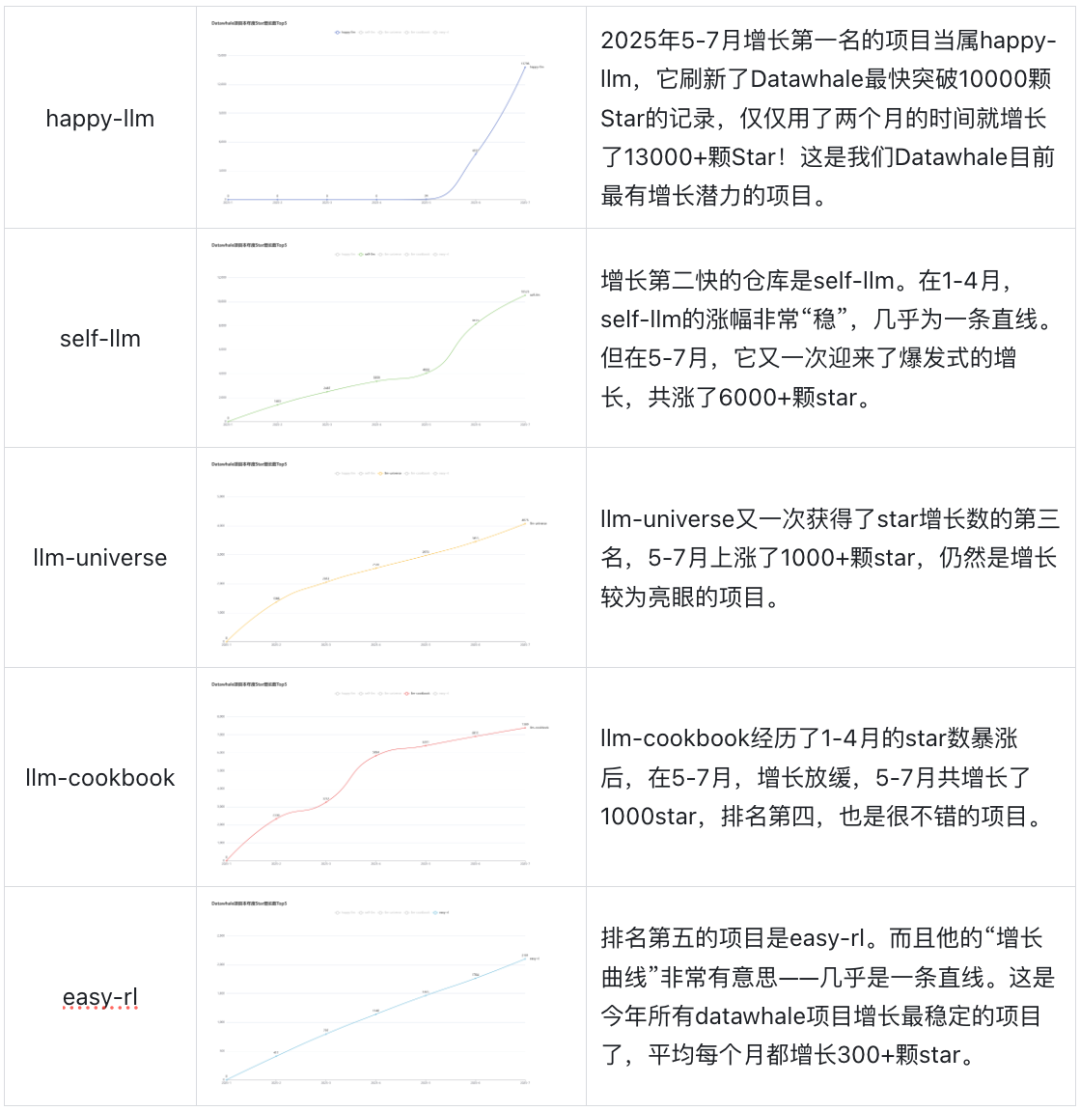
组织内star数涨幅靠前的项目均为大模型相关的项目,happy-llm直接刷新了Datawhale最快突破10000颗Star的记录,仅仅用了两个月的时间就增长了13000+颗Star!self-llm也迎来了一波新的爆发,共上涨6000+颗star,llm-universe,llm-cookbook,easy-rl这些优秀的仓库仍然保持了很优秀的star涨幅。
下面这个视频动态展示了2025年5-7月我们Datawhale中Star数超过1000的项目的Star增长情况:
增速最快的5个开源项目
组织内Star数涨幅靠前的项目均为大模型相关的项目,下面会选择在2025年5-7月中增长Star数最多的5个项目进行分析。
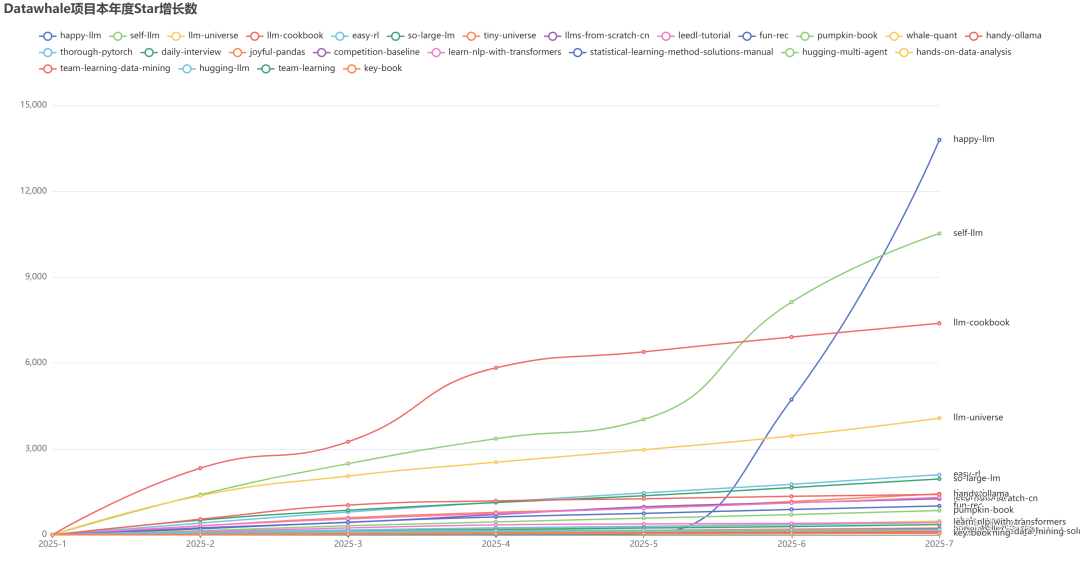
下图展示了今年Datawhale中Star数超过1000的项目的Star增长数:
贡献者列表:
数据源:
1. https://gitstar-ranking.com/organizations
2. https://star-history.com/
3. https://github.com/datawhalechina

一起“点赞”三连↓

















 1034
1034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









