



 本文是南昌航空大学大三学生分享的时序赛夺冠经验,通过分析赛题,提出了三种解题思路,包括时序特征构造、暴力特征衍生和统计特征构造。在实践中,统计特征对模型性能提升显著,但可能导致过拟合。作者通过模型融合和参数简化来缓解过拟合问题,最终在比赛中取得了冠军。
本文是南昌航空大学大三学生分享的时序赛夺冠经验,通过分析赛题,提出了三种解题思路,包括时序特征构造、暴力特征衍生和统计特征构造。在实践中,统计特征对模型性能提升显著,但可能导致过拟合。作者通过模型融合和参数简化来缓解过拟合问题,最终在比赛中取得了冠军。
Datawhale干货
作者:陈轶凡,南昌航空大学,冠军选手
笔者thefan,目前为一所双非学校的大三在读本科生,对数据挖掘以及计算机视觉感兴趣。2022年开始参加数据竞赛,曾获得过讯飞开发者大赛房屋租金预测竞赛的top2。
在2023 全球人工智能开发者先锋大会—AI 人才学习赛中拿到了冠军,特将方案分享,希望一起交流学习。
关注公众号,回复 “冠军方案” 获取完整可复现代码
赛题分析
赛事地址:
https://www.heywhale.com/home/competition/63be011bde6c0e9cdb12b965
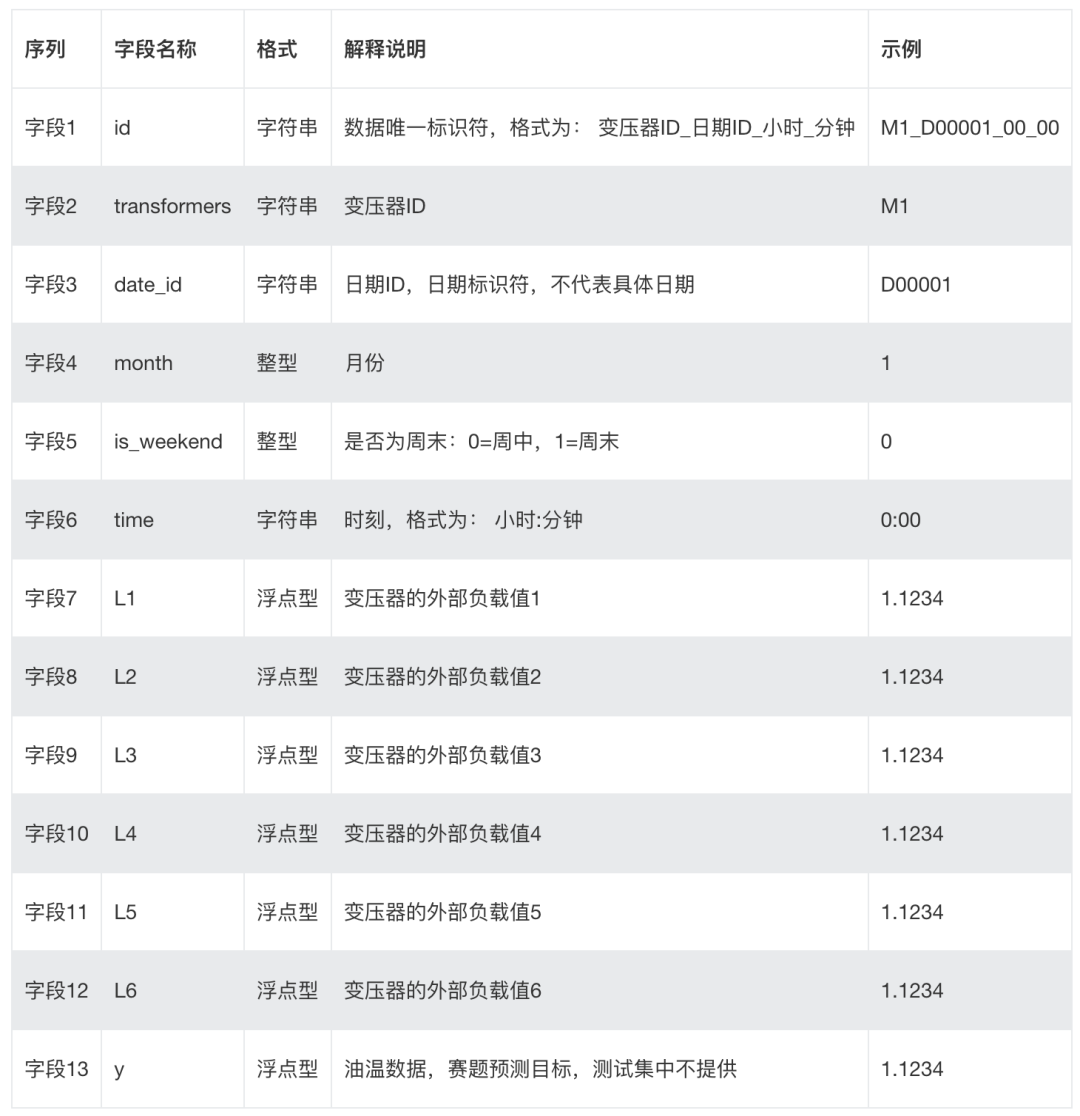
赛题数据的字段解释说明如下,可以看出这是一个时序回归任务。
我们需要探索油温与变压器运行的季节月份、时刻、外部负载等信息之间的关系。以构架一个模型来预测油温。
解题思路
大致看了一下数据发现:该赛题的连续性特征只有六个,分别为变压器的外部负载值的六个值(简称:L1-L6)。
由于对L1-L6具体含义不清晰,没办法对这其进行业务理解构造业务特征。于是,有以下3个对数据处理的思路:
思路1:对字段6:time按照时间顺序进行排序,然后对
L1-L6
构造时序特征;
思路2:对L1-L6进行
暴力特征衍生
;
思路3:对字段2-字段6进行groupby操作,再对L1-L6进行agg操作,计算出L1-L6的统计值。
思路复现
在对以上思路进行复现的时候发现:赛题虽然是时序回归任务,但可能是数据质量的问题,发现思路1和思路2可行性较低。
复现思路1:
如果对L1-L6构造时序特征,会导致分数的抖动非常大,并且在线下看来提升也并没有很大。
考虑到还有B榜,为了尽量能够在A、B榜换榜的时候分数抖动不会太大。便放弃了构造时序特征的想法。
复现思路2:
之后我又开始尝试了对L1-L6进行暴力特征衍生,但是结果显示效果并不是很好。
最开始我认为可能是特征维数太大,之后我便只保留了排名在特征重要性前面的特征进行训练,发现效果还是不是很好。
因此对L1-L6构造暴力衍生的特征我也放弃了。
复现思路3
之后我又尝试了统计特征构造,当我加入了统计特征之后我线下的mse从300多下降到了60多,并且单纯用统计特征线上的分数就能到260+。
但这样做的风险为线下过拟合太严重了,因为我线下的mse下降了200多,对应线上的分数才下降30多。
因此我为了在A、B榜换榜的时候分数不会抖动太大,我决定:
对模型的参数不进行细粒度的调整;
使用多个模型进行融合。
代码复现
确认了上述实现思路后,现在对各个模块进行详细的解析。
统计特征的构造
在统计特征的构造的过程中,我对一些提升不大的并且重要性偏低的统计特征进行了删除.
最后所用到的特征构造代码如下:
def brute_force(df, features, groups):
for method in tqdm(['mean', 'std', 'median']):
for feature in features:
for group in groups:
df[f'{group}_{feature}_{method}'] = df.groupby(group)[feature].transform(method)
return df
dense_feats = ['L1', 'L2', 'L3', 'L4', 'L5', 'L6']
cat_feats = ['date_id', 'month', 'time']
df = brute_force(df, dense_feats, cat_feats)标签y值的处理
对于y值,基于经验我一般都会对标签做log平滑处理。
因为该赛题的标签y值最小值为-4+,因此并不能按照常规的log1p(y)的方法对y值进行平滑处理,而应该将其替换为log(y + 5)。并且在预测完之后使用np.exp(y) - 5对预测值进行还原。
具体代码如下:
# 对y值进行平滑处理
y = np.log(df_train['y'] + 5)
# 将预测值进行还原
test['y'] = np.exp(prediction_lgb) - 5模型的选择以及参数的选择
由于在加入了统计特征之后,过拟合太明显了,因此在模型的选择上没有选择更容易过拟合的nn模型,而是选择了常规的树模型。
最终,我选择了lgb和catboost两个常用的模型对数据进行拟合预测。在参数上我没有对参数进行细致的调整,直接用的是我一直以来喜欢用的参数。
lgb模型参数:
params = {
'learning_rate': 0.05,
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'mae',
'feature_fraction': 0.7,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'seed': 2022,
}catboost模型参数:
cbt_model = CatBoostRegressor(iterations=100000,
learning_rate=0.05,
eval_metric='MAE',
use_best_model=True,
random_seed=42,
logging_level='Verbose',
task_type='GPU',
devices='0',
gpu_ram_part=0.5,
early_stopping_rounds=200)缓解过拟合的思考
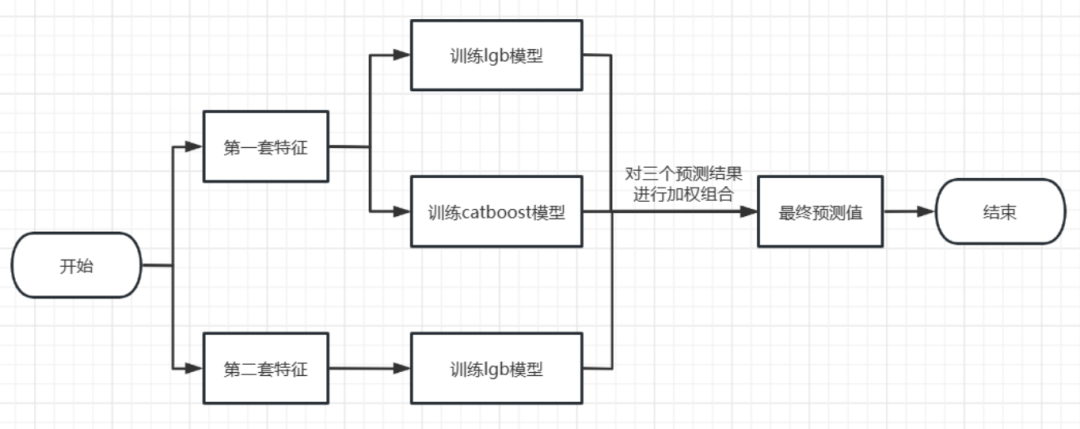
上面提到统计特征的加入会导致过拟合太严重,我们不但使用了不同的模型进行融合,还构造了两套特征。一共训练了3个模型进行融合具体流程图如下:
赛后总结
虽然该赛题为时间序列数据,但是可能是由于数据质量的问题,常规的时间序列特征在该赛题并不能有多大的提升(也有可能是我的打开方式不对😂)。
统计特征对于这个赛题确有很大的提升,虽然会导致我们的模型线下的过拟合很严重,但是我们可以通过模型的融合来缓解分数抖动过大的问题。第二套特征的构造思路也是缓解过拟合的一种非常好的方式。

整理不易,点赞三连↓

















 4594
4594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









